
Table of Contents
CycleGAN VC(Voice Conversion)とは
モデルは、互いに違うセリフを発する2人の音声を学習データとして扱う、ノンパラレルな音声変換モデルです。ノンパラレルとは、2人の音声が、共に同じことを話している音声データである必要はないということです。従って、学習に使われるデータセットは、比較的に簡単に構築できます。
また、CycleGAN VCという名前から分かるよう、CycleGANの仕組みを用いたモデルであり、特定の人の音声であるかないか判断するDiscriminatorと、そのDiscriminatorを騙すための音声変換を行うGeneratorの学習がモデルの目的です。
音声特徴量学習への工夫
音声情報を扱うCycleGANモデルを構築するため、論文では様々な工夫をしていましたが、ここでは下記の2つの特徴を紹介します。
音声情報の特徴(時間的・階層的)を維持するための、2-1-2D CNN Generator
音声情報としての一貫性を維持するための、Two-step Adversarial Loss
1. 2-1-2D CNN Generator
まず、音声情報はどのような特徴を持っているかを確認してみます。上の図は、女性と男性の声をMel-Spectrogramで可視化したもので、Y軸は周波数、X軸は時間軸、色は周波数成分の音の強を表しています。
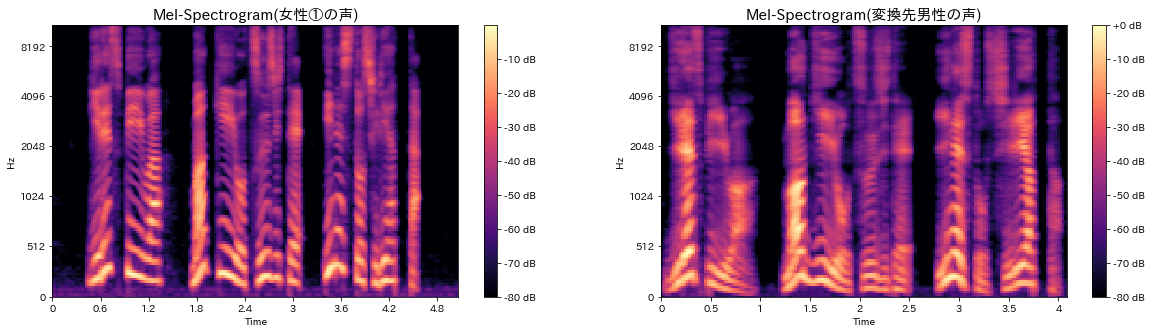
同じセリフの発話ですが、声の速さ・高さ・イントネーションなどの音声特徴によって、違う形のグラフを生成しています。(特に、低い周波数での男女差が目立ちます。)
このように、人々の音声情報は, 連続的な音波情報の集まりであり、様々な音声特徴量を含んでいることが分かります。
この音声情報の時間的・階層的特徴を学習に用いるため、CycleGAN VCモデルは2-1-2D CNN Generatorを使用しています。
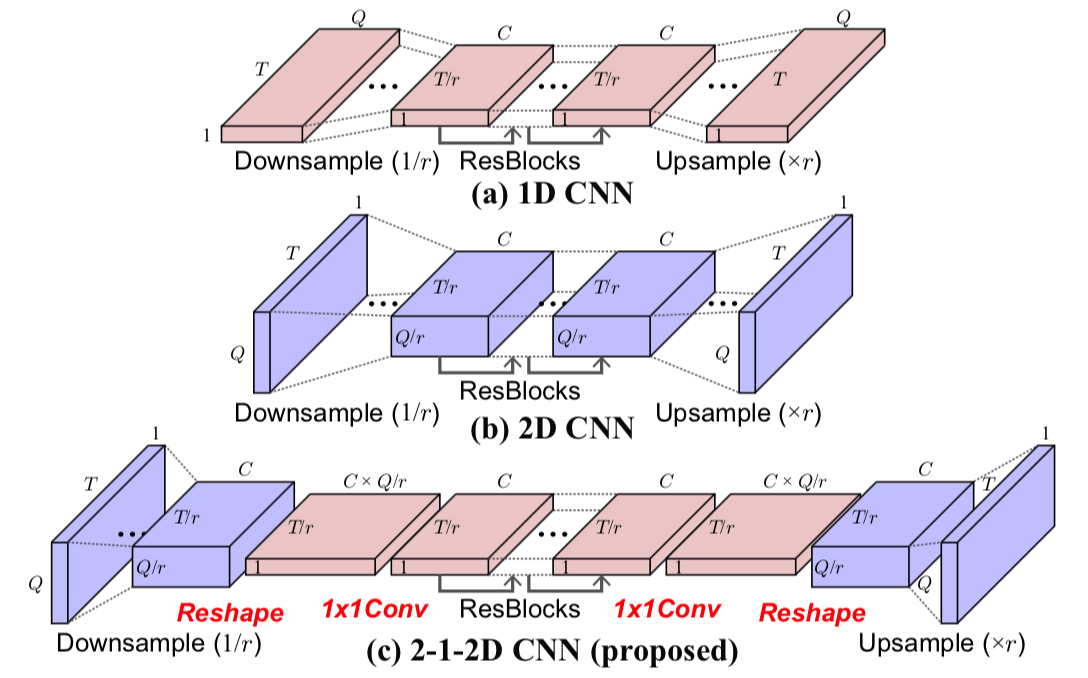
2-1-2D CNN構造(論文中Fig.2)は上図のような形になります。2D CNNでDownsample・Upsampleを行い、1D CNNで主な音声変換を行っています。この論文では、
- 2D CNNを使うことで、オリジナル音声の構造を保存しながら、音声特徴の変換が出来る。
- 1D CNNを使うことで、ダイナミックな音声特徴変換が出来る。
と述べられています。
2. Two-step Adversarial Loss
CycleGANモデルで大事なことは、Cycle Consistencyを維持することです。普通のCycleGANでは下図(論文中Fig.1)の(a)One-step adversarial lossの形で、変換先から戻ってきた結果とオリジナルデータのL1 lossを取ることで、その一貫性を維持します。

しかし、CycleGAN VCモデルは(b)Two-step adversarial lossを採用し、一回のサイクルで2つのAdversarial lossを利用出来るようにしています。これは、L1 lossだけを使ったとき起こるOver-smoothing問題を防ぐ対策であると述べられていて、より細かく音声情報の一貫性を維持するCycleGAN VCの工夫です。ここでSmoothing(平滑化)とは「データのノイズや細かな変化を除いたメインの特徴を取る」という概念ですが、Over-smoothingされた音声情報は、個人の音声特徴を失ってしまう恐れがあります。
多数の女性声を特定の男性声に変換
実験概要
- 2つのモデル(「多数の女性→変換先女性」 と 「変換先女性→変換先男性」の音声変換)を学習させ、多数の女性の声を変換先男性の声に変える実験を行ってみました。その構造は下図になります。
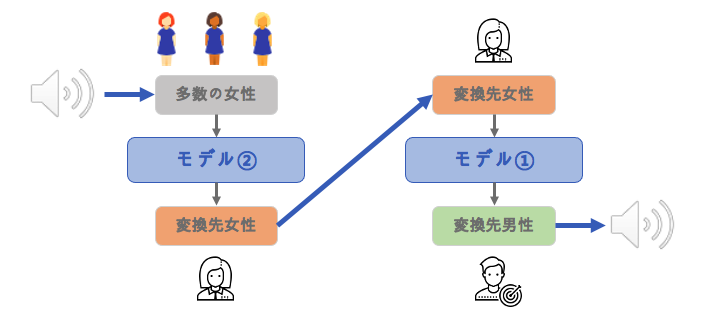
- データセット
- 100人の日本人の音声データがある、JVSコーパスを使用しました。
- パラレル(100発話)・ノンパラレル(30発話)など様々な音声データが活用出来ます。
- jackadumaさんのGithubを参考にし、2つのCycleGAN VCモデルを作成しました。
モデル①:「特定女性→変換先男性」音声変換
参考したGithubに、既に学習されている「中国人男性→中国人男性」の音声変換モデルがありましたので、そのモデルを用いた「日本人女性→日本人男性」の音声変換モデルを学習してみました。
実験設定
-
Pre-Trainedモデル(2人の中国人男性、約44,000 Epochs)を使用
-
学習データ
- 女性1人の発話:100個
- 男性1人の発話:100個
-
約20,000 Epochsの学習
実験結果
変換先の男性
変換前の女性
変換後の女性
中国語のPre-Trainedモデルと、計200個の数少ないデータセットが気になりましたが、意外と変換先男性の特徴を上手く取っていると思います。ノイズの混入はありますが、発話内容は崩れずに聴き取れるのが面白いです。
モデル②:「多数の女性→変換先女性」音声変換
次は、多数の女性の声をモデル①の女性の声に変換するモデルを作ってみました。最終的に、このモデルと上記のモデル①を組み合わせ、多数の女性の声を男性の声に変換する実験を試してみます。
そもそもCycleGAN VCモデルは、1:1関係(2人の音声)向けのモデルですが、
- インプット方の2D CNN構成を少し修正(KernelとChannelのサイズを縮小)し,
- 10人の女性の発話データから、変換先女性への音声変換を行う
多:1のモデルとして扱ってみました。実験の詳細は下のようになります。
実験設定
-
Pre-Trainedモデルは無し
-
学習データ
- 女性10人 x 5個の発話:50個
- モデル①の女性の発話:50個
-
約5,000 Epochsの学習
実験結果
10人女性の声の中、変換前3人の声を聞いてみます。
変換前の女性①
変換前の女性②
変換前の女性③
この3つ声をモデル①の女性の声に変換した声です。
変換後の女性①
変換後の女性②
変換後の女性③
モデル①+モデル②:「多数の女性→変換先女性→変換先男性」音声変換
最終的にモデル②で変換した声を、またモデル①で変換先男性の声に変換してみました。
変換後の女性①→変換先の女性→変換先の男性
変換後の女性②→変換先の女性→変換先の男性
変換後の女性③→変換先の女性→変換先の男性
変換先女性の声と似ていて、変換先男性のイントネーションと近い、女性②の音声変換結果が一番良いと思います。他の女性の声も男らしい声にはなっていますが、声の高さや速さが変換先男性の声とはギャップがあります。これは、1:1対応モデルであるCycleGAN VCを、多:1モデルとして学習したことで起こった問題だと思います。
まとめ
以上、CycleGAN VCを用いた、女性から男性への音声変換に関する実験でした。数少ないデータセットを使ったり、モデルの構造を修正し多:1モデルとして使ったり、様々なチャレンジをしてみましたが、考えたことよりは面白い結果になったと思います。
個人的に、今回の実験で面白かったのは、CycleGANの構造を音声変換モデルとして投入した部分です。情報の特徴を理解し、その一貫性を維持するための工夫を加えることで、機械学習モデルの応用方法は新たに発展できるということを実感しました。
CycleGAN VCモデル以外にも、多:多対応向けのStarGAN VCモデルもありますので、今度はStarGAN VCの実験と今回のモデルとの比較も行ってみたいです。それでは、次の記事もお楽しみにして下さい。
Han Beomseok
Python, AI Engineering, Natural Language