
Table of Contents
こんにちは、ハンです。 今回はAWS SageMakerの「Batch Transform」を使ってみたので、簡単に紹介したいと思います。
また、Batch Transformの実装はSageMaker Example Documentsなどで確認できましたが、Batch Transformの重要機能である
- 大量のデータをBatch管理する仕組み
- InputとOuputを連結して出力する方法
に関しての資料があんまりなかったので、自ら試したことも少し説明します。
Batch Transformとは?
「大容量データセットを周期的に推論したい」時に使えるAmazon SageMakerのデプロイ側の機能で、S3に保存されているデータに対して推論を行い、その結果をS3に保存してくれます。 大量のデータセットを扱う様々なPipelineが存在すると思いますが、Batch Transformを使うことで、より簡単で効率的な実装ができます。
何が便利なの?
モデルへの入力データのサイズをコントロールしたり、インスタンスのリソースを管理したりしてくれるので「簡単に推論作業を行う」ことができます。大げさに言うと「入力データ・学習済みモデルを準備」して置くと色々楽に進める感じです。
普段、大規模データの推論を行うときに、
- データの整理
- AWSの無駄な課金がない構成
- Input・Outputデータの管理
などを考えるべきですが、Batch Transformを使うとこの作業がかなり簡単になります。
Batch Transform 実装
前回の記事、「知識蒸留(Knowledge Distillation)を使ってResNet18をより賢くしてみよう」、で学習したResNet18モデルを使って、「SageMaker PytorchModelを生成し、Batch Transformで推論する」流れを実装してみました。
推論データの準備
今回の実験では「Bytesに変換したイメージをJSONlines形式」に保存したデータを使います。 下記は「sample_input.jsonlの中身」で、S3の推論データ用フォルダには、異なるデータ数(x)を持つ複数のJSONlinesファイルが保存されています。
# sample_input.jsonl
# Bytes化されたイメージがn行ある
{"id" : 1, "inputs" : "iVBORw0KGgoAAAANSUhEU...", "date" : "2022/01/01"}
{"id" : 2, "inputs" : "iVBORw0KGgoAAAANSUhEU...", "date" : "2022/01/02"}
...
{"id" : n, "inputs" : "iVBORw0KGgoAAAANSUhEU...", "date" : "2022/05/04"}SageMaker PytorchModel 生成
SageMakerで学習したモデルではなく、ローカルで学習したPytorchモデルを使うので、SageMakerモデルを生成する必要があります。詳細はSageMaker Documentsをご参考ください。
Entry Point 作成
推論用インスタンスが参考するentry pointファイルを作成します。「モデルの呼び出し・InputやOutputの処理など」Batch Transformの推論に使える基本的な設定を行う感じです。 何も設定しないとsagemaker-pytorch-inference-toolkitのDefaultコードで動きますが、自分のデータに合わせてentry pointファイルに書く必要があります。
以下は、Custom ResNet18モデルでBytes変換されたイメージを推論するための「inference.py」コードの一部です。
def model_fn(model_dir):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model_load()
with open(os.path.join(model_dir, 'model.pth'), 'rb') as f:
model.load_state_dict(torch.load(f))
return model.to(device)
def input_fn(request_body, content_type='application/jsonlines'):
if content_type == 'application/jsonlines':
print("Request received : application/jsonlines")
data = _decode_request(request_body)
print(f'Num of data in a request: {len(data)}')
return data
...
def predict_fn(input_obj, model):
print(f'Input Object Shape: {input_obj.shape}')
output = model(input_obj)[0]
pred = torch.argmax(output, dim=1)
return np.array(pred).tolist()
def output_fn(predictions, accept="application/jsonlines"):
if accept == "application/jsonlines":
lines = []
for pred in predictions:
lines.append({'predictions': pred})
json_lines = [json.dumps(l) for l in lines]
json_data = '\n'.join(json_lines)
return json.dumps(json_data)
...- model_fn
モデルを呼び出すコードが書かれます。
sagemaker-pytorch-inference-toolkitを読んでみると、Pytorchの場合「default_model_fnはElastic inferenceモデルを呼ぶ」作業を行うので、普通のモデルを呼び出すコードを書きました。 - input_fn
RequestBodyの内容を前処理します。
先ほど作成した推論データは「Bytes化されたイメージをJSONlines」なので、推論データをモデルが読み込める形に処理しました。(RGB形式のTensorsに変換) 以外にも、テキストデータをTokenlizationしたり、Tensor変換・Normalizationしたりするなど必要な前処理を行うことができると思います。 - predict_fn
model_fn・input_fnから読んだモデルとデータを用いて推論を行うコードです。
データ・モデルの構成やOutputの形などに合わせてコードを書きます。 - output_fn
output形式を触る部分です。
JSON・CSV・NPYなどの構成に変換すれば、returnされた形式でS3(Ouput)に保存されます。
Batch Transform 実行
from sagemaker.pytorch.model import PyTorchModel
# Batchの構成のための設定(次のChapterで説明)
strategy = 'MultiRecord'
split_type = 'Line'
max_payload = 1
# Batch Transformの実行に必要な設定(Entry Point・学習済みモデル・InputとOutputの設定)
role = 'AWSRoleName'
entry_point = 'inference.py'
model_path = 's3://your/model/dir/model.tar.gz'
input_s3_path = 's3://your/input/data/dir'
output_s3_path = 's3://your/output/data/dir'
pytorch_model = PyTorchModel(model_data = model_path,
entry_point = entry_point,
source_dir = 'src',
framework_version ='1.12.0',
py_version ='py38',
role = role)
transformer = pytorch_model.transformer(instance_count=1,
instance_type="ml.m5.xlarge",
strategy=strategy,
max_payload=max_payload,
output_path=output_s3_path)
transformer.transform(
data = input_s3_path,
data_type = "S3Prefix",
content_type = "application/jsonlines",
split_type = split_type,
wait = False,
)上のコードは、pytorchモデルの生成・Transformerの生成・実行するコードで、
- input_s3_pathの全てのjsonlinesファイルを読み込む
- 設定に沿ってデータをBatch化し、インスタンスへRequestを送る
- model_pathのモデルを用いて推論を行ない、結果をoutput_s3_pathに保存する
作業が一気に行われます。「entry_point・model_path・input_s3_path・output_s3_path」を設定しただけなのに...本当に使いやすい機能だと思います。
特徴①:入力データのサイズを自動的にコントロール
Batch Transformは「SplitType・BatchStrategy・MaxPayloadInMB」の設定に沿ってデータを分け、RequestBodyのサイズをコントロールします。上記のパラメータを簡単に説明してから、例を通じてその動きを理解してみましょう。
SplitType:入力データをどう分けるか
S3から読み込んだデータを分ける基準を決めるパラメータです。
この基準で分けられた個別のオブジェクトを「レコード」と呼びます。下記の4つの設定ができて、Noneの場合一つの入力ファイルが一つのレコードになり、Lineの場合ファイル中の一行一行のLineが一つのレコードになります。
- None | Line | RecordIO | TFRecord
BatchStrategy:分けられたレコードをどう扱うか
ResponseBodyを構成する時に、複数のレコードを使うかどうかを決めるパラメータです。
下の2つのオプションがあり、MultiRecordに設定された場合、複数のレコードをまとめて一つのRequestBodyとして送ることができます。
- MultiRecord | SingleRecord
MaxPayloadInMB:どのくらいのサイズまでのRequestを許可するか
RequestBodyのサイズを決めるパラメータで、Integer(0~100、MB単位)の設定ができます。
一つのRequestBodyのサイズがMaxPayloadInMBを超えるとErrorが発生し、「MaxConcurrentTransforms(インスタンスが何個のRequestを並列に処理するか)* MaxPayloadInMB」が100を超えてもErrorが発生します。従い、処理するデータのサイズに合わせて設定する必要があります。
Batch Transformの設定によるResponseBodyの変化
下図は、上記パラメータの設定によるResponseBodyの形を可視化したもので、次のような前提での実験結果です。
- S3(input_s3_path)の中に2つのJSONlinesファイルが保存されている。
- ファイル①には100行、ファイル②には1000行のデータがある。
- データ300行は1MBになる。
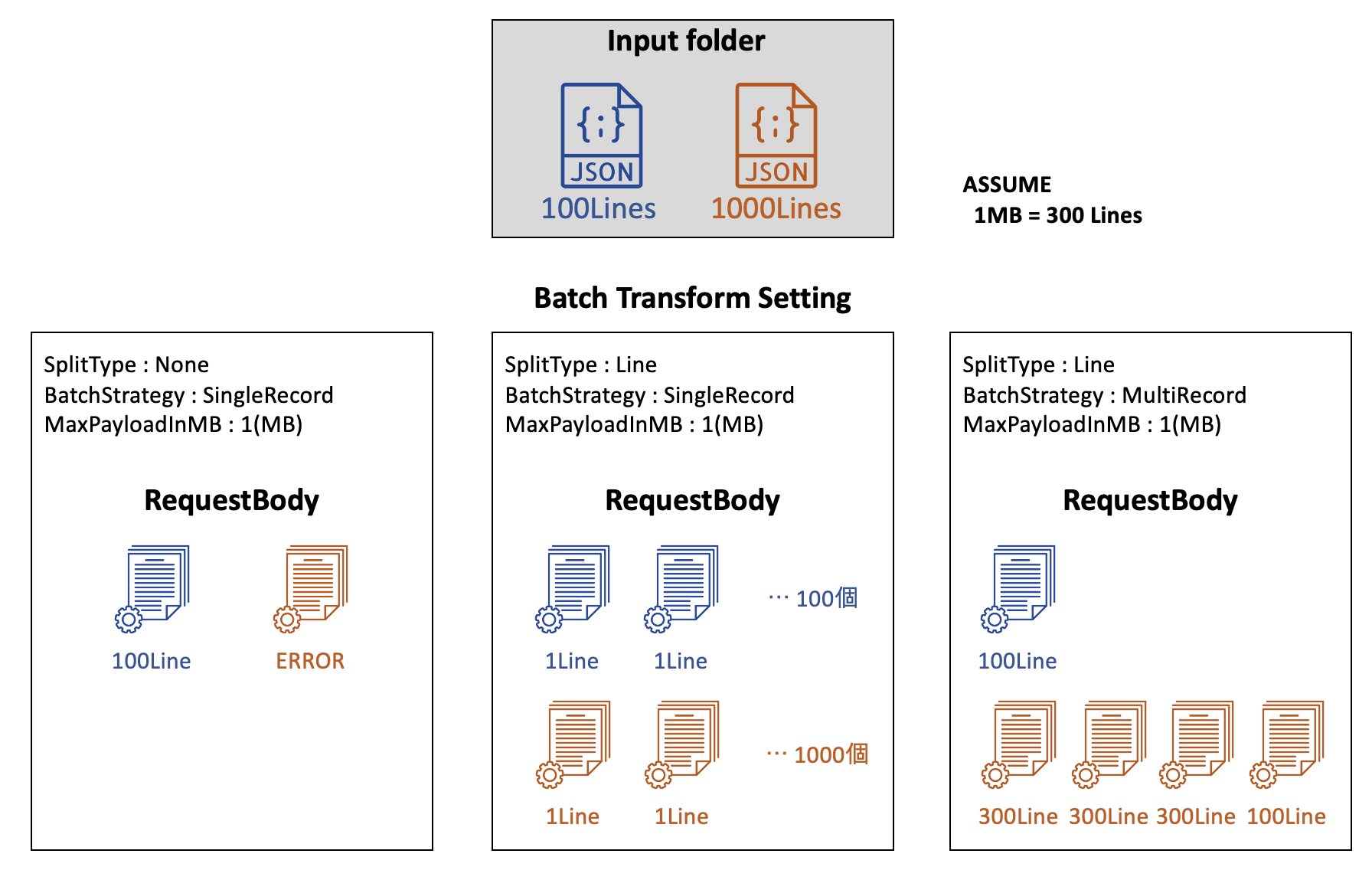
None SplitType + SingleRecord
SplitTypeが「None」であるので、一個一個のファイルがレコードになり、SingleRecord設定によって、一つのレコードが一つのRequestBodyになります。上記の前提で、1000行のデータは1MBを超えるので、Errorを出します。(MaxPayloadInMBを4以上にすると問題なし)
この場合、モデルのBatchサイズが1になるので「巨大なデータ・モデルを扱う」時に有用な設定であると思います。また、AWSのExampleのように、前処理されてない生のファイルを入力として扱うときにも使えそうです。
Line SplitType + SingleRecord
SplitTypeが「Line」であるので、ファイル中の一個一個のJsonLineが一つのレコードになり、SingleRecord設定によって、1行のLineがResponseBodyになります。一行のResponseは1MBを超えないのでErrorはなく、総1,100回のRequestがインスタンスに届きます。
入力ファイルが「CSVやJSONなどの形」をしていて、1行のデータが「時系列データのように長いデータ」である場合、良い設定になると思います。
Line SplitType + MultiRecord
SplitTypeが「Line」であるので、ファイル中の一個一個のJSONlineが一つのレコードになり、MultiRecordの設定によって、複数のレコードを一つのResponseBodyに纏めます。Batch TransformはMaxPayloadInMBを超えないようにResponseBodyのサイズ(Mini-batch)を調節します。 上の例では、1000行のJSONlinesファイルを3つの300行ResoponseBodyと、1つの100行ResponseBodyに分けてインスタンスに送ります。
自動的にMini-batchを組んでくれるので、「データの量が多い・一個データのサイズが小さい」時に有用な設定だと思います。ResponseBodyサイズがMaxPayloadInMBを超える恐れはないですが、インスタンスのメモリがMini-batchを一気に処理できないとOut-of-Memoryになるのでご注意ください。
注意点
Batch Transformではインスタンスを複数立てて同時に推論させることもできます。この場合注意することが「インスタンスの数 <= ファイルの数」であることです。一つのファイルは一つのインスタンスに与えられ、ファイル間でのデータ共有は行われないようです。上記の例を例えにすると、JSONlinesファイルが2つなので、3つのインスタンスを立てても「2つだけが動き、一つは遊ぶ」状況になります。
特徴②:入力データと出力データを連結
Batch Transformでは「InputFilter・JoinSource・OutFilter」パラメータを設定することで、Input・Outputアトリビュートを管理します。
InputFilter
必要なアトリビュートをフィルタリング(選択)するパラメータです。
アトリビュートは入力データで定義されたもので、具体的な例は下のコードを参考してください。
# sample input data
'''
{
"id" : 1,
"ImageFeature" : "iVBORw0KGgoAAAANSUhEU...",
"TextFeature" : "It is a sample text",
"date" : "2022/01/01"
}
'''
# 1. ImageFeatureだけ入力
"InputFilter": "$.ImageFeature"
# 2. idとImageFeatureを入力
"InputFilter": "$['id','ImageFeature']"
# 3. dateを除いたアトリビュートを入力
"InputFilter": "$[:-1]"JoinSource
InputデータとOutputデータを連結するかどうかを設定するパラメータです。
「None | Input」2つのオプションがあり、Inputに設定すると**OutputデータにはInputアトリビュートも含まれます。**JoinSourceを使うときには以下のような設定も必要になります。
- ContentType(InputのMIMEタイプ)とAccept(OutputのMIMEタイプ)を合わせる。
- SplitType(Inputデータの分け方)とAssembleWith(Outputデータの組み合わせ方)を「Line」にする。
OutputFilter
InputFilterとほぼ同じ役割の設定であり、S3に保存する最終的なOutputのアトリビュートを選択するパラメータです。
JoinSourceがNoneである場合は「Entry pointのoutput_fnの出力がアトリビュート」になりますが、JoinSourceがInputになると「Inputのアトリビュートもフィルタの対象」になります。
Batch Transformの設定によるOutputの形
少し複雑な説明になりましたが、実際の例を見てみると簡単に理解できると思います。
Inputの形は上のInputFilterでの例と同様で、output_fnのreturnは次のような形をしている時の例です。
# sample return (output_fn)
# モデルの推論結果によって数値は異なる。
{"predictions" : 1, "InferenceTime(ms)" : 100}JoinSourceがNoneの場合
InputデータとOutputデータの連結機能を使わない場合、SageMakerの基本的なOutputフォームとoutput_fnに従った出力をS3に保存します。
# sample output (JoinSource = None)
{
"SageMakerOutput":{
"predictions" : 1,
"InferenceTime(ms)" : 100
}
}JoinSourceがInputの場合
# sample output (JoinSource = Input)
{
"SageMakerOutput":{
"predictions" : 1,
"InferenceTime(ms)" : 100
},
"id" : 1,
"ImageFeature" : "iVBORw0KGgoAAAANSUhEU...",
"TextFeature" : "It is a sample text",
"date" : "2022/01/01"
}JoinSourceがInputの場合(OutputFilter使用)
# sample output (JoinSource = None)
# "OutputFilter": "$['SageMakerOutput', 'id', 'TextFeature']"
{
"SageMakerOutput":{
"predictions" : 1,
"InferenceTime(ms)" : 100
},
"id" : 1,
"TextFeature" : "It is a sample text"
}まとめ
上記のBatch Transformの特徴について様々な資料がありましたが、実際にどのような動きをするかを説明してくれる資料は少なかったので、自分が試したことを共有いたしました。
Batch Transformは特に何の設定なしでも使いやすい推論機能でありますが、今回紹介したことを活用すればより効率良い推論プロセスが構築できるのではないかと思います。
参考資料
Han Beomseok
Python, AI Engineering, Natural Language