
Table of Contents
こんにちは、機械学習チームのハンです。
知識蒸留(KD:Knowledge Distillation)というものが気になり、簡単なResNetモデルで色々実験を行ってみたので紹介したいと思います。
Knowledge Distillationとは?
あるモデルが学んだ知識を他のモデルに移すという概念であり、Distilling the Knowledge in a Neural Network(2015)で初めて提案されたものです。
最近の機械学習モデルの精度は段々上がっていますが、一方で、モデルが巨大化しています。そのため、実際にデプロイしたり個人が利用したりするには負担になるものも多いです
下の図で確認できるように、Teacherモデルの知識を蒸留しStudentモデルに移して「より軽くて良い精度を持つモデルを作る」のが、KDの目的だと考えられます。
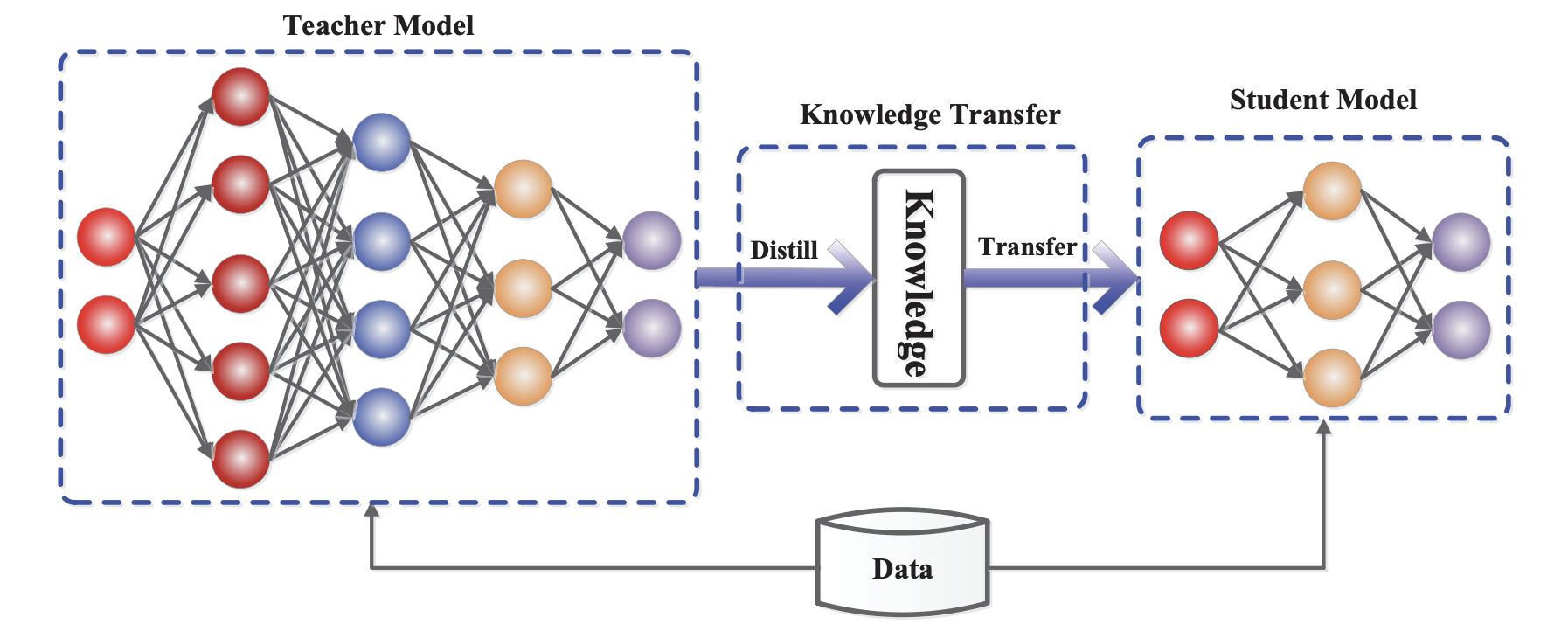
どのような知識を利用するか?
KDで利用される知識(Knowledge)は大きく下記の3つに分けられます。
- Response-based Knowledge
- Feature-based Knowledge
- Relation-based Knowledge
Response-based Knowledge
モデルのResponse、つまり「モデルのOutput」を知識として扱う方法です。巨大なTeacherモデルのOutput(Logit)には、豊かな情報が入っているという考えられ、Outputの分布を知識として扱います。
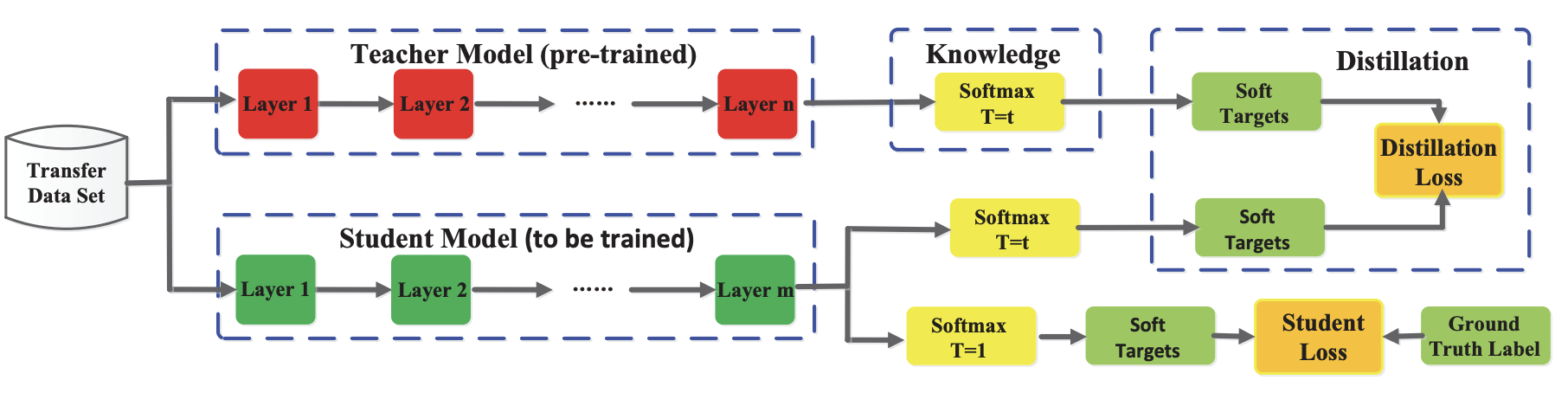
上図はResponse-base Knowledgeを用いた一般的なKDモデルの構成ですが、右上のDistillation Lossの部分に注目してください。Pre-trainされた「TeacherモデルのOutputが真似できるように学習」していることがわかります。
Feature-based Knowledge
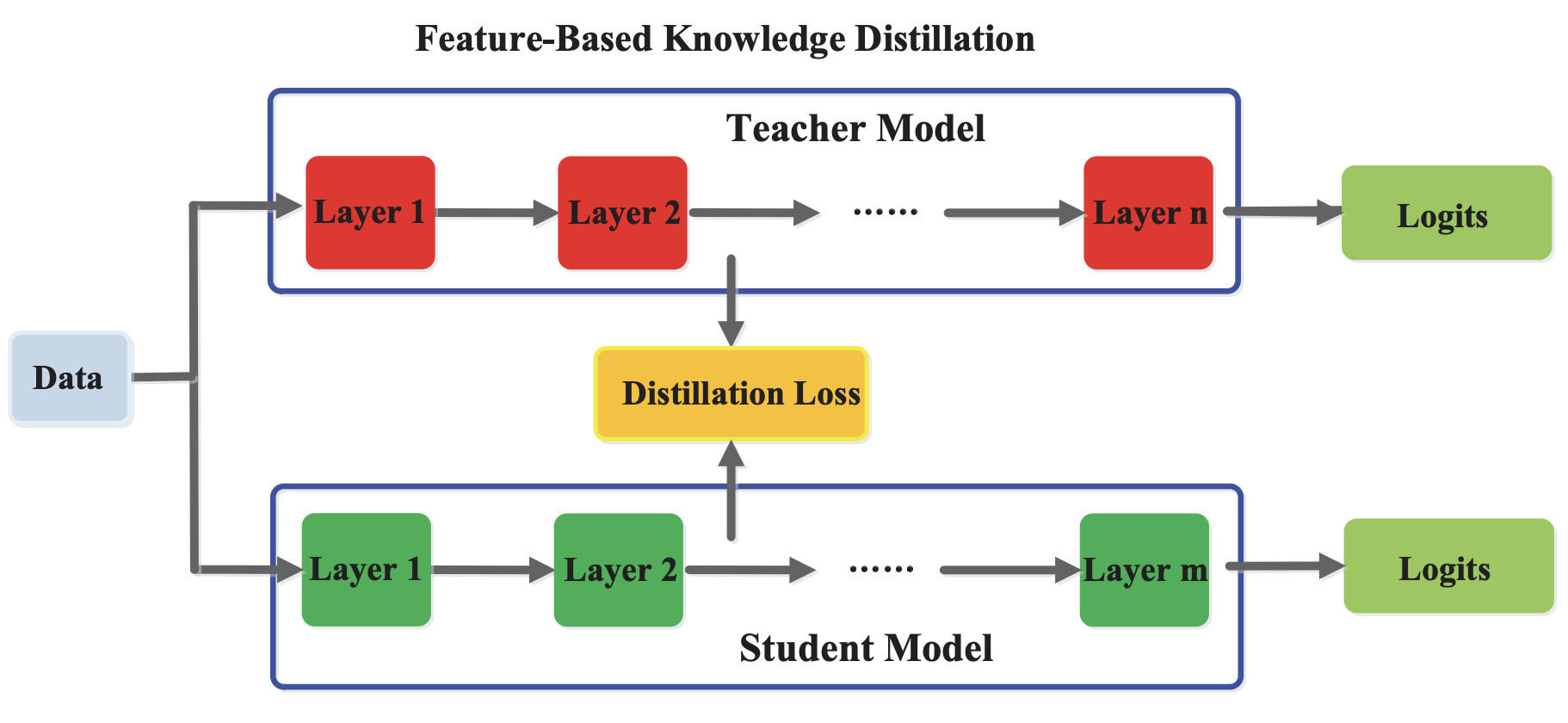
モデルの中間層のFeature-Map、「中間層のOutput」を知識として扱う方法で、この特徴は「Hint」とも呼ばれます。下図のような構造で、Studentモデルは「Teacherモデルの中間層から知識を得て、同様な中間層Outputを作れる」ように学習を進めます。
この方法はResponse-based Knowledgeと比べ、細くて深い層を持つネットワークの学習に役に立つと思われています。しかし、中間層のOutputの形はモデル・レイヤーによって様々であり、Lossを実装する時に手間がかかる場合もあります。
Relation-based Knowledge
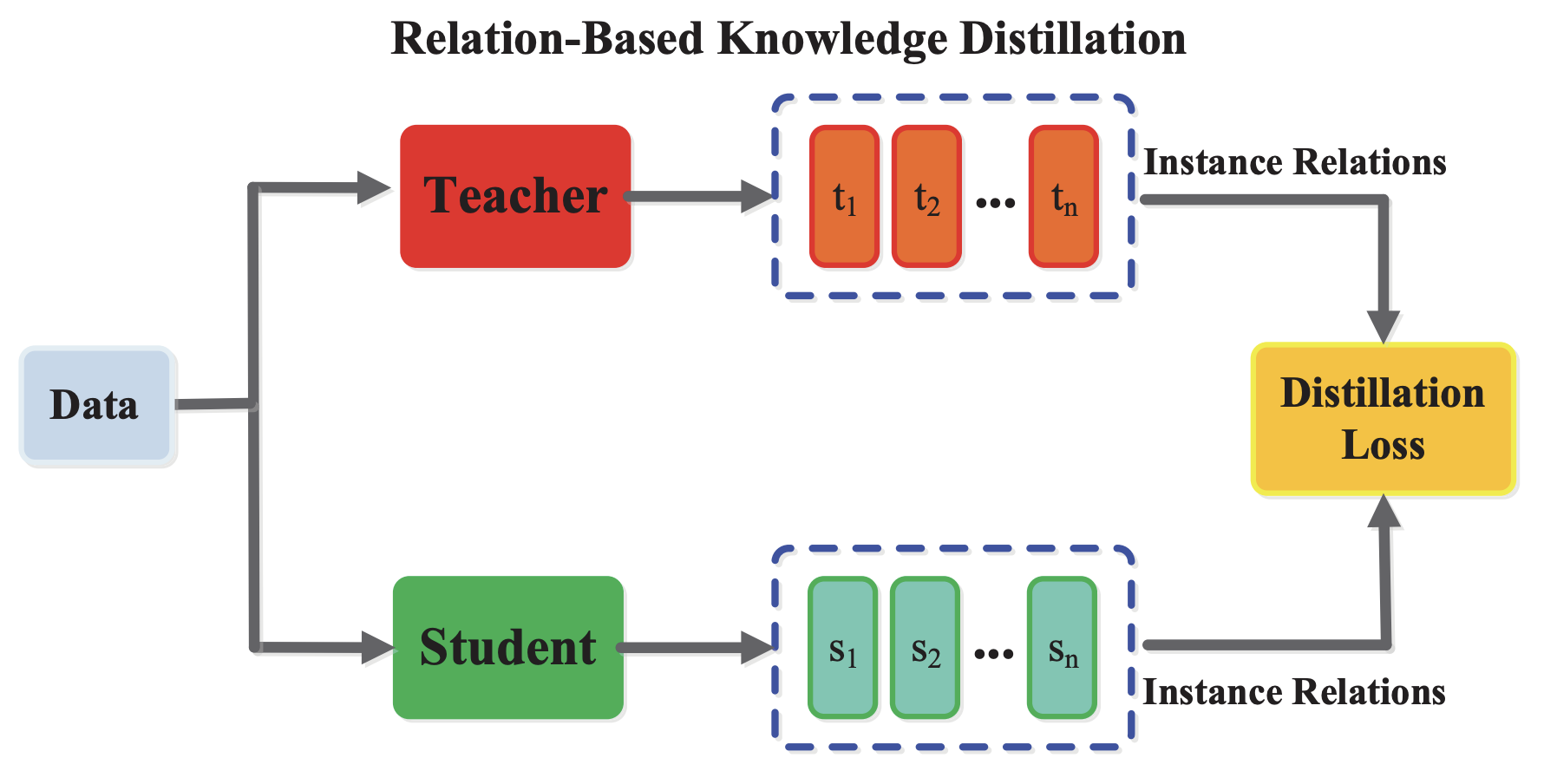
モデル中の「レイヤーの間に存在する関係」を知識として扱う方法です。上記2つの方法では、Teacher・Studentモデルのある出力を直接1:1マッチングして比較していますが、Relation-based Knowledgeでは、個別モデルの中間層Hint間の関係を求め、その関係を比較します。
例えば、中間層出力間の距離を関係として扱い「Teacherモデルと似たような関係をStudentが学習する」ような形になります。
知識をどのように移動させるか?
KDを行う方式として、以下の3つのやり方があげられます。
- Offline Distillation
- Online Distillation
- Self Distillation
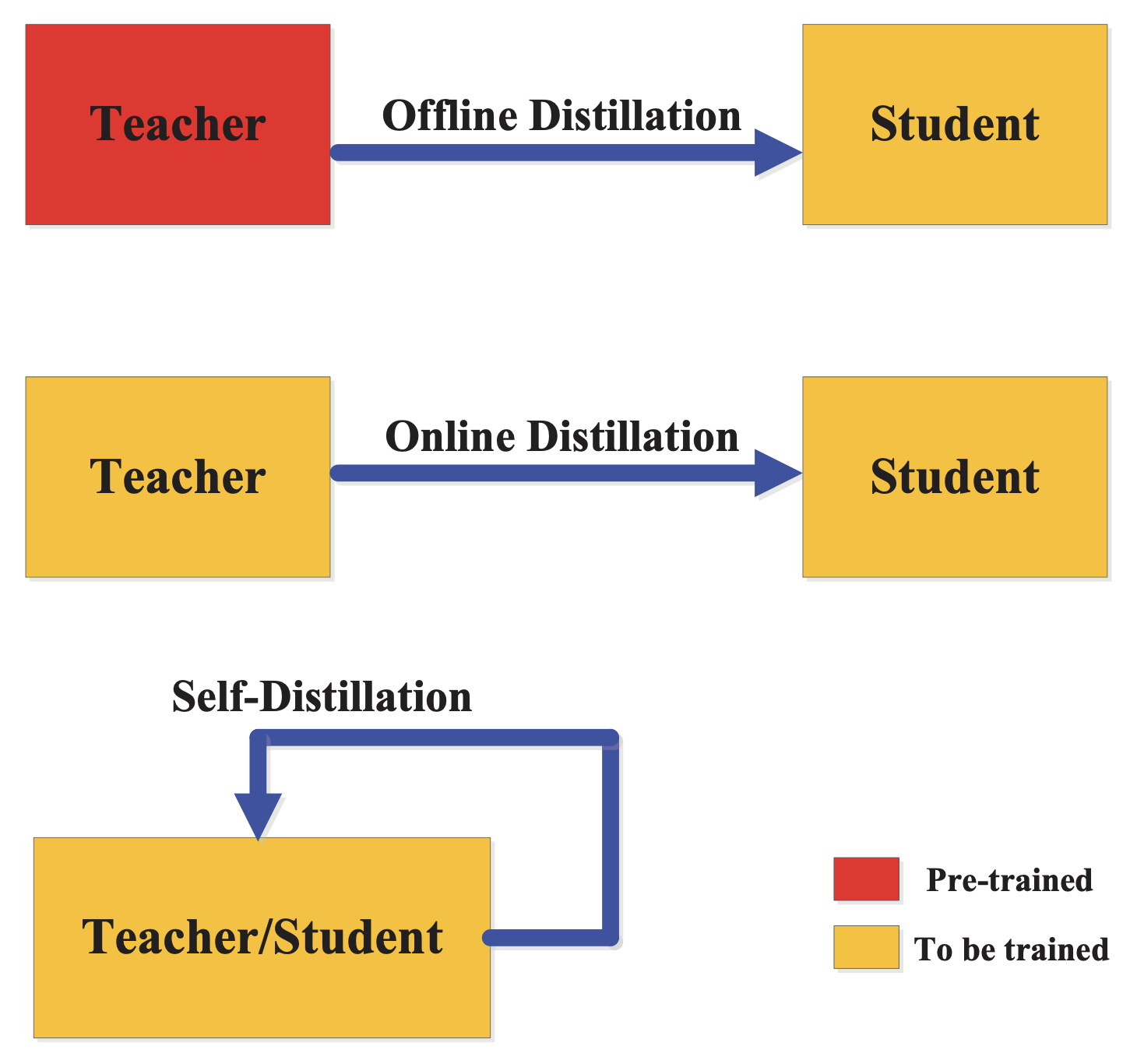
Offline Distillation
「Pre-trainしたTeacherモデルの知識をStudentモデルに学習させる」方法で、一番簡単で一般的なKD方法になります。
KDプロセス上、TeacherモデルはFreezeされ「入力に対して知識になるOutputを推論する」役割、Studentモデルは「Teacherモデルの知識を用いて学習する」役割を行います。一般にTeacherは「スケールが大きく良い精度を持つモデル」が考えられ、個人的には「大きいモデルの知識を蒸留し軽いモデルに移す」というKDの目的にぴったりの方法だと思います。
特徴としては、Pre-trainされたTeacherモデルが要るので「2Stage方式」になることです。
Online Distillation
KDプロセス上、「Teacher・Studentモデルがお互いに学習を行い、知識を共有する方法」で、上の図では、学習能力のあるTeacherモデルの知識をStudentモデルに蒸留することを表しています。 この概念以外にも、Teacherモデル無しで
- 「構造の異なる2つのStudentモデルがをお互いに知識を与える
- 「構造は同じだが、設定が異なる2つのStudentモデル」がをお互いに知識を与える
ような方法もあります。(参考:Deep Mutual Learning)
Offline Distillationと異なり、End-to-End学習ができる・モデルお互いに知識の共有ができるという特徴があります。
Self Distillation
「一つのモデルでKDを行う」方法で、ネットワーク中でTeacherになる特徴を選択し、その特徴を同じモデルが学習します。例えば、
- 「同じイメージに異なるAugmentationをかけた結果」を一つのモデルに通し、少し異なるOutputをTeacher・Studentターゲットにする
- 「最終レイヤー・中間レイヤー」のOutputをTeacher・Studentターゲットにする
などの方法が挙げられます。
一つのモデルを用いているので上記2つの方法と比べ、学習時間・パラメータ数の面でメリットになる特徴があります。
3つの方法と一般的なモデル学習の比較
| 基準 | 比較 |
|---|---|
| パラメータ数 | Online >= Offline > Self >= Normal |
| 学習時間 | Offline > Online > Self > Normal |
| 精度 | Offline ・ Online ・ Self > Normal |
上記のテーブルは、KDを使ってない普通なモデル(Normal)学習と上記のKD学習方法を比較してみたものです。
学習パラメータ・学習時間を考えると、Self Distillationの方が一番良さそうに見えますが、
- 既にPre-trainされたTeacherモデルが存在する
- アンサンブル的な学習方法で精度が上がる
などの条件では他の方法を選択する方が良いと思いますので、どっちの方法が優れているとは言い難いと思います。
今回試してみたことは?
ResNetを用いて、CIFAR100の分類モデルを学習してみました。KDを使ってない普通なモデル(Baseline)と様々なKDモデルの精度差を確認してみました。
① Baselineモデル
BaselineになるResNetモデルは下記の設定で学習されました。
- モデル:ResNet18
- クラス数:100
- Loss関数:Cross Entropy Loss
- Optimizer:SGD(momentum=0.9、weight_decay=5e-4)
- Scheduler:Cosine Annealing with Warm Up
- Epochs : 200
Cosine Annealing with Warm Up
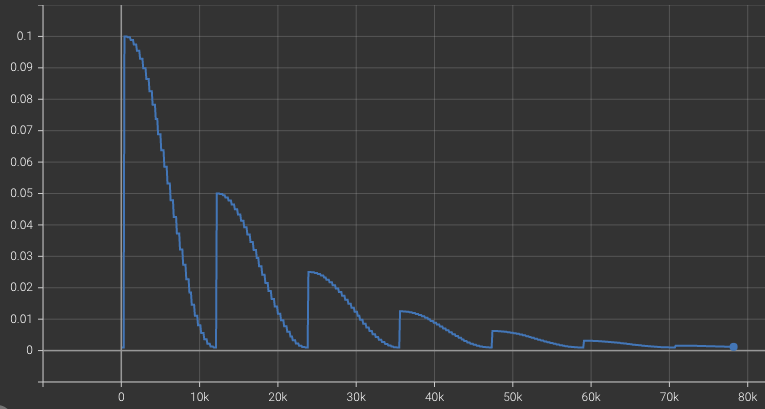
Bag of Tricks for Image Classification with Convolutional Neural Networks論文で良い精度を見せてくれたスケジューラーで、CyclicLR・CosineAnnealingLR・Warmupなどを組み合わせたものです。経験上、分類モデルの学習で安定的なパフォーマンスを出してると思いましたので、今回実験では上図のようなLearning Rateで学習を行いました。
② Offline Distillation モデル
Pre-trainされたTeacherモデルのResponse-base Knowledgeを利用するOffline Distillationモデルを構成しました。詳細は以下のようになります。
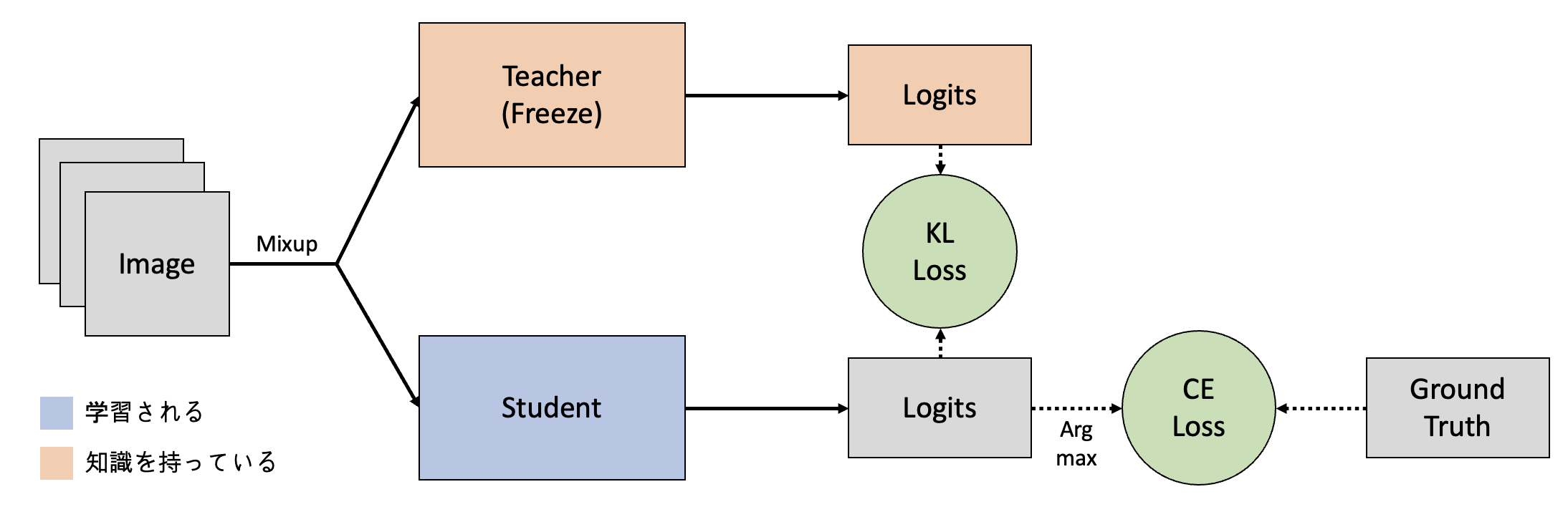
- Studentモデル:ResNet18
- Teacherモデル:CIFAR100 Pre-trained モデル
- Loss関数:Cross Entropy Loss、KL Divergence Loss
- Mixup:入力イメージの多様性を拡張
- 他の学習設定はBaselineモデルと同様
KDの適応方法
このモデルでは、TeacherモデルのOutput(Logit)知識をStudentモデルが学習します。 Kullback-Leibler divergence lossを用いて、TeacherモデルのSoftmax結果(正確には温度付きSoftmax)と似たような分布をStudentモデルが作れるように学習を進めます。
温度付きSoftmaxを使う理由
KD Lossを通じて学習したいのは、正解ラベルを選ぶっていうことより「Teacherモデルと似たようなSoftmax分布を作る」ことです。温度付きSoftmaxを使うことで「確率の低い部分を強調することができ、全体的な分布の知識を取れる」ようになります。
③ Self Distillation モデル
ネットワーク最終レイヤーの出力をResponse・Feature-based Knowledgeとして扱うSelf Distillationモデルを構成しました。
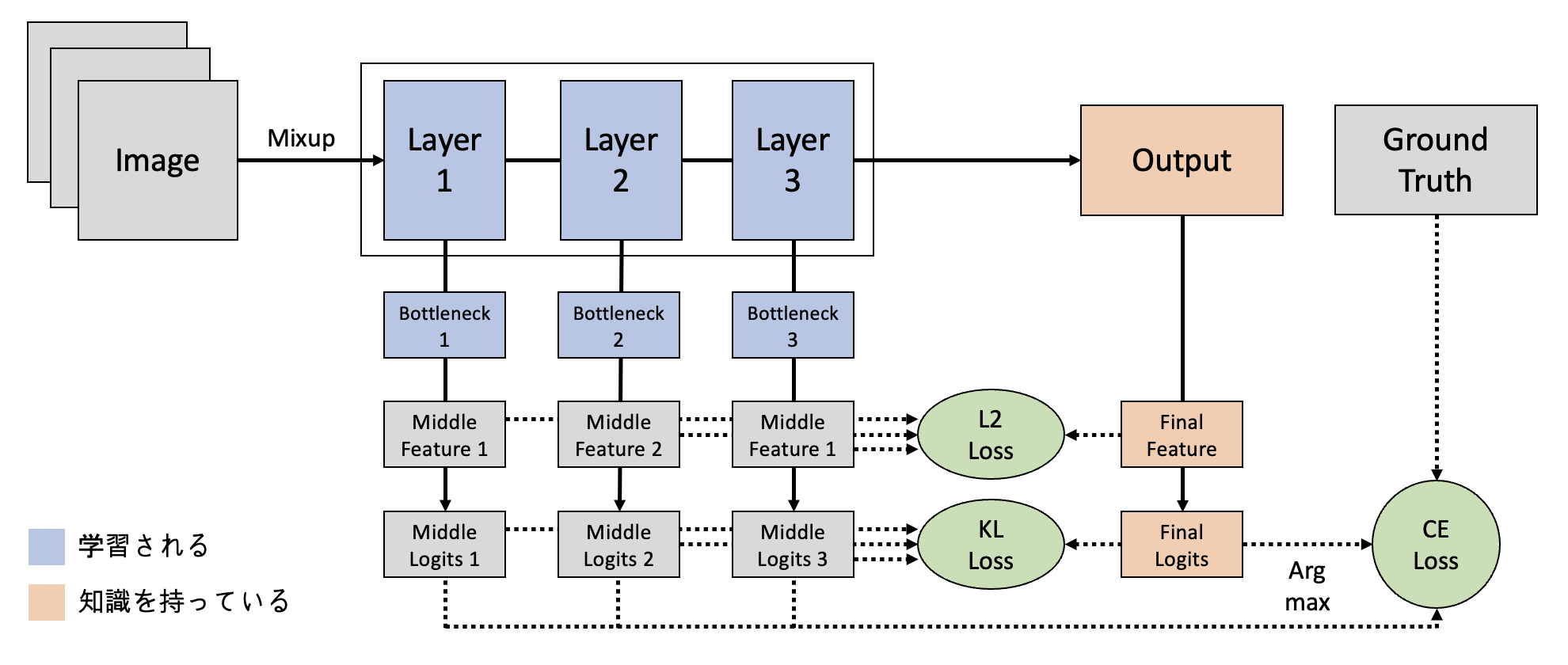
- 使用モデル:ResNet18
- Loss関数:Cross Entropy Loss、KL Divergence Loss、L2 Loss
- 他の学習設定はOffline Distillationモデルと同様
KDの適応方法
このモデルでは、以下の二つの方法を採用し知識を蒸留しています。
- 最終レイヤーからのFeature-based Knowledge(Hint)を中間層で学習
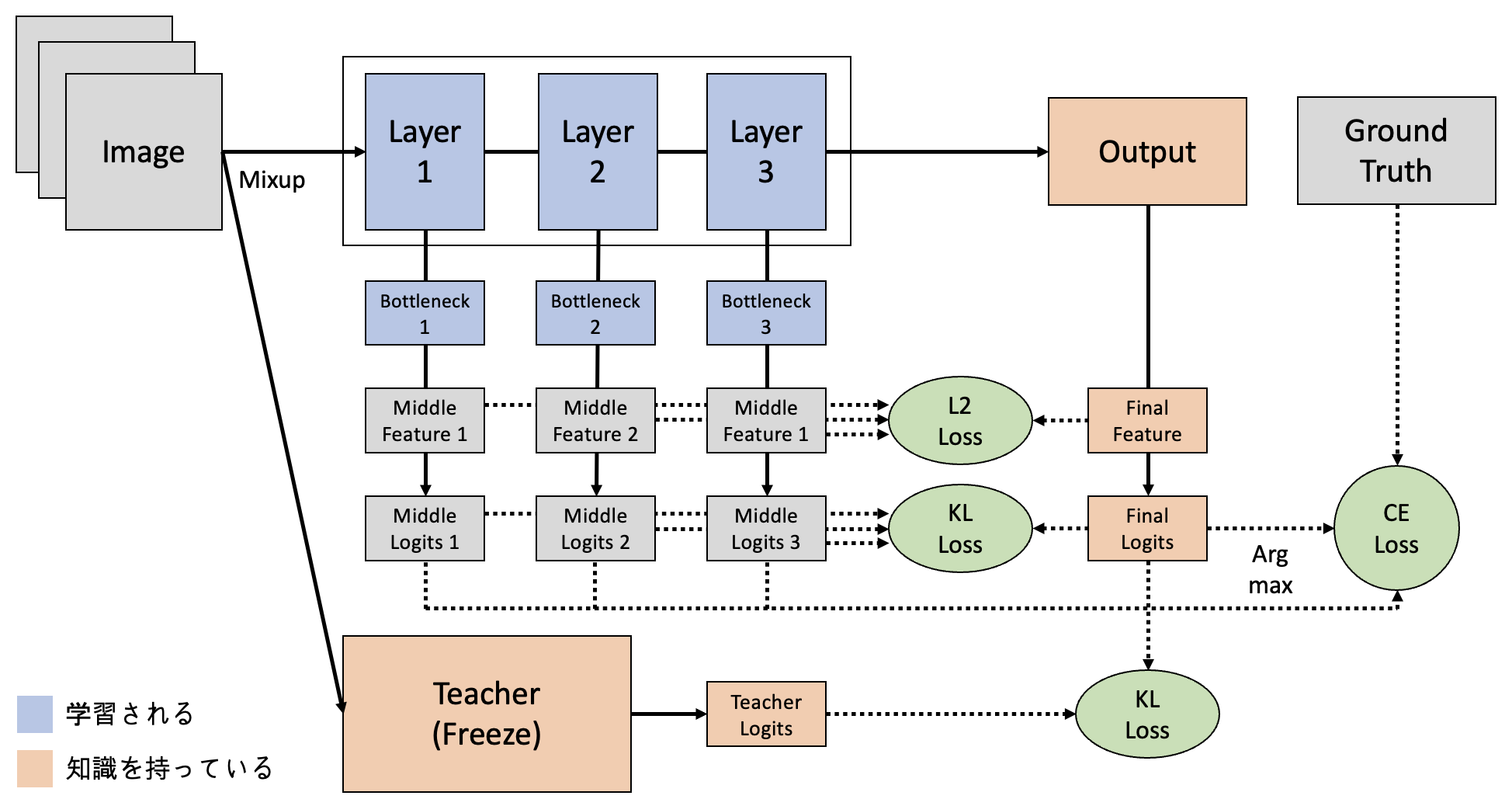
追加されたBottleneckを通じサイズが揃えたMiddle Feature(1・2・3)は、Final FeatureとのL2 Lossを求めることで知識を蒸留します。 - 最終レイヤーからのResponse-based knowledge(Logits)を中間層で学習
Middle Logits(1・2・3)はFinal Logitsの知識を学習します。 具体的な方法は上記のOffline Distillatinoモデルと同様です。
④ Offline + Self Distillation モデル
上のOffline・Self Distillationを組み合わせたモデルを構成してみました。 アイデアとしては、下のような学習を行って「Teacherモデルの知識をStudentモデルの全層に学習」させることを考えました。
- Offline Distillationを通じ、TeacherモデルのLogit知識をStudentモデルの最終レイヤーで学習
- Self Distillationを通じ、Studentモデルの最終レイヤー知識を中間層で学習
実験結果は?
下のテーブルは、
- Studentモデル:ResNet18
- Teacherモデル:repvgg_a0(75.22%)、resnet50(79.00%)
- データセット:CIFAR100
- 精度:Top-1(%)
の条件での実験結果です。
| 学習方法 | Teacherモデル | 精度 |
|---|---|---|
| ① Baseline | ー | 74.40 |
| ② Offline | repvgg_a0 | 77.56 |
| ② Offline | resnet50 | 77.65 |
| ③ Self | ー | 77.89 |
| ④ Offline+Self | repvgg_a0 | 77.95 |
| ④ Offline+Self | resnet50 | 78.36 |
2つのTeacherモデルを使って様々な実験を行ってみました。
repvgg_a0モデルをTeacherで使った場合、Teacherより精度の良いモデルの学習ができました。蒸留されたTeacherのLogits知識をガイドとして活用しながら、Ground TruthをTargetとした学習を行うことでTeacherを越えることができたと思います。
resnet50を用いたOffline+Self Distillationモデルの場合、一番良い結果が得られました。今回は学習時間の問題でもっと大きいモデルをTeacherとして使うのができませんでしたが、ResNet18モデルにどこまでKDができるか気になります。
また個人的に、Self Distillationモデルは色々活用性が高いと思いました。別のTeacherモデルが要らない・学習時間がBaselineとほとんど変わらないという面で、CNN系モデルを構築するとき簡単に使えるのではないかと思います。
今後は、より大きいモデルをTeacherとして扱ってみたり、全然別のネットワークの知識を蒸留してみたりして、KDの様々な活用方法を考えてみたいと思います。
参考資料
- 実験のコード
- 論文:
-
Githubコード:
Han Beomseok
Python, AI Engineering, Natural Language