
機械学習チームでインターンをしています橋口です。
今回、BERTにVATを適用したQAタスクを実装したので、記事としてまとめました。
QAタスク
QAタスクは質問に対して解答するタスクです。 そのQAタスクの中でも選択式のQAタスクは、質問文に対してどの選択肢が尤もらしいかを判定するタスクとして研究が行われています。
今回は、常識的な問題を対象に選択式のQAタスクに取り組みました。
JGLUE
JGLUEは2022年3月の言語処理学会第28回年次大会にて言語資源賞を獲得したベンチマークです。 このベンチマークは、文章分類タスクのデータセットである「MARC-ja」、文ペア分類タスクとして意味的類似度計算データセットの「JSTS」および自然言語推論データセットの「JNLI」、QAタスクとして機械読解タスクのデータセットである「JSQuAD」および常識推論能力を評価するための5択QAタスクのデータセットである「JCommonsenseQA」の5種類のデータセットが含まれています。
今回は、JCommonsenseQAを使って実装を行いました。 JCommonsenseQAには以下のような質問文と選択肢が含まれています。 正解の選択肢は赤字で示しています。

JGLUEのデータセットは以下のリンクからダウンロードできます。
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、2018年Googleが開発した大規模な汎用言語モデルで、Transformerのエンコーダをベースとして開発されたモデルです。 BERTは様々なNLPタスクに適用でき、11個のNLPタスクでSoTAを達成しました。 特徴としては、事前に学習されたBERTモデルを手持ちのデータセットでファインチューニングすることで、高い精度を達成できる点です。 自然言語処理ではhuggingface(https://huggingface.co)に多くのタスクで利用できる事前学習済みモデルが格納されており、本実験でもhuggingfaceで公開されているモデルを使用しました。
今回選択式のQAタスクを実装しますが、BERTは以下のように質問文、選択肢をBERTに入力して、各選択肢に対してスコアを出力し、一番スコアが大きいものを正解とするように学習を行います。 ここで、[CLS]は入力の先頭を表すトークン、[SEP]は入力の区切りを表すトークンとなっています。
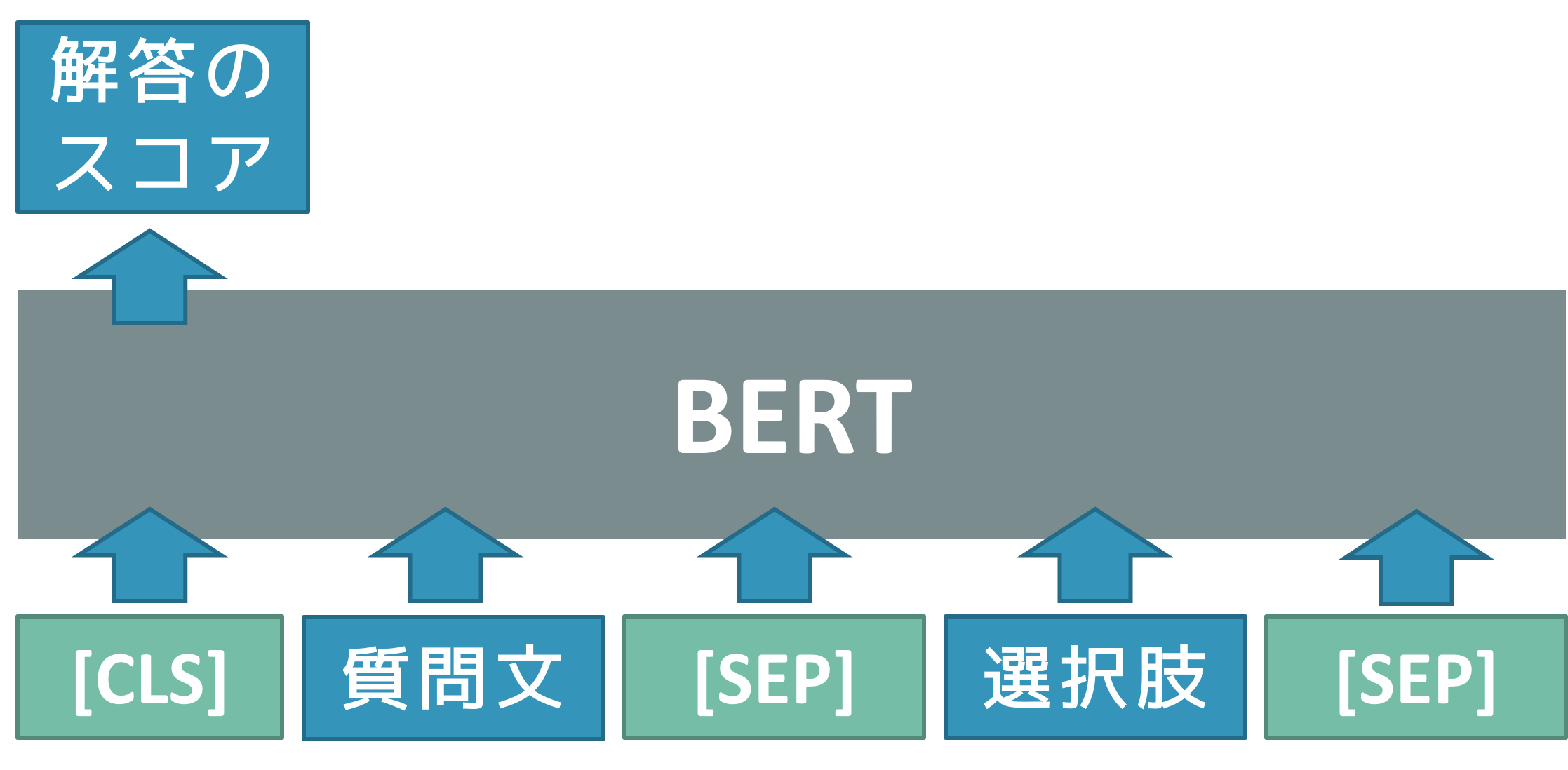
BERTの詳細は元の論文、あるいは日本語でBERT論文を解説したQiita記事から参照してください。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
VAT
VAT(Virtual Adversarial Training)は、入力に微小な摂動(ノイズ)を加え、 KLダイバージェンスや二乗誤差などを用いて損失を最小化するように学習します。 これにより、摂動が含まれるデータに対して頑健となり、分類タスクにて正解率が向上することが知られています。 一般的に、摂動を用いた学習法は画像処理の分野で多く用いられていますが、 自然言語理解やQAタスクの自然言語分野でも有効性が確認されています。以下にその論文を示します。
実装
実装環境としてGoogle Colabを使用しました。
1. ライブラリのインポート
必要なライブラリをインポートします。
# ライブラリのインポート
!pip install ipadic
!pip install datasets
!pip install pandas
!pip install numpy
!pip install transformers
!pip install sklearn
!pip install fugashi
!pip install unidic-lite
!pip install tqdm
!pip install matplotlib
!pip install accelerate2. JGLUEをclone
日本語言語理解ベンチマーク「JGLUE」をcloneします。
# JGLUEをCloneする
!git clone "https://github.com/yahoojapan/JGLUE.git"3. JCommonsenseQAの読み込み
今回使用するデータセット「JCommonsenseQA」を読み込みます。(データセットのバージョンが変更されている可能性があるため、各々で変更してください。)
from datasets import load_dataset
import pandas as pd
# JCommonsenseQAの読み込み
dataset = load_dataset('json', data_files={
'train': '/content/JGLUE/datasets/jcommonsenseqa-v1.1/train-v1.1.json',
'valid': '/content/JGLUE/datasets/jcommonsenseqa-v1.1/valid-v1.1.json',
})
# dict -> dataframe
train_df = pd.DataFrame.from_dict(dataset["train"])
val_df = pd.DataFrame.from_dict(dataset["valid"])
all_df = pd.concat([train_df, val_df], ignore_index=True, axis=0)4. 質問文のトークン列の確認
今回は、東北大の事前学習済みBERTモデルでトークン化を行います。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v2")質問文をトークン化したときに、BERTモデルの最大入力トークン数512を超えていないか可視化します。
from tqdm import tqdm
import matplotlib.pyplot as plt
tqdm.pandas()
# 本文の文字数を確認する
all_df['question_len'] = all_df['question'].progress_apply(lambda x: len(tokenizer.tokenize(x)))
# 質問文の長さを可視化
plt.title('question length')
all_df['question_len'].hist(bins=100)
plt.plot([512, 512], [0, 700])
print('質問文の長さが512以内のデータ割合', all_df.query('question_len <= 512').shape[0] / all_df.shape[0])
print('質問文の最大長さ', all_df['question_len'].max())出力結果は以下のようになっており、全ての質問文のトークン数は512以下となっています。
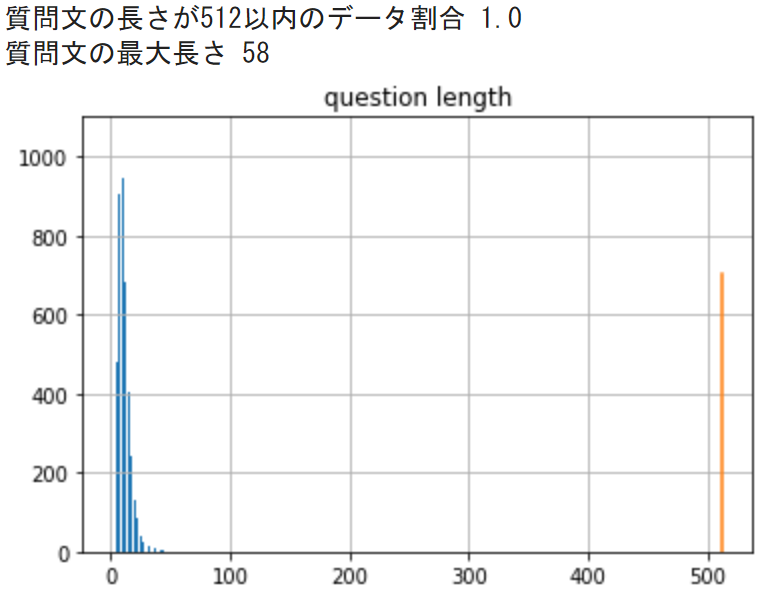
今回、全ての質問文のトークン数は512以下となりましたが、他のデータセットでトークン数が512を超える場合は、以下のRoBERTaモデルを使用するとよいでしょう。
5. 前処理
BERTモデルにデータを入力するために、データの前処理を行います。
def preprocess_function(examples):
context_name = "question"
ending_names = [f"choice{i}" for i in range(5)]
max_seq_length = 64
first_sentences = [[context] * 5 for context in examples[context_name]]
second_sentences = [
[f"{examples[end][i]}" for end in ending_names] for i in range(len(examples[context_name]))
]
# Flatten out
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
# Tokenize
tokenized_examples = tokenizer(
first_sentences,
second_sentences,
truncation=True,
max_length=max_seq_length,
padding="max_length"
)
# Un-flatten
return {k: [v[i:i+5] for i in range(0, len(v), 5)] for k, v in tokenized_examples.items()}
data = preprocess_function(all_df)BERTに入力するトークンIDの配列「input_ids」、文を判別するバイナリマスク「token_type_ids」、埋め込みを判別するバイナリマスク「attention_mask」の3つのデータをTensor型に変換します。また、正解データに関してもTensor型に変換します。
import torch
# リストに入ったtensorを縦方向(dim=0)へ結合
tensor_input_ids = torch.tensor(data["input_ids"])
tensor_token_type_ids = torch.tensor(data["token_type_ids"])
tensor_attention_masks = torch.tensor(data["attention_mask"])
# 正解データの取得
labels = all_df["label"].to_list()
tensor_labels = torch.tensor(labels)データセットの作成を行います。今回、colabのGPUのメモリが16GBと少ないため、全ての学習データで学習できません。そのため、訓練データに関しては全体の28%のデータのみを使用しました。 また、バッチサイズは4としました。
import numpy as np
from torch.utils.data import TensorDataset, Subset
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# データセットクラスの作成
dataset = TensorDataset(tensor_input_ids, tensor_token_type_ids, tensor_attention_masks, tensor_labels)
indices = np.arange(len(dataset))
# 訓練データ、評価データ
train_dataset = Subset(dataset, indices[:int(len(train_df)*0.28)])
val_dataset = Subset(dataset, indices[-len(val_df):])
# データローダーの作成
batch_size = 4
# 訓練データローダー
train_dataloader = DataLoader(
train_dataset,
sampler=RandomSampler(train_dataset), # ランダムにデータを取得してバッチ化
batch_size=batch_size
)
# 検証データローダー
validation_dataloader = DataLoader(
val_dataset,
sampler=SequentialSampler(val_dataset), # 順番にデータを取得してバッチ化
batch_size=batch_size
)モデルは東北大学が開発した事前学習済みBERTモデルを使用します。 JCommonsenseQAは選択肢が5つ与えられているので、ラベル数は5と設定します。
from transformers import AutoModelForMultipleChoice
model = AutoModelForMultipleChoice.from_pretrained(
"cl-tohoku/bert-base-japanese-v2", #日本語Pretrainedモデルの指定
num_labels = 5,
output_attentions = False, #アテンションベクトルを出力するか
output_hidden_states = False, #隠れ層を出力するか
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)モデルの保存先を指定します。
import os
MODEL_PATH = "model_dir/"
if not os.path.exists(MODEL_PATH):
os.mkdir(MODEL_PATH)6. モデルの学習
VATの実装を行います。 今回は以下のコードを参考にプログラムを作成しました。
今回BERTにVATを適用させたときのイメージ図としては以下のようになっています。
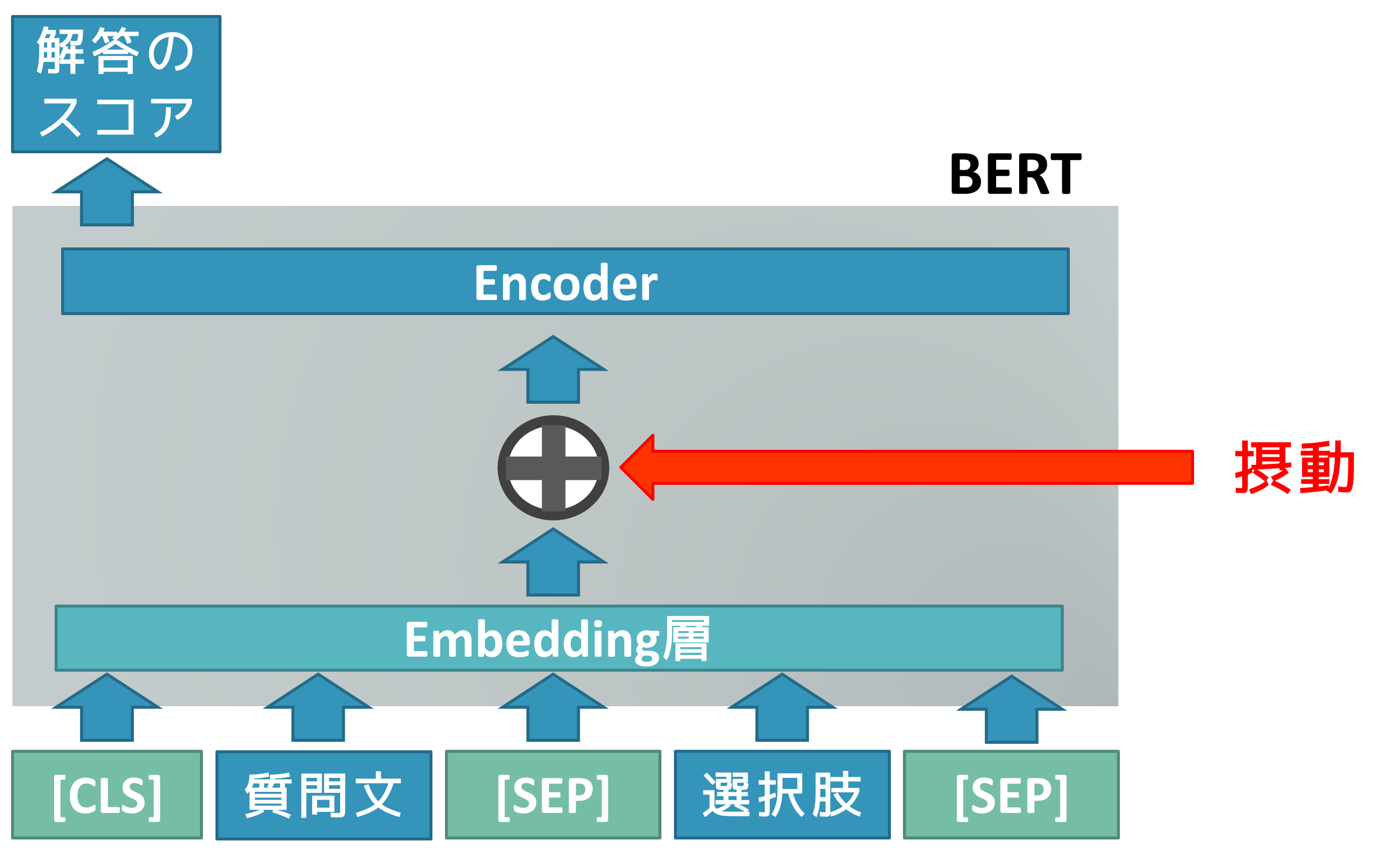
上記の図から、BERTモデルはEmbedding層があるため、入力に直接摂動を加えることができません(Embedding層にはトークンIDを入力するため、摂動を加えるとトークンIDが変化しベクトル化できません)。 そのため、トークン列をEmbedding層に入力し、その出力に摂動を加えるようにプログラムを作る必要があります。
import torch
import contextlib
import torch.nn as nn
import torch.nn.functional as F
#####################################################################################
@contextlib.contextmanager
def _disable_tracking_bn_stats(model):
def switch_attr(m):
if hasattr(m, 'track_running_stats'):
m.track_running_stats ^= True
model.apply(switch_attr)
yield
model.apply(switch_attr)
#####################################################################################
# 摂動を用意
def _l2_normalize(d):
d_reshaped = d.view(d.shape[0], -1, *(1 for _ in range(d.dim() - 2)))
d /= torch.norm(d_reshaped, dim=1, keepdim=True) + 1e-8
return d
#####################################################################################
class VATLoss(nn.Module):
def __init__(self, xi=10.0, eps=1.0, ip=1):
"""VAT loss
:param xi: hyperparameter of VAT (default: 10.0)
:param eps: hyperparameter of VAT (default: 1.0)
:param ip: iteration times of computing adv noise (default: 1)
"""
super(VATLoss, self).__init__()
self.xi = xi
self.eps = eps
self.ip = ip
def forward(self, model, input, back=True):
with torch.no_grad():
x = input[0]
b_token_type_ids = input[1]
b_input_mask = input[2]
outputs = model(x, token_type_ids=b_token_type_ids, attention_mask=b_input_mask)
pred = F.softmax(outputs.logits, dim=1)
# prepare random unit tensor
d = torch.rand(x.size(0)*x.size(1), x.size(2), 768).sub(0.5).to(x.device)
d = _l2_normalize(d)
with _disable_tracking_bn_stats(model):
# calc adversarial direction
for _ in range(self.ip):
d.requires_grad_()
# Prepare data
x = x.view(-1, x.size(-1))
b_input_mask = b_input_mask.view(-1, b_input_mask.size(-1))
b_token_type_ids = b_token_type_ids.view(-1, b_token_type_ids.size(-1))
# Embeddings
embed = model.bert.embeddings(x, token_type_ids=b_token_type_ids)
# Encoder
encode_output = model.bert.encoder(embed + self.xi * d, encoder_attention_mask=b_input_mask)
# Pooler
pooler_output = model.bert.pooler(encode_output["last_hidden_state"])
# Dropout
dropout_outout = model.dropout(pooler_output)
# Linear
logits = model.classifier(dropout_outout)
eshaped_logits = logits.view(-1, 5)
# Log_Softmax
logp_hat = F.log_softmax(eshaped_logits, dim=1)
# KL-divergence
adv_distance = F.kl_div(logp_hat, pred, reduction='batchmean')
if back == True:
adv_distance.backward()
d = _l2_normalize(d.grad)
model.zero_grad()
# calc LDS
d.requires_grad_()
# Prepare data
x = x.view(-1, x.size(-1))
b_input_mask = b_input_mask.view(-1, b_input_mask.size(-1))
b_token_type_ids = b_token_type_ids.view(-1, b_token_type_ids.size(-1))
# Embeddings
embed = model.bert.embeddings(x, token_type_ids=b_token_type_ids)
r_adv = d * self.eps
encode_output = model.bert.encoder(embed + r_adv, encoder_attention_mask=b_input_mask)
pooler_output = model.bert.pooler(encode_output["last_hidden_state"])
# Dropout
dropout_outout = model.dropout(pooler_output)
# Linear
logits = model.classifier(dropout_outout)
eshaped_logits = logits.view(-1, 5)
logp_hat = F.log_softmax(eshaped_logits, dim=1)
lds = F.kl_div(logp_hat, pred, reduction='batchmean')
return ldsBERTの学習・評価用のコードを作成します。
from torch.nn import functional as F
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-05)
# 訓練パートの定義
def func_train(epoch, model):
model.train() # 訓練モードで実行
train_loss = 0
loss_list = []
for iter, batch in enumerate(tqdm(train_dataloader)):
# 単語ID, Attention Mask, 正解データ
b_input_ids = batch[0].to(device)
b_token_type_ids = batch[1].to(device)
b_input_mask = batch[2].to(device)
b_labels = batch[3].to(device)
vat_loss = VATLoss()
lds = vat_loss(model, [b_input_ids, b_token_type_ids, b_input_mask])
# 学習
outputs = model(b_input_ids,
token_type_ids=b_token_type_ids,
attention_mask=b_input_mask,
labels=b_labels)
# 損失
loss = outputs.loss + 0.1 * lds
# 最適化
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item()
d = {
"iter": iter+1,
"train_loss": loss
}
loss_list.append(d)
# モデルの保存
path = MODEL_PATH + "model_{}".format(epoch)
if not os.path.exists(path):
os.mkdir(path)
model.save_pretrained(path)
loss_dict = {"epoch": epoch, "loss": loss_list}
return train_loss, loss_dict
#####################################################################################
# テストパートの定義
def func_validation(model):
model.eval() # 訓練モードをオフ
val_loss = 0
for batch in validation_dataloader:
# 単語ID, Attention Mask, 正解データ
b_input_ids = batch[0].to(device)
b_token_type_ids = batch[1].to(device)
b_input_mask = batch[2].to(device)
b_labels = batch[3].to(device)
vat_loss = VATLoss(xi=10.0, eps=1.0, ip=1)
with torch.no_grad(): # 勾配を計算しない
lds = vat_loss(model, [b_input_ids, b_token_type_ids, b_input_mask], back=False)
outputs = model(b_input_ids,
token_type_ids=b_token_type_ids,
attention_mask=b_input_mask,
labels=b_labels)
loss = outputs.loss + 0.1 * lds
val_loss += loss.item()
return val_loss学習の実行をします。今回エポック数は2としました。
# 学習の実行
max_epoch = 2
train_loss_ = []
val_loss_ = []
loss_dict_list = []
for epoch in range(1, max_epoch+1):
print("="*25, "Epoch: {}".format(epoch), "="*25)
train_, loss_dict = func_train(epoch, model)
val_ = func_validation(model)
train_loss_.append(train_)
loss_dict_list.append(loss_dict)
val_loss_.append(val_)7. 評価
最後に正解率の確認をします。
# Accuracyの確認
model.eval() # 訓練モードをオフ
try_count = 0
correct_count = 0
lists = []
for batch in validation_dataloader:
# 単語ID, Attention Mask, 正解データ
b_input_ids = batch[0].to(device)
b_token_type_ids = batch[1].to(device)
b_input_mask = batch[2].to(device)
b_labels = batch[3].to(device)
with torch.no_grad(): # 勾配を計算しない
preds = model(b_input_ids,
token_type_ids=b_token_type_ids,
attention_mask=b_input_mask)
logits_df = pd.DataFrame(preds[0].cpu().numpy(), columns=['logit_0', 'logit_1', 'logit_2', 'logit_3', 'logit_4'])
pred_df = pd.DataFrame(np.argmax(preds[0].cpu().numpy(), axis=1), columns=['pred_label'])
label_df = pd.DataFrame(b_labels.cpu().numpy(), columns=['true_label'])
result_df = pd.concat([pred_df, label_df], axis=1)
lists.append(result_df)
df_bool = result_df['pred_label'] == result_df['true_label']
try_count += df_bool.shape[0]
correct_count += sum(df_bool)
print('accuracy = {}'.format(correct_count / try_count))実験
今回、VATを用いない場合も実験を行い、VATの有効性を確認しました。 実験は10回行って、その平均値を評価としました。 また、VATを用いた場合、用いない場合の2つの平均値からに有意な差があるかどうかを確認するためにStudentのt検定を行いました。 設定としては、有意水準0.05の片側検定を行い、帰無仮説を「2群間の平均値に差がないこと」としました。
VATを用いない場合と比較すると、以下のような結果となり、VATを導入することで正解率の向上が見られました。 また検定を行った結果、p値はp<0.05となり、帰無仮説「2群間の平均値に差がないこと」は棄却され、対立仮説「2群間の平均値に差があること」を成立させることができました。
| モデル | 正解率 |
|---|---|
| BERT | 72.0 |
| BERT+VAT | 73.7 |
おわりに
今回、BERTにVATを適用したQAタスクを行いました。結果としては、VATを適用することで正解率の向上が見られました。 所感としては、VATの実装が画像しか公開されていなかったため、実装にかなり時間がかかりました。また、データの数が28%(約2500個)と少ないにもかかわらず、正解率が70%以上達成するBERTモデルにとても驚きました。
Yuki Kawara
Company: Fusic CO., LTD. 自然言語処理に興味があります。