
Table of Contents
画像分類
以下にはcolabで実装したコードを貼っていきます。
import json
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import models, transforms
# pytorchのバージョンとかの確認
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
resnext101_32x8d = models.resnext101_32x8d(pretrained=True)
resnext101_32x8d.eval()
# 画像の入力サイズとか色合いとかは決まってるから良い感じに調整してくれるクラス
class BaseTransform():
def __init__(self, resize, mean, std):
self.base_transform = transforms.Compose([
transforms.Resize(resize),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
def reshape_image(self, img):
return self.base_transform(img)
# 1000クラスに対してそれぞれ確率が出てくるから予想した確率が一番高いとこだけ抽出するのだ
# ついでに見やすいように、indexだけじゃなくて名前も取ってきてる(親切)
class ILSVRCPredictor():
def __init__(self, class_index):
self.class_index = class_index
def predict(self, out):
maxid = np.argmax(out.detach().numpy())
predicted_label_name = self.class_index[str(maxid)][1]
return predicted_label_name
# 予測対象になる1000種類のターゲット達。(普通は.txtとかで外に置くけど今回はソースに貼っとく)
target_dict = # imagenet1000のクラスたちを辞書で読み込んでおく
# 画像の前処理のパラメータ
resize = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = BaseTransform(resize, mean, std)
predictor = ILSVRCPredictor(target_dict)
# 共通処理を括っておく
def predict_pipeline(image_path, transform, predictor):
img = Image.open(image_path)
img_transformed = transform.reshape_image(img)
plt.imshow(img)
plt.show()
img_transformed = img_transformed.numpy().transpose((1, 2, 0))
img_transformed = np.clip(img_transformed, 0, 1)
plt.imshow(img_transformed)
plt.show()
transform = BaseTransform(resize, mean, std)
img_transformed = transform.reshape_image(img)
inputs = img_transformed.unsqueeze_(0)
out = resnext101_32x8d(inputs)
result = predictor.predict(out)
print(out)
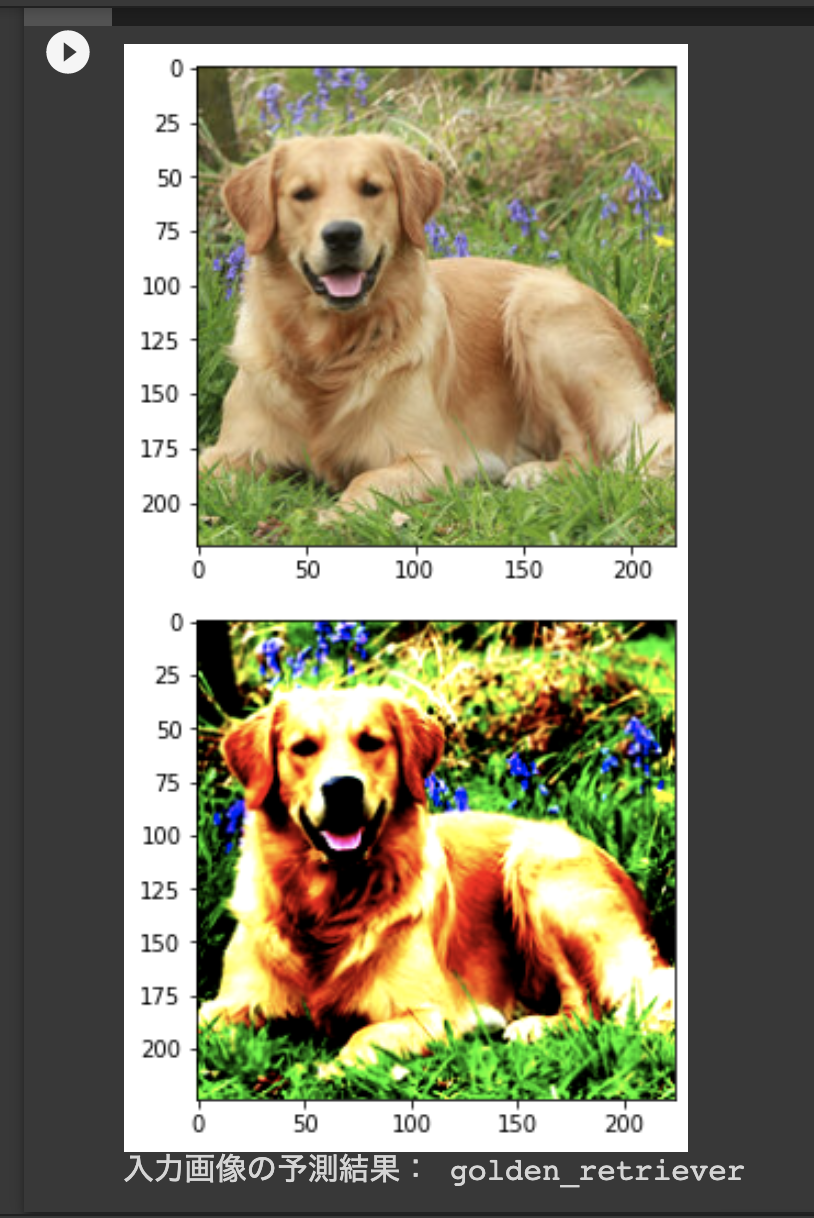
print("入力画像の予測結果:", result)
predict_pipeline("dalmatian.jpeg", transform, predictor)
ここで出力を確認してみると、1000このラベルそれぞれに対して数字が割り振られていることが確認できます。 これは、どのラベルに近いかを予測しています。 したがって、この中で最大値をもつ値のインデックスを使って出力を作っています。

predict_pipeline("/content/drive/My Drive/img/Golden_retriever.jpg", transform, predictor)
predict_pipeline("/content/drive/My Drive/img/pizza.jpg", transform, predictor)

うん、いい感じに写真に写っているものが予測されていますね。 カスタムするときはこのような重みを転移学習で利用することもできます。
物体検出 (SSDを使ってみる)
次に物体検出をやってみます。 学習とかの実装とかまで書いちゃうと、長くなるなどpre-trainedのものを利用させてもらいます。 pytorchのドキュメント見てみるとすごく簡単に使えることがわかりますね

テスト用の画像もオンラインのものを利用できるようなチュートリアルになっているので親切ですね。
precision = 'fp32'
ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision)
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
ssd_model.to('cuda')
ssd_model.eval()
uris = [
'http://images.cocodataset.org/val2017/000000397133.jpg',
'http://images.cocodataset.org/val2017/000000037777.jpg',
'http://images.cocodataset.org/val2017/000000252219.jpg'
]
inputs = [utils.prepare_input(uri) for uri in uris]
tensor = utils.prepare_tensor(inputs, precision == 'fp16')
with torch.no_grad():
detections_batch = ssd_model(tensor)
results_per_input = utils.decode_results(detections_batch)
best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
classes_to_labels = utils.get_coco_object_dictionary()
ここで、モデルの出力を確認してみましょう
best_results_per_inputの中身を確認してみると
[
[
array([[0.09026386, 0.62790495, 0.15780094, 0.70665604],
[0.63517773, 0.13941646, 0.9187331 , 0.79723686]],
dtype=float32),
array([42, 1]),
array([0.4117294, 0.9874129], dtype=float32)
],
[
array([[0.33513993, 0.5345385, 0.57696486, 0.8398038]],
dtype=float32),
array([70]),
array([0.7617591], dtype=float32)
],
[
array([[0.5390801 , 0.10348067, 0.68786484, 0.24031049],
[0.5081327 , 0.3971585 , 0.68091536, 0.870113 ]], dtype=float32),
array([10, 1]),
array([0.78971606, 0.99939513], dtype=float32)]]
それぞれに対して、3つの出力がありますね。
- バウンディングボックス
- ラベル
- confidence(自信みたいなもの)
バウンディングボックスは、表現方法が2つあるので注意が必要ですが 今回は、 (左上のx座標,左上のy座標, 右下のx座標, 右下のy座標) であることに気をつけましょう。
もう一つの表現方法として、 (中心x座標, 中心y座標, 横幅, 高さ)で出力される場合もあります
モデルの出力を見てみると、検出したオブジェクトの数だけ最初の配列に値が格納されていますね。 その数と同じだけのラベルインデックス。そのラベルへの自信が出力されています。
なので、よくみる物体検出は、入出力を整理すると 入力:画像 出力:[検出したオブジェクトの座標, 検出したオブジェクトのラベル, 確率]
このことを念頭において可視化するプログラムを見てみましょう
from matplotlib import pyplot as plt
import matplotlib.patches as patches
for image_idx in range(len(best_results_per_input)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...
image = inputs[image_idx] / 2 + 0.5
ax.imshow(image)
# ...with detections
bboxes, classes, confidences = best_results_per_input[image_idx]
for idx in range(len(bboxes)):
left, bot, right, top = bboxes[idx]
x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
plt.show()
パッと見、何が何に対応しているのやらという感じだと思いますが、 先ほど解説した出力を踏まえてこのコードを見てみると何をしているかの理解を助けられると思います。
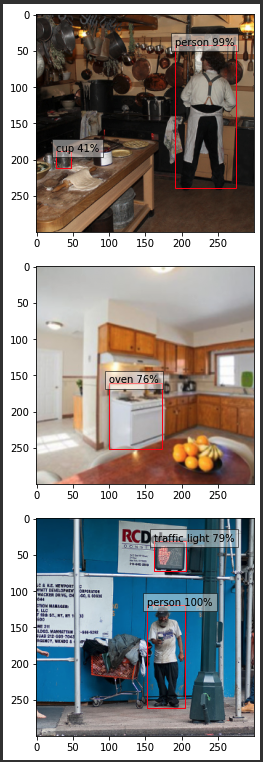
これで、他のラベルについても検出したいとなると ラベルとそのラベルのオブジェクトがどこにあるかを示す領域を教師データとして用意してあげる必要があるので、データ作成が大変そうだということが想像できると思います。
セグメンテーション
最後にセマンティックセグメンテーションを動かしてみます。 セメンティックセグメンテーションは、物体検出とはちょっと違って、ピクセル毎にどのクラスに属するのかを予測するモデルです。
こちらのコードを使います
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)['out'][0]
output_predictions = output.argmax(0)
ここで出力を確認してみましょう
np.unique(output_predictions.cpu().clone().numpy())
これをみると、0, 8, 12と出ています。
このモデルは、Pascal VOC datasetというものを使って20のラベルについて学習をしています。
なんのラベルが含まれているかはPascal VOC datasetで検索して欲しいのですが、私の経験上、よくサーバが落ちていますw
サーバが生きているうちに諸々ダウンロードしておくといいと思いますw
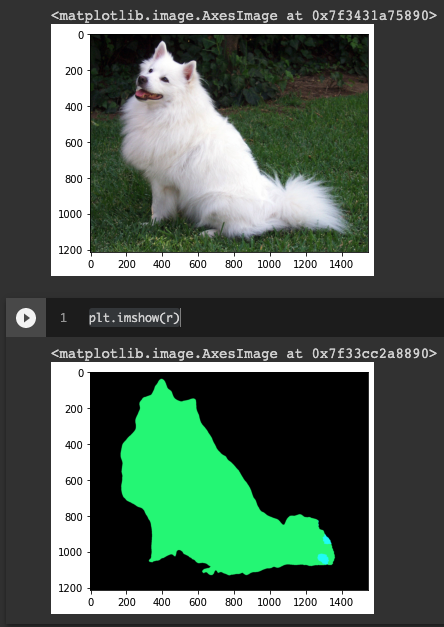
出力を確認すると巨大な二次元の行列が出てきます。 それぞれのピクセルがどのラベルに属するかが予測されています。 では可視化してみましょう
palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
colors = torch.as_tensor([i for i in range(21)])[:, None] * palette
colors = (colors % 255).numpy().astype("uint8")
# plot the semantic segmentation predictions of 21 classes in each color
r = Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size)
r.putpalette(colors)
import matplotlib.pyplot as plt
plt.imshow(input_image)
plt.imshow(r)
さて、これを自前のデータでセグメンテーションできるようにするためには、画像に対してラベルごとに色塗りをしてあげる必要があります。
物体検出のボックス作成もなかなかですが、こちらもまた骨の折れる作業です。 そこで、PFNが面白い発表をしていました。

蛍光塗料を用いて、ブラックライトで撮影をすることで、予め蛍光塗料を塗って置いたところだけが光って写るというものです。
個人的にこのアイデアは初めてみた時衝撃でした。 柔軟な思考が素晴らしいと思います。
終わりに
さて、なんしようとに書いた事例よりもちょっとプログラムによって 入出力を整理することを中心に説明をしてみました。
普段は、画像分類後、検出後、セグメンテーションして色塗りした後のものを目にすることが多かったと思いますが、入力と出力を整理することでどういう出力から実現しているのかという少し踏み入ったイメージが湧いたのではないでしょうか?
ここまでイメージできれば、入力から理想的な出力を得るためにどのような手法を使うかという工程など、どのようなフローで実現するのかなど、機械学習を見る目の解像度が上がったと思います。
本来であれば、相当な量のデータが学習に必要ですが、あらかじめ作成された重み(公開済みのものなど)を、自前のデータで転移学習することで比較的すないデータで目的を達成できることがあります。 正直、やってみないとどれくらい精度が出るのかはわからないので、こんなことやってみたいということがありましたらお気軽にお声がけいただければと思います。
ぜひ、身の回りにある写真データなどが、どのような活用ができるか考えてみてください

Ryu Ishibashi
機械学習/Vue/React/Laravelとかやってます