
Table of Contents
モデルの紹介
最初に、関連モデルについて軽く紹介します。
Progressive GAN:
生成モデルGANで生成した画像は、他の生成モデル、例えばVAE、Flow-basedなどモデルより、画像の品質が良いですが、Ganの訓練が不安定で、Mode崩壊などの問題も頻繁に発生します。 Progressive GANはその訓練方法を工夫した手法です。最初に、低解度の画像(4x4)から訓練し、さらに高解像な画像(8x8)を生成するため、ネットワークの深さを増加して、訓練します。このようなプログレッシブな構築方法でモデルを学習することで、高解像度の画像を生成できます。概要として以下の図((論文1のFigure1)のアーキテクチャになります。
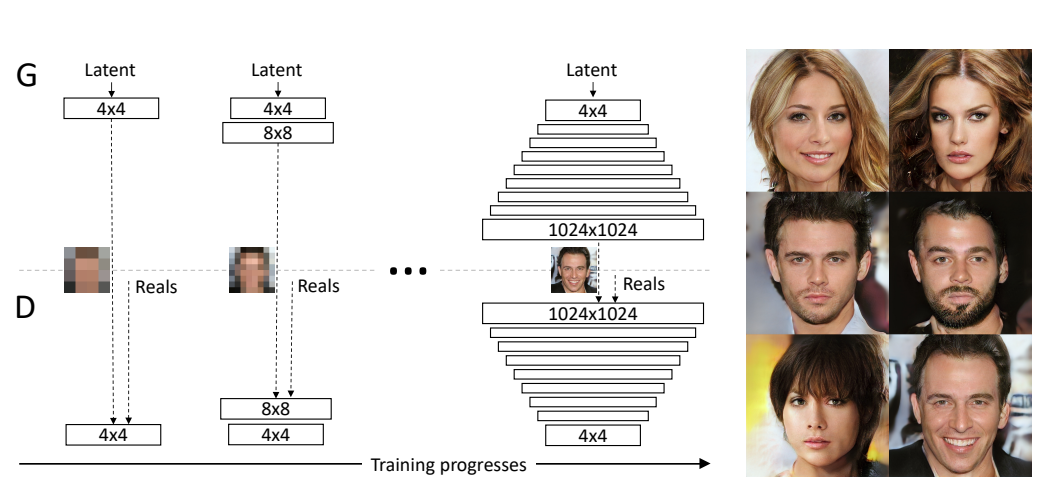
ネットワークの深さを増加する際に、他にも特殊な工夫がありますが、長くなるので省略します。
StyleGAN
Progressive GANにより、解像度が高い画像が生成することが可能となりますが、生成する画像の特徴をコントロールできません。例えば、顔画像のある特徴を少し変更したいとき、入力シードを少しだけ変換すると、生成した画像は大きな違いが出てきます。
StyleGANは、最初に、シードをMapping Networkを入力して、シードを特徴ごとに分解することで、シードの潜在空間(W)を見つけます。そして、WをSynthesis Networkに入力して、画像を生成します。アーキテクチャは下図((論文2のFigure1))のようになります。
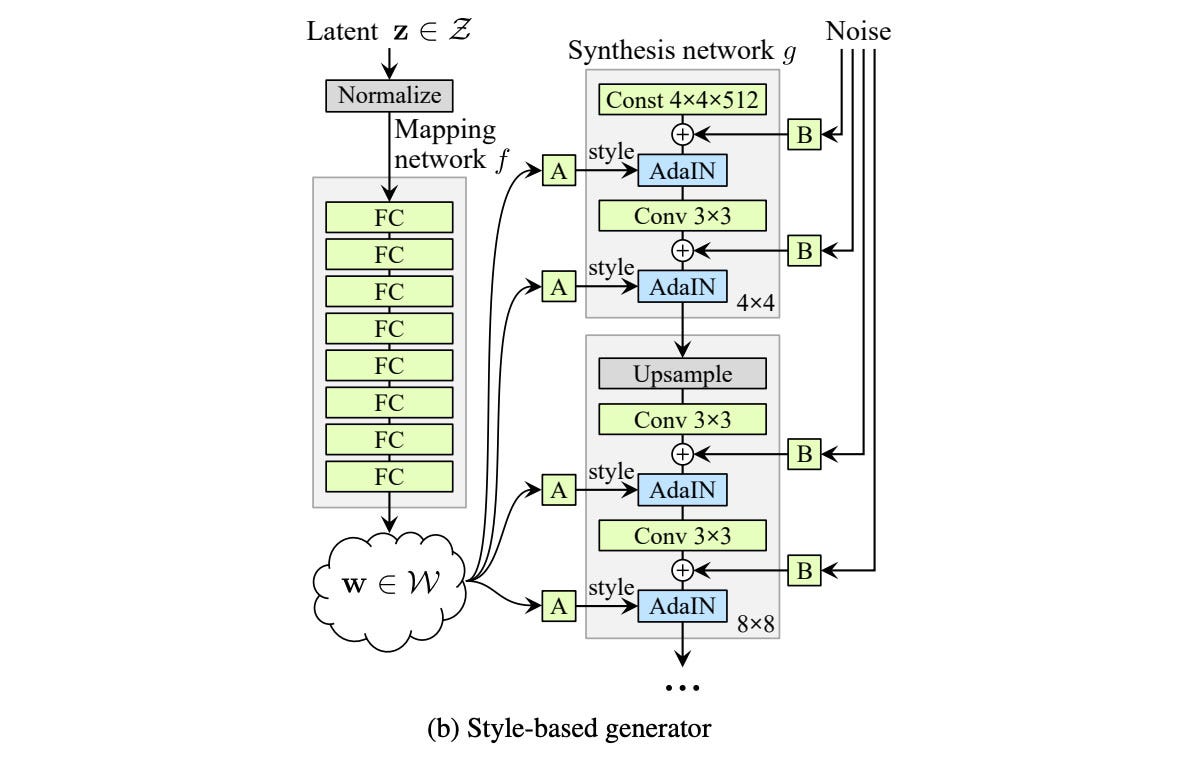
Mapping Networkは、それぞれ入り混じっている特徴を別々で分けます。別々に分けることで、特徴ごとに生成する画像をコントロールすることができます。 Synthesis Networkは、Progressive GANの構造と一緒ですが、少し違う所があります。最初の入力は変量ではなくて、定数になります。そこで、生成する画像はそれぞれ違っているため、シードの潜在空間を入力としたAdaINの出力と、それにノイズを加えたものです。 AdaINは、Wにおけるそれぞれ特徴のBias(y(b,i))とScale(y(s,i))を計算したものです(Reference from: Rani Horev)。生成した画像の詳細なところまで、品質をよくするため、ノイズを注入する必要があります。
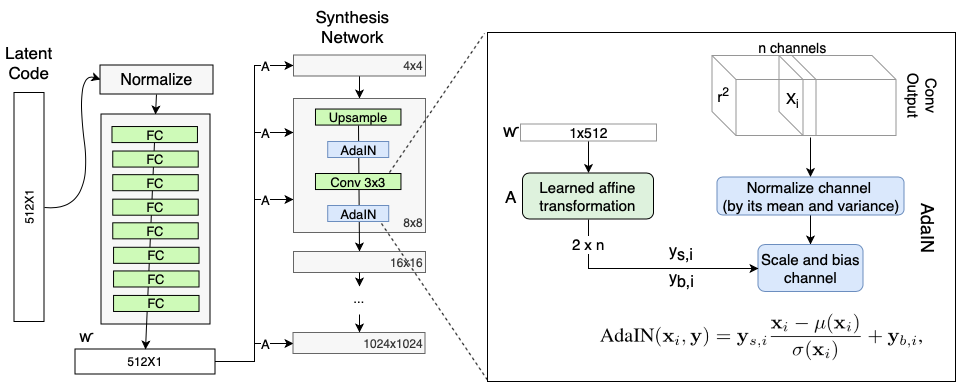
訓練では、StyleMixingという手法を使います。画像を生成する際に、2つのシードから生成した二つの潜在区間W1,W2を用いて、画像を生成することにします。Synthesis Networkのある層は、W1を用い、別の層はW2を用いるようなイメージです。生成した画像は、W1とW2各自で生成した画像の"平均"となっています。この処理により、連続する層のスタイルが相関することを防ぐことができます。
他にも、Truncationという手法や、Perceptual path lengthという指標を提案されていますが、今回は省略します。
StyleGAN2
StyleGANで生成した画像は、Water-splotchesというしみが発生する問題や、特徴の位置が固定してされてしまうなどの問題があります。それは、AdaINで起こる問題です。 StyleGAN2では、これらに対処するため、三つのアップデートがありました。
-
1.定数生成の簡略化
-
2.正規化時の、平均値の除去 (AdaINについての訂正)
-
3.ノイズの処理方法
下図はStyleGanとStyleGan2のSynthesisの部分の比較図です(Reference from: Jonathan Hui)。
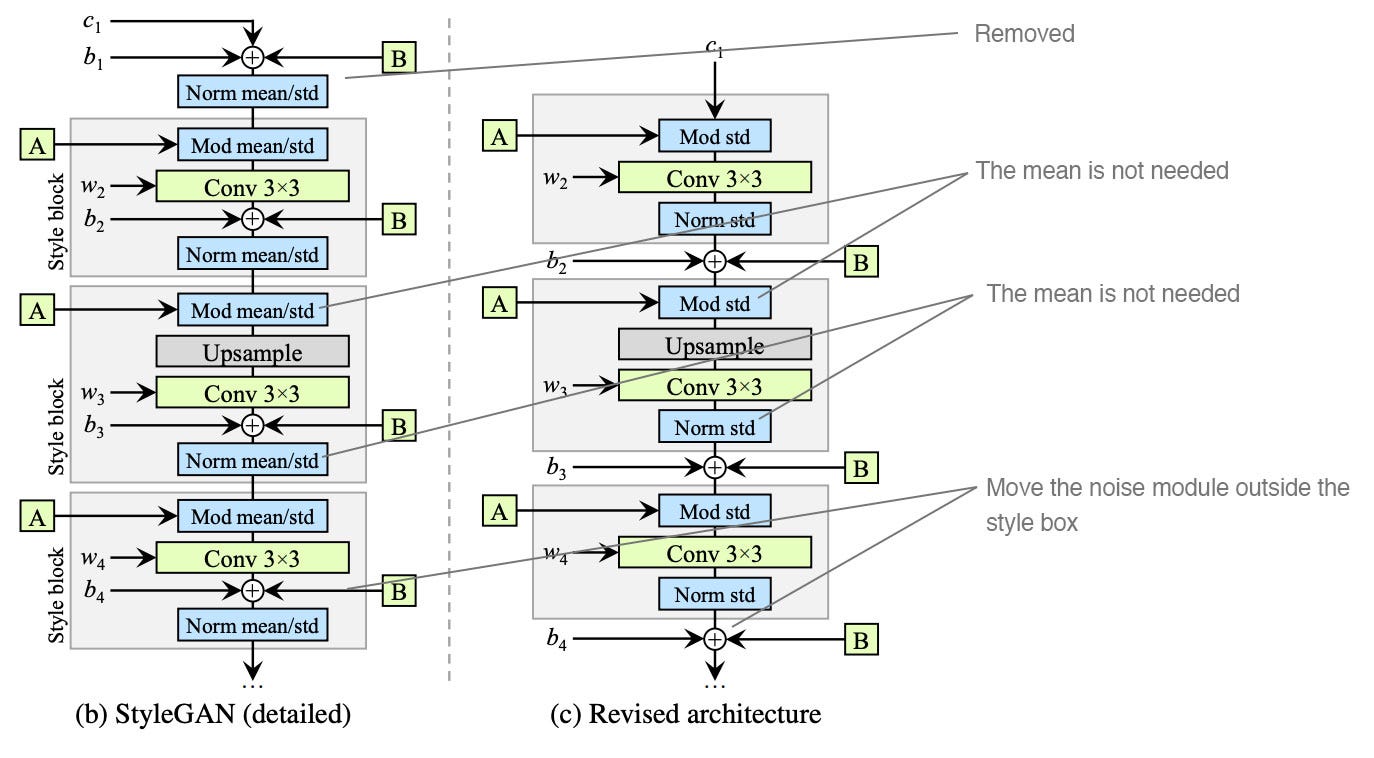
実行の流れ
普通では、シードをMapping Networkに入れて、シードの潜在空間を見つけます。そして、シードの潜在空間をSynthesis Networkに入れて、リアルの画像を生成します。そこで、シードの潜在空間を調整すれば、特徴に対応して変化した画像を生成することができます。 しかし、入力は画像ではなくシードなので、どうやって、欲しい画像の潜在空間を見つけるか問題になります。 解決策は、あるシードの潜在区間に対して、生成した画像と欲しい画像を比較して、差が小さくなる方向に潜在空間を探索していくことです。
与えた画像を潜在区間に射影します
参考資料: https://github.com/woctezuma/stylegan2-projecting-images
画像を適切に揃えます
今回利用したPre-trainedモデルFFHQにおいて、上手く射影するため与えた画像を、FFHQで訓練用のデータに合わせて整理しないといけないです。
整理していない例

整理した例

今回利用したシードは303です。生成した画像は西洋人の画像なので、推測した画像は少し違和感があります。もしかしたら、アジア男性のシードを使えば、推測した人物の画像もよくなるかもしれません。
画像を潜在空間に射影します
Github: https://github.com/NVlabs/stylegan2-ada-pytorch
射影する方法は公式の実装Sourceで、公開されています。 今回はPytorch Versionのことを使いましたが、Tensorflow Versionの方が調整できるものが多く、他の手法もあります(論文4)。
笑顔に変化するVector空間を見つける方法
参考資料: https://memo.sugyan.com/entry/2021/04/02/005434
データセットについて
ここで使うデータセットはシード600から2600まで2000個の画像と潜在空間です。画像は笑顔かどうかを判別することはpypazを利用します。推測した表情は['angry', 'disgust', 'fear', 'happy', 'sad','surprise', 'neutral']で表示して、その中でhappyが最大値となっている画像を、笑顔の画像とします。
手法について
潜在空間を取り出すことができますが、どんな数字が笑顔に対応するか問題になります。 一つずつ確認すると、種類の可能性があり、全てを列挙することが不可能です。 現状は、未知の二つの分布(笑顔画像、笑顔でなはい画像)からSamplingができます。そこで、笑顔に関わる特徴の潜在空間を推測します。もっともいいのは、任意の笑顔画像と笑顔画像ではない画像の方向(Vector)をとって,その平均を取れば、笑顔に関する潜在空間を推測できます。
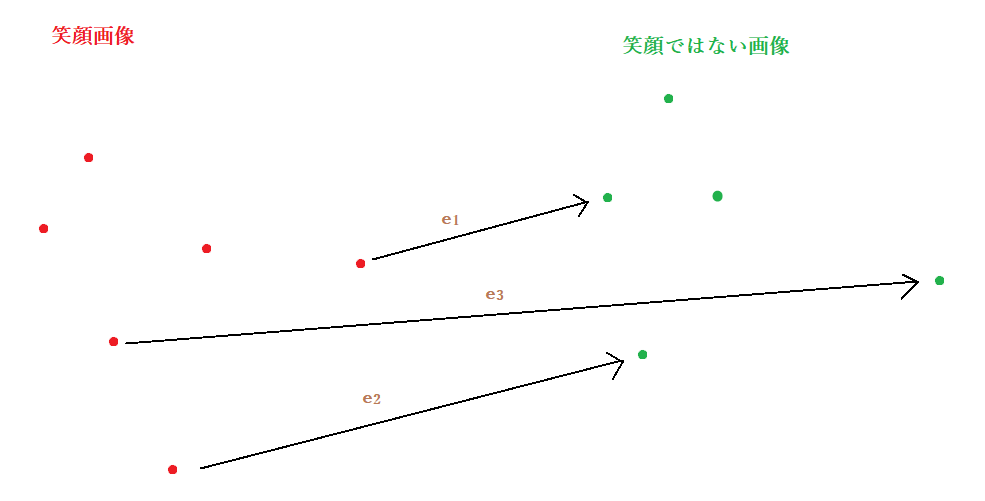
しかし、その手法は、大量のデータが必要です。まだ、512次元のVectorの計算も遅いので、時間的には厳しいです。そのため、今回は、以下の2つの手法を試しました。
平均で取れた笑顔パラメータ
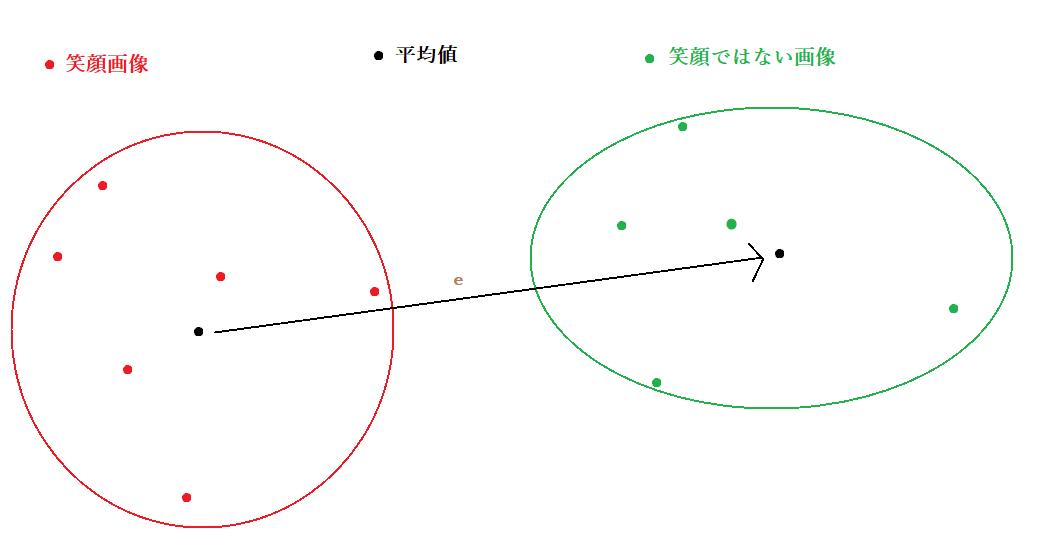
一番目の平均値を取り出すの方法は、全部Samplingした笑顔画像の潜在空間の平均値と、全画像の潜在空間の平均値を計算して、平均値の差を笑顔の特徴Vectorにします。

線形SVMで取れた笑顔パラメータ
線形SVMモデルを作って、推測した512個パラメータを笑顔の特徴Vectorとして使います。 線形SVMを作った際に、ハイパーパラメータとか調整していません。検証データ、訓練データを分けて、性能の比較などは行いませんでした。調整すれば、もっと良い結果が得られると思います。

Reference:
Progressive GANについて: https://arxiv.org/abs/1710.10196/ https://towardsdatascience.comprogressively-growing-gans-9cb795caebee
StyleGANについて: https://arxiv.org/abs/1812.04948 https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
StyleGAN2について: https://arxiv.org/abs/1912.04958 https://arxiv.org/abs/1904.03189 https://jonathan-hui.medium.com/gan-stylegan-stylegan2-479bdf256299 https://memo.sugyan.com/entry/2021/04/02/005434 https://zhuanlan.zhihu.com/p/263554045
Code Link:
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps