
こんにちは、機械学習チームの石橋です
自分はVision and Languageに関連することをここ1年ほど扱ってきたのですが、Image Captioningの最近はどうなん?とふとおもって調べてみるとOFAなるものが公開されていました。
githubのリポジトリをみてみるとImage CaptioningだけでなくVQAなどもこのモデルで行うことができるいわゆるマルチモーダルなモデルです。
今回はImage Captioningに注目してみます。
以前に弊社インターンの青木くんがImage Captioningを日本語で行うモデルを開発してくれましたがその出力とも比較をしてみようと思います(OFAは英語出力で、青木くんのモデルは日本語とデータセットやドメインが違うので単純比較はできませんが、参考程度に)

デモ
test.1
ありがたいことにhugging faceで推論を試す環境が出来上がっていました

まずは、この画像を試してみます

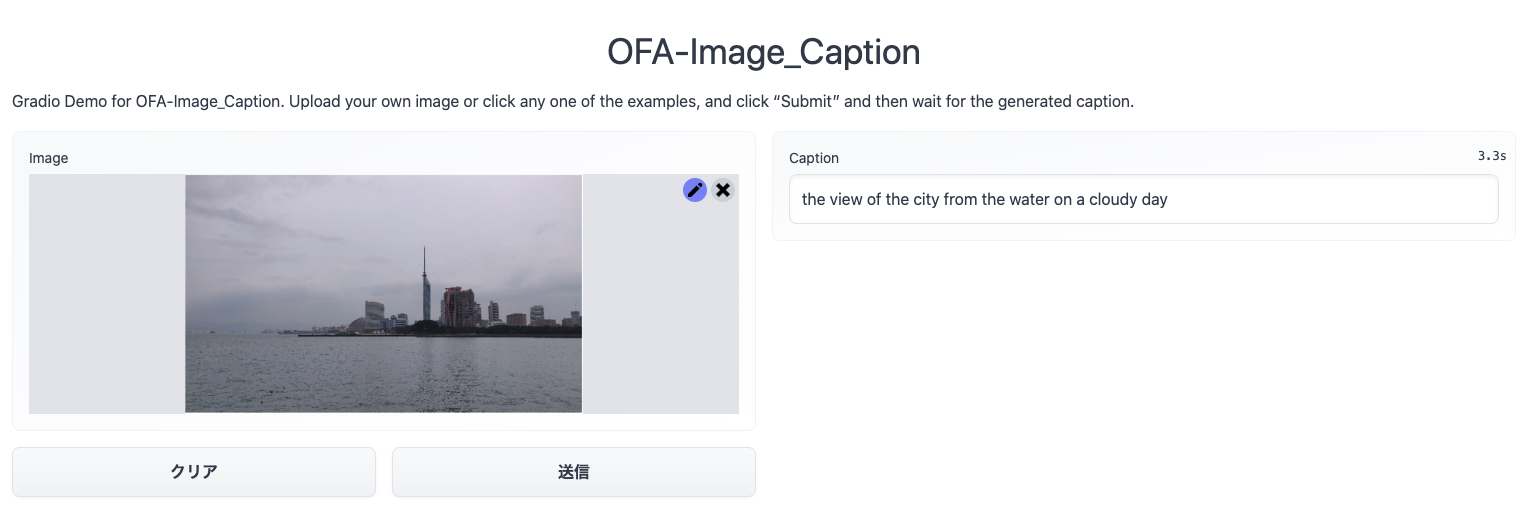
OFAの出力「the view of the city from the water on a cloudy day」
google 翻訳結果 「曇りの日の水からの街の眺め」
文面から見るに、OFAは海であるとは判断しなかったところは相違点の一つですね。
また天気が曇りであることを文章に含めていることも相違点ですね。
test.2
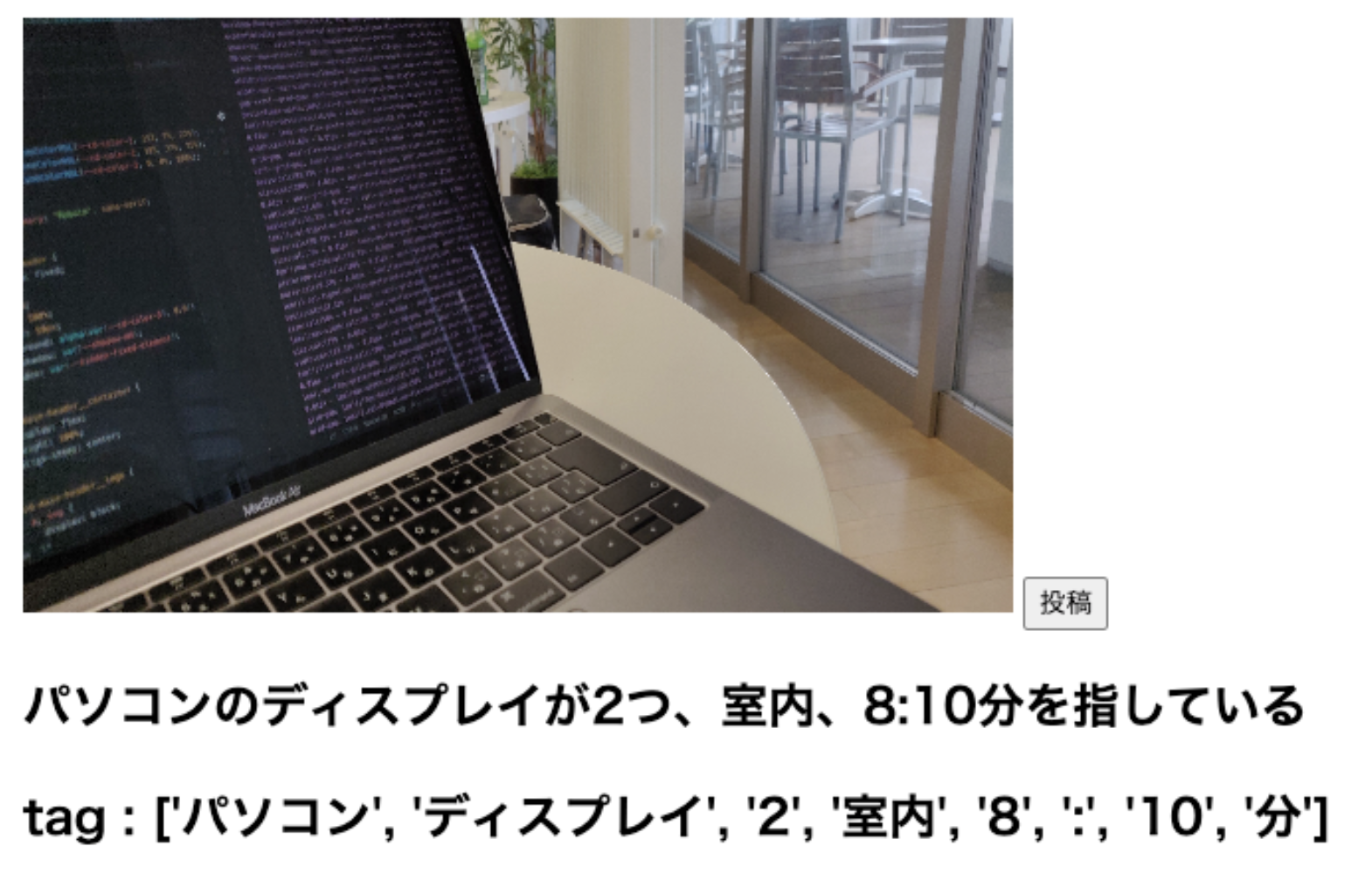
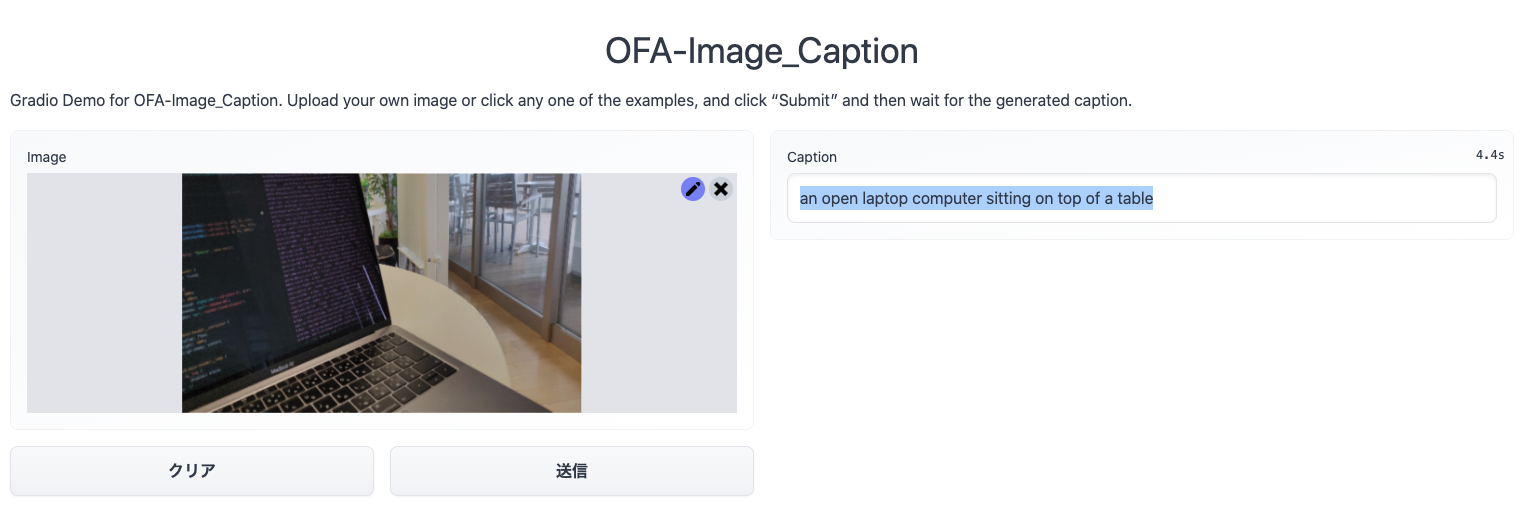
OFAの出力「an open laptop computer sitting on top of a table」
google 翻訳結果 「テーブルの上に座っているオープンラップトップコンピュータ」
これはOFAの方がより正確に状況を把握できている感じがしますね
test.3

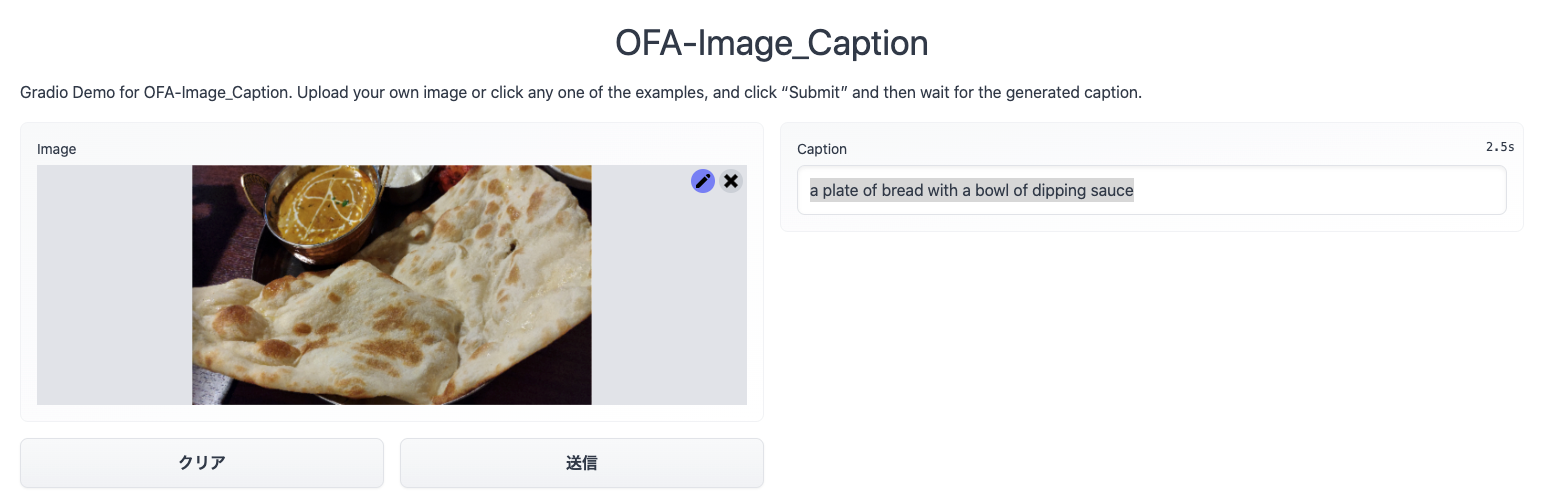
OFAの出力「a plate of bread with a bowl of dipping sauce」
google 翻訳結果 「パンのプレートとディップソースのボウル」
どちらもナンのことをパンと呼んでいるのが興味深いですね。
おそらくデータセットにナンが無いのでしょう。
感想
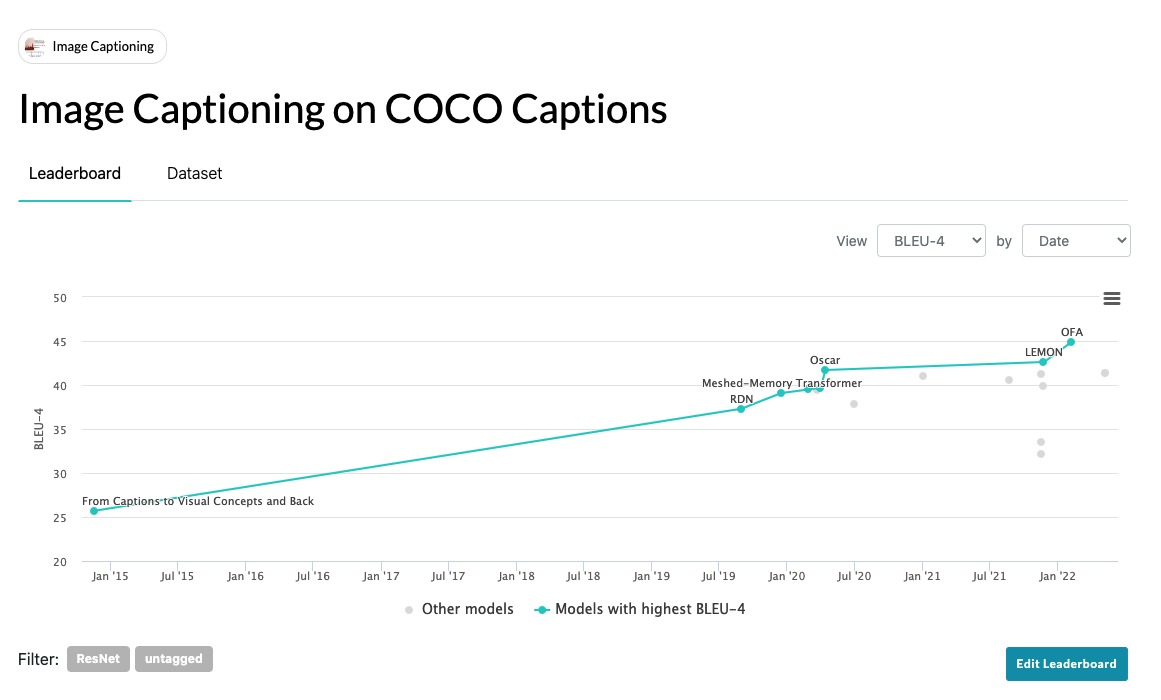
今回は、Image Captioningの現在SoTAのOFAを試して、過去にImage Captioningを試した時の結果と比較してみました。
若干条件に差はあるものの、OFAは明らかに関係の無い言葉は出てきにくいのかなという印象がありますね。
どんな秘密が中にあるのか、この後論文を読んでみようと思います

Ryu Ishibashi
機械学習/Vue/React/Laravelとかやってます