
AWS AutoScalingグループのインスタンスの更新時間を最適化
2022/03/20
Table of Contents
なんでそのテーマ?
AutoScalingグループに下記画像のように「インスタンスの更新」機能がありますよね。
マネジメントコンソールからポチッとするだけで、AutoScalingで管理しているEC2インスタンスが入れ替わってくれます。
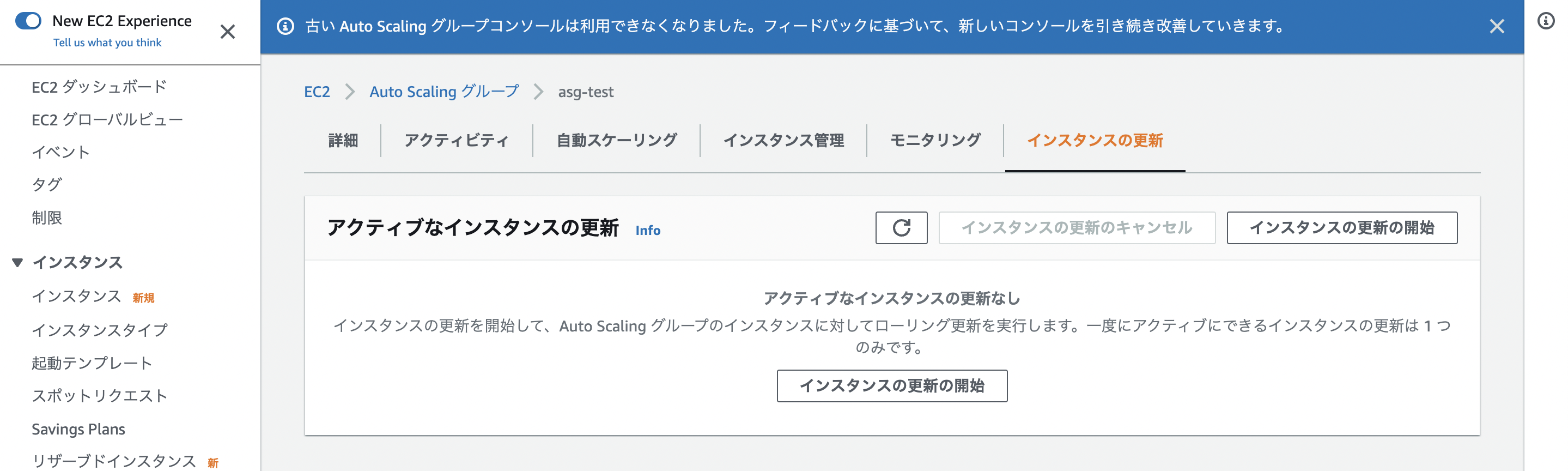
ただ、私が特に設定もいじらずに更新をすると待てど待てど終わらず。。
結局30分くらいかかりました。
さすがにインスタンスの更新に時間がかかりすぎだったので、短くしたいと思いましたが、設定値が多すぎて何をいじれば良いかわかりませんでした。
そこでどの設定値をいじれば、インスタンスの更新の全体時間を短くできるのかを共有できればと思います。
事前に知っておいたほうが良い概念
私がドキュメントを色々漁った時に、理解に苦しんだポイントが『「ELBヘルスチェック」と「AutoScalingヘルスチェック」というものがある』ということです。
- マネジメントコンソールの「ロードバランサー」画面にある「ヘルスチェック」はロードバランサーに関するヘルスチェックの設定をするもの
- マネジメントコンソールの「AutoScalingグループ」画面にある「ヘルスチェック」はAutoScalingグループに関するヘルスチェックの設定をするもの
当たり前のようなことを書いていますが、同じ言葉が何回も出てきて混乱するので、 ドキュメントで言っている「ヘルスチェック」が「何の」ヘルスチェックであるかを意識してドキュメントを読んでいくと理解が進むかもしれません。
AutoScalingグループ編
ヘルスチェックの猶予期間
まずは「ヘルスチェックの猶予期間」です。
マネジメントコンソールでは、AutoScalingグループの「詳細」タブに設定値が確認できます
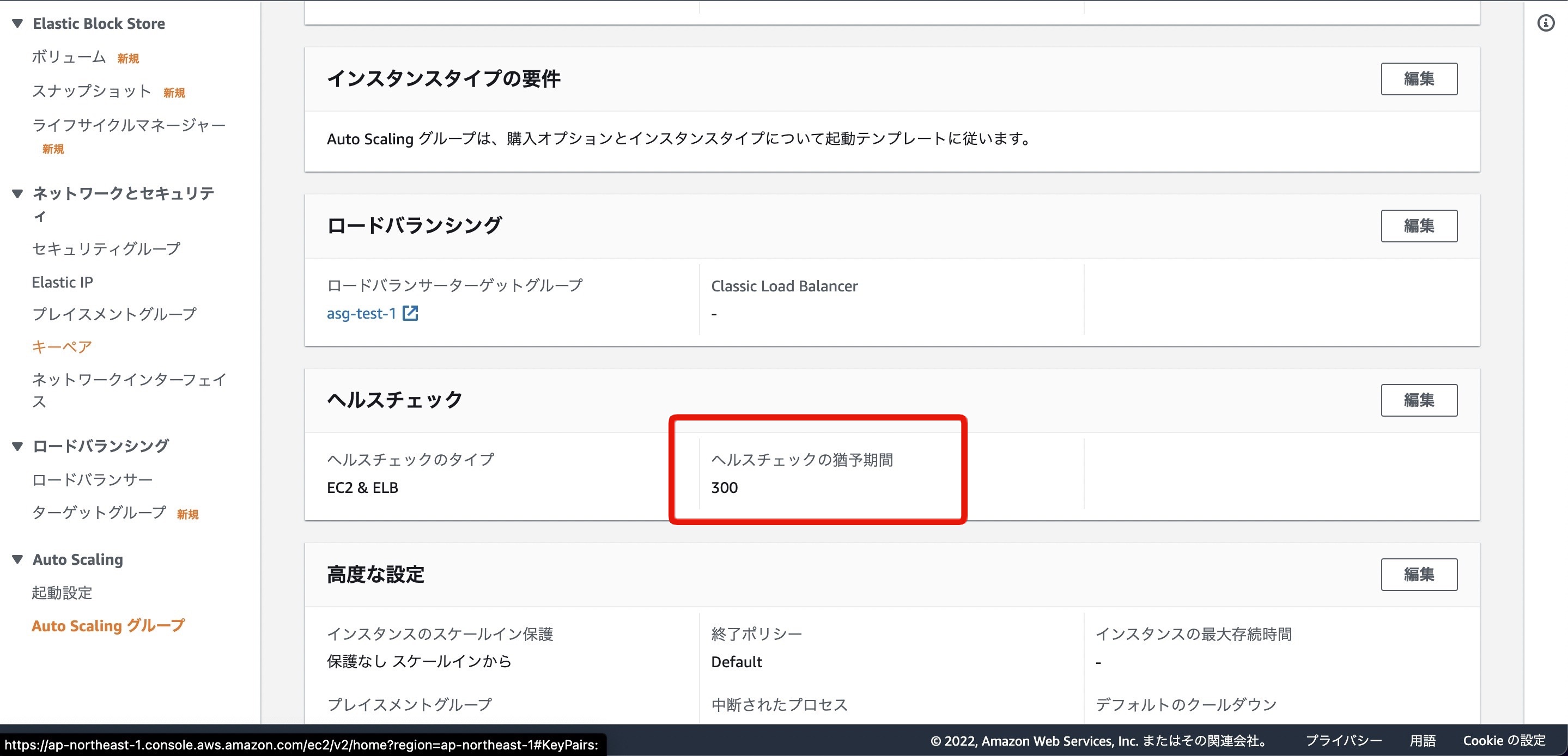
この設定値は、公式ドキュメントで以下の説明がされています。
Auto Scaling グループの HealthCheckGracePeriod パラメータを使用すると、Amazon EC2 Auto Scaling が、トラフィックを処理する準備ができていない新しく起動されたインスタンスを、異常なインスタンスと区別するのに役立ちます。この猶予期間によって、Amazon EC2 Auto Scaling がインスタンスを異常とマークし、準備する時間がないためにインスタンスを終了するのを防ぐことができます。
デフォルトでは、AWS Management Console から Auto Scaling グループを作成するときのヘルスチェックの猶予期間は、300 秒です。AWS CLI または SDK を使用して Auto Scaling グループを作成するときのデフォルト値は、0 秒です。
この値は、アプリケーションで必要な最大スタートアップ時間 (インスタンスが起動してからトラフィックを受信できるようになるまでの時間) 以上の値に設定します。ライフサイクルフックを追加する場合は、ヘルスチェックの猶予期間の値を減らすことができます。ライフサイクルフックがある場合、ヘルスチェックの猶予期間が始まるのは、ライフサイクルフックアクションが完了してインスタンスが InService 状態になってからになります。
つまり、
- インスタンスが追加される
- ELBのヘルスチェックが走る
- ASGのヘルスチェックが走る
- インスタンスの追加が完了する
という流れでインスタンスの追加がされていきますが、「3. ASGのヘルスチェックが走る」というところが始まるタイミングを「ヘルスチェックの猶予期間」で調整することができます。
「ヘルスチェックの猶予期間」の秒数が極端に長いと、ELBのヘルスチェックが正常と判断されているのにも関わらず、ASG がインスタンスをHealthyと見なさず、全体のインスタンスの更新時間が大きくかかってしまいます。
「ヘルスチェックの猶予期間」の秒数が極端に短いと、ELBのヘルスチェックがまだ済んでいないにも関わらず、ASGがインスタンスをUnHealthyと見なし、再度インスタンスの削除、追加を繰り返し、インスタンスの更新が終わらなくなってしまいます。
適正値としては、「ELBのヘルスチェックがちょうど終わるタイミングの秒数」を設定すると良いかと思います。
最小正常率
次に最小正常率です。
AutoScalingグループの「インスタンスの更新」 > 「インスタンスの更新の開始」を押した時に下記の画像のように出てきます
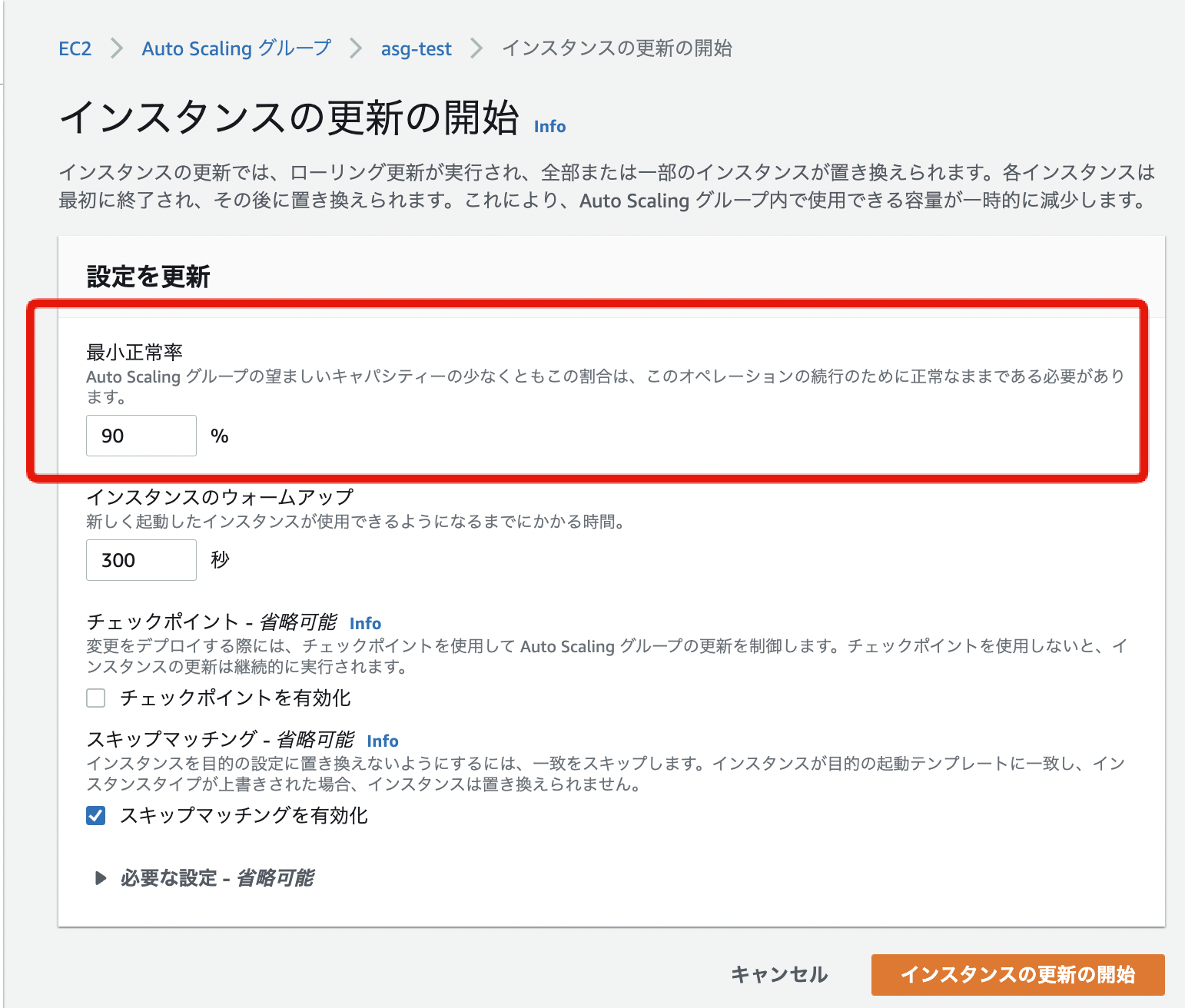
この設定値は、公式ドキュメントで以下の説明がされています。
インスタンスの更新の開始のパートとして、常に維持する最小正常率を指定します。これは、インスタンス更新中にヘルスチェックに合格しなければならない、Auto Scaling グループのキャパシティーで、オペレーションを続行できるようにします。この値は、Auto Scaling グループの望ましいキャパシティーに対するパーセント値(最も近い整数値に切り上げ)で表されます。最小正常率を 100% に設定すると、置き換え率が一度に 1 つのインスタンスに制限されます。対照的に、0% に設定すると、すべてのインスタンスが同時に置き換えられます。
これは名前の通りわかりやすいですが、要は「インスタンスの更新中は、何台最小で稼働させておきますか?」という設定値です。
もし、ダウンタイムが発生しても良いのであれば、「0%」を設定することで一気にインスタンスが入れ替わり始めます。さらにインスタンスの更新全体の時間も短いです。
ダウンタイムを発生させたくないのであれば、そのパーセンテージを設定したら良いです。
ただ一気に入れ替わるよりも時間がかかります。
例えば現在10台のEC2インスタンスがあり、
- 最小正常率90% : 1台削除、1台追加の開始 → 処理完了 → 1台削除、1台追加の開始 ... → 全部置き換わったらインスタンスの更新完了
- 最小正常率50% : 5台削除、5台追加の開始 → 処理完了 → 5台削除、5台追加の開始 → インスタンスの更新完了
- 最小正常率0% : 10台削除、10台追加の開始 → 処理完了 → インスタンスの更新完了
といったステップで進みます。最小正常率0%がステップが少ないので時間が短いです。
この設定値は、インスタンスの更新中の想定される負荷によって調整するのが良いかと思います。
インスタンスのウォームアップ
次は、インスタンスのウォームアップです。
最小正常率と同様の画面に設定値が存在します
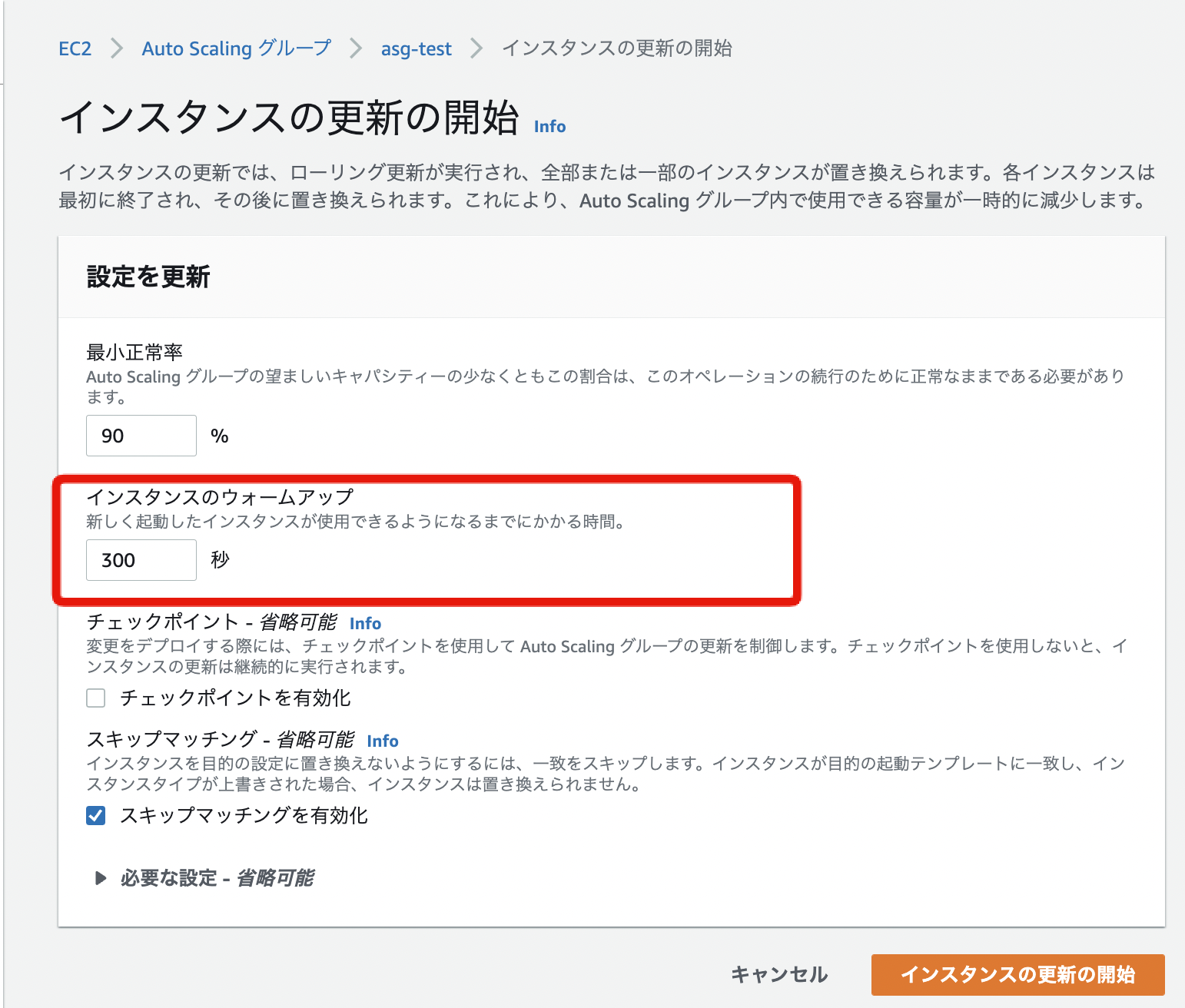
この設定値は、公式ドキュメントで以下の説明がされています。
インスタンスのウォームアップは、新しいインスタンスがサービスを開始してからトラフィックを受信できるようになるまでの期間です。インスタンスの更新中、新しく起動されたインスタンスが正常であると判断した後、 Amazon EC2 Auto Scaling はすぐに次の置き換えに進みません。指定したウォームアップ期間を待ってから、他のインスタンスの置き換えに移ります。この設定は、実行するのに時間がかかる設定スクリプトがある場合に役立ちます。
これはASGのヘルスチェックがHealthyとなった後に、次のEC2インスタンスを更新し始めるまでの時間を指定できるものです。
上記の説明に書いてあるように「実行するのに時間がかかる設定スクリプトがある場合に役立ちます」とのことです。
ここからの言及は実際にためしてないので、たぶん,,といった話ですが、
「インスタンスのウォームアップは、新しいインスタンスがサービスを開始してからトラフィックを受信できるようになるまでの期間です」とありますが、ここで設定した秒数の期間中トラフィックがEC2に流れないというわけではない気がします。
というのも、その機能はELBターゲットグループの設定にある「スロースタートモード」で設定する部分があるからです。
ここでの「インスタンスのウォームアップ」の設定秒数はあくまで、次のEC2インスタンスの更新が始まるとまずい場合に設定するのではないかと思っています。
(調べきれてないので、ご自身で確認いただけますと幸いです。)
私の場合は、ELBでのヘルスチェックが通れば問題なかったため、「0秒」にすることで全体のインスタンス更新時間を早めました。
ロードバランサー(ターゲットグループ)編
ヘルスチェック(ターゲットグループ)
次はターゲットグループのヘルスチェックになります。
下記の画像にあるように ターゲットグループ > ヘルスチェック の画面で設定を変更できます
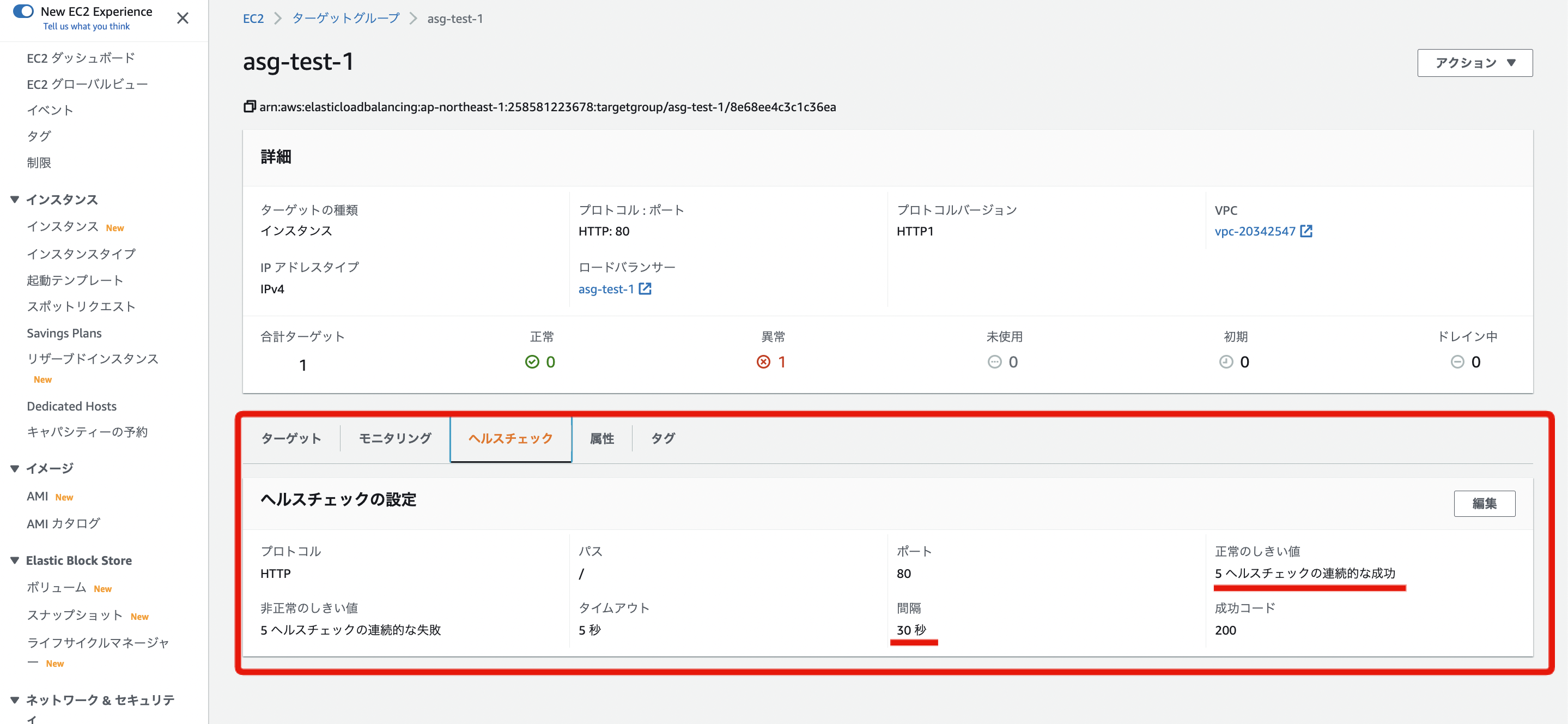
ここで全体のインスタンス更新時間を早めるために調整するべき値としては、「正常のしきい値」と「間隔」になります。
ヘルスチェック(ターゲットグループ) > 正常のしきい値
「正常のしきい値」は、文字の如く「何回ヘルスチェックが成功したらHealthyとみなすか」の設定値です。
上記の画像で言えば、「5 ヘルスチェックの連続的な成功」とあるので、5回ヘルスチェックが通ったらHealthyとなります。
これをあまりに多い回数にしてしまうと、ヘルスチェックに時間がかかりすぎて、全体のインスタンス更新の時間が大きくかかってきます。
ヘルスチェック(ターゲットグループ) > 間隔
「間隔」はこれも読んで字の如く、「1回1回のヘルスチェックは何秒ごとに送りますか?」という設定値です。
これを5分とかにしてしまうと、Healthyと認められるまでかなり時間がかかってしまいます。
例えば正常のしきい値を「10回」に設定し、間隔を「60秒」に設定してしまうと、Healthyと認定されるのに、 10回 × 60秒 = 600秒(5分) がかかってしまいます。
さらに、10台のEC2インスタンスを最小正常率 90%でやってしまうと、このELBヘルスチェックだけで全部で50分かかっちゃいます。
長すぎですね,,,
属性(ターゲットグループ)
登録解除の遅延
次は、ターゲットグループの「登録解除の遅延」の値です。
下記の画像にあるように ターゲットグループ > 属性 の画面で設定を変更できます
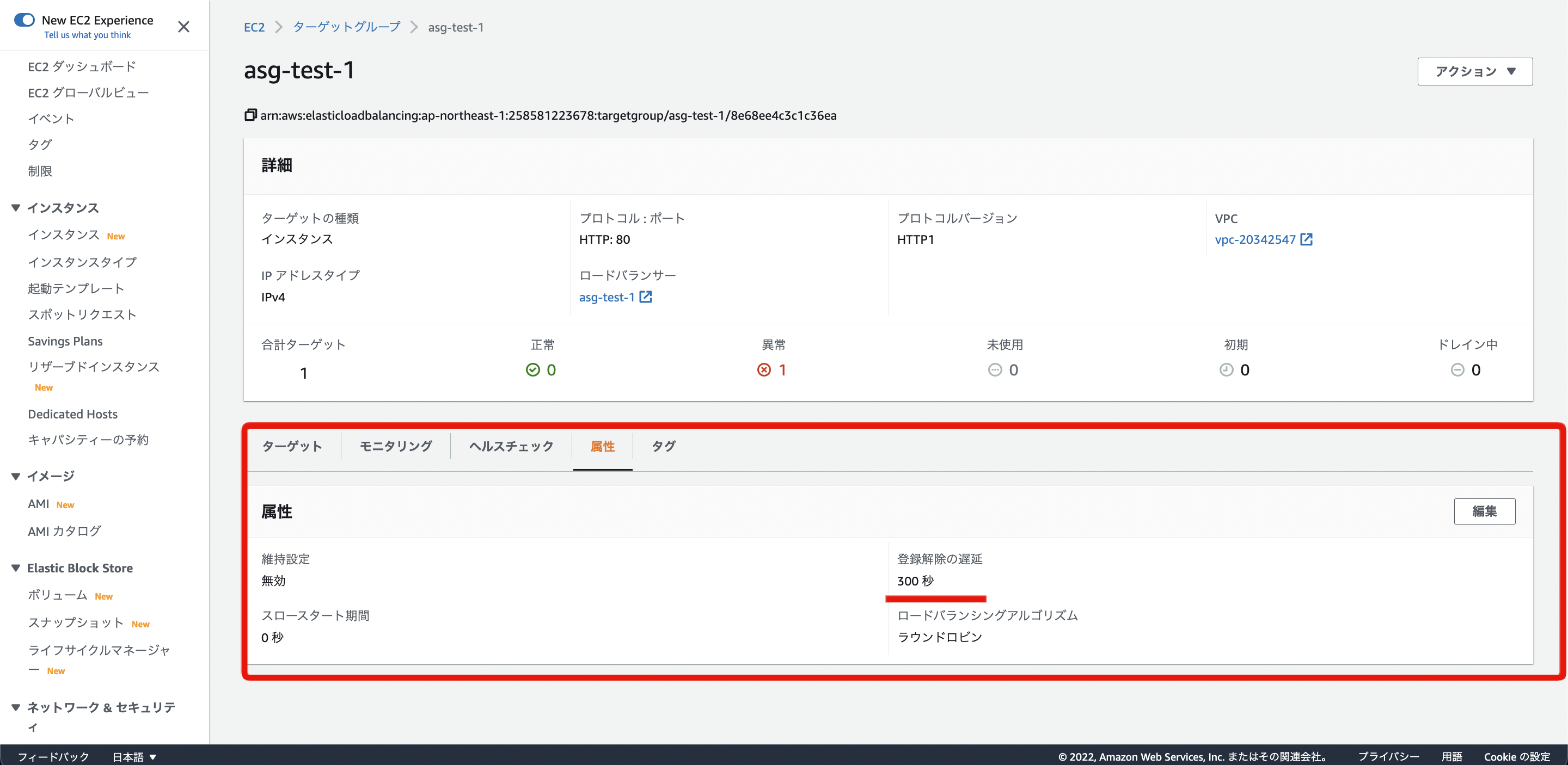
この設定値は、公式ドキュメントで以下の説明がされています。
Elastic Load Balancing は、登録解除するターゲットへのリクエストの送信を停止します。デフォルトでは、Elastic Load Balancing 登録解除プロセスを完了する前に 300 秒待って、ターゲットへ処理中のリクエストが完了するのを助けることができます。Elastic Load Balancing が待機する時間を変更するには、登録解除の遅延値を更新します。
登録解除するターゲットの初期状態は draining です。登録解除の遅延が経過すると、登録解除プロセスは完了し、ターゲットの状態は unused になります。ターゲットが Auto Scaling グループの一部である場合、ターゲットを終了して置き換えることができます。
登録解除するターゲットに未処理のリクエストやアクティブな接続がない場合は、Elastic Load Balancing は登録解除の遅延時間が経過するのを待たずに、即時登録解除プロセスを完了します。ただし、ターゲットの登録解除が完了しても、ターゲットのステータスは、登録解除の遅延タイムアウトの期限が切れるまで draining と表示されます。タイムアウトの期限が切れると、ターゲットは unused 状態に移行します。
登録解除の遅延が経過する前に登録解除するターゲットが接続を終了すると、クライアントは 500 レベルのエラー応答を受信します。
要するに、「登録解除の遅延」の秒数を設定することで、インスタンス削除実施時にELBからすぐにインスタンスを切り離さず、残っているEC2内の処理を設定した秒数の間でこなさせることができます。
ただ必要以上に長く設定してしまうとなかなかEC2がALBから切り離されず(つまりは削除されず)、全体のインスタンス更新時間が長くなってしまう可能性があります。
なので必要最低限の秒数で設定しておくのが良いかと思います。
例えば、EC2内で動いているApacheやNginxのTTLが60秒であれば、「登録解除の遅延」の秒数も60秒に設定するのが良いのではないでしょうか。
まとめ
いかがだったでしょうか。
これらの値を調整することによって、インスタンス更新期間を適切な実施時間内で収めることができるようになるかと思います。
一回一回試すのに、かなり時間を費やすところでもあるので、ぶつかっている方が参考になれば幸いです。

山下達也
AWS / Ruby / Rails あたりをやってます。