
Table of Contents
SimSwapの立ち位置
SimSwapとは、ソース画像と対象画像が与えられた時、対象の顔の属性(表情など)を変更せずにソースの顔の個性を対象の顔に写すフレームワークです。
過去の研究として、顔すり替え手法には、画像レベルで対象の顔を扱うソース指向の手法と、特徴量レベルで対象の顔を扱う対象指向の手法があります。ソース指向の手法は、表情や姿勢などの属性を対象の顔からソースの顔へ転写し、その後、転写されたソースの顔を対象の顔にブレンドすることで顔をすり替えています。この手法は、ソース画像の姿勢や照明の影響を受けやすく、すり替え対象の表情を正確に再現することができないという欠点があります。対象指向の手法は、対象画像の特徴をソース画像に似るように修正するので、ソースの顔のバリエーションに上手く対応できないという欠点があります。他にもIDに特化した顔すり替え手法では、特定のID(ソース情報)に限定してすり替えを行うため汎化性にかけていたり、GANベースの手法ではソースの顔情報を残すため、対象画像の表情などの属性情報を保持できていない場合が多々あります。
そこで、論文の著者は、ID(ソース情報)に特化した顔すり替え手法のアーキテクチャを分析し、デコーダ部分にID情報が統合されているため汎化性が欠如していることを発見しました。SimSwapでは、この統合を避けるためID注入モジュールを提案しています。また、IDと属性の情報が特徴量レベルで結びついていており、特徴量レベルで変更した場合性能が劣化することから、それを緩和する弱特徴マッチング損失を提案しています。上記の手法を用いることで、SimSwapは、競争力のあるID(ソース情報)の転写性能を実現し、従来の手法より優れた属性保持能力を持つことができています。
提案手法
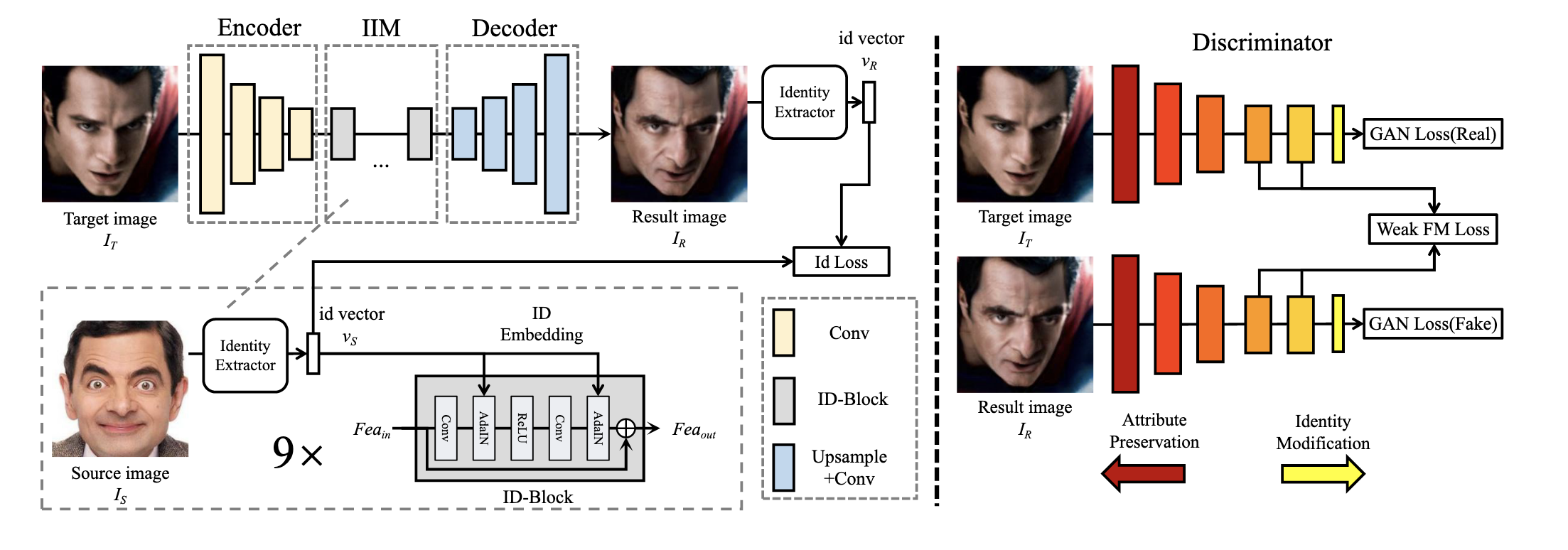
上図(論文 Figure 2)はSimSwapのアーキテクチャです。簡単に説明すると、
- 対象画像が与えられたら、Encoderを通して特徴量を抽出 (Encoder)
- の属性情報部分は残し、ID情報の部分のみソース画像の情報に入れ替える (IIM; ID Injection Module)
- Decoderで結果画像を再構成する
と、Discriminatorで構成されています。
ID注入部 (IIM)とGenerator損失について
2のIIMの部分は、特徴量において、属性情報とID情報が密結合しているので、ID情報のみのすり替えが課題となります。そこで、IIMでは、学習損失を利用して、ネットワークにのどの部分を変更し、どの部分を修正すべきかを暗黙的に学習させることで、全体の修正を行いソース画像のID注入を達成しています。
このIIMはID抽出部(ID Extractor)とID埋め込み部(ID Embedding)の2つで構成されています。ID抽出部は、顔認識ネットワークを用いて、ソース画像からIDベクトルを抽出しています。ID埋め込み部(ID-Block)では、Residual Blockの改良版で、Batch Normalizationの部分をAdaptive Instance Normalization (AdaIN)に変更しています。また、十分なID埋め込みを達成するため9個のID-Blockを使用しています。
AdaINは、以下の式で表されます。
)とは に対するチャンネル単位の平均と標準分散です。とは、から全結合層を使用して生成される値です。
IIMのあとは、IIMを通過した特徴量からDecoderによりを再構成し、ID抽出によりIDベクトルを取得します。得られた情報を用い、このGenerator部分では、以下の2つ損失が計算できます。
- Identity Loss
- 再構成Loss
Discriminator
顔の入れ替えタスクでは、ID情報のみ修正し、対象の顔属性(表情、位置、照明など)の情報は変更しないことが良いとされます。しかし、上記のようにIIM部分でを直接修正しているため、ID情報の埋め込みにより属性情報が影響をうける可能性は大きいです。そこで、Feature Matching Loss (FML)という学習損失を用いて、制約をかけることで、属性の不一致を防いでいます。オリジナルのFMLは、pix2pixHDという手法にて導入され、Discriminatorを用いて画像の特徴を抽出し、比較しています。SimSwapでは、少し修正し、最初のいくつかのレイヤーに関しては無視した形で特徴を抽出し、比較しており、これをWeak Feature Matching Loss(wFM)としています。式は以下の通りです。
ここで、は、Discriminator ()のi番目の特徴抽出レイヤーを示しています。はそのレイヤーの要素数です。は、使用するレイヤー数です。
Disciminatorでは、wFMに加え、一般的なGANの損失であるRealとFakeを見分けるHinge バージョンのAdversarial Loss ()が用いられています。
# Hinge Loss
lossD = F.relu(1.0 - y_real).mean() + F.relu(1.0 + y_fake).mean()
損失
最終的に損失は、それぞれの重みと掛け合わせて以下のようになります。学習の安定のため、Gradient Penalty()も導入されています。 また、wFMでは、Multi Scale Descriminatorを導入し、高解像画像の学習を効率化しています。例えば、, では、1, 1/2倍スケールの画像を入力としたDiscriminatorとなる。
まとめ
SimSwapの実験結果の例は、以下の図のようになりました。また、実験結果としてIDの注入が上手くできている指標が得られています。違和感なくすり替えれらており、恐ろしくも感じます。
SimSwapでは、IDをどう扱うかといることを損失の設計で解決しており、他のGANでも有効な手法な気がしています。また、Hinge LossやGPなど学習の安定化のための手法が、一般的に使われており、今後、GANの実装には積極的に取り入れていきたい所です。

Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps