
Table of Contents
準備
今回の環境は以下のようになっています
- 環境:Google Colab
- モデル:BERT
- 入力:記事のタイトル
- 出力:記事のジャンル(今回は9つ)
BERTモデルはhugging faceから引っ張ってきます。 またcolab内で全て完結できるようにして実装をしていきます
実装
最初に、colabのランタイムをGPUにしておいてください。
パッケージなどの準備をします
# transformerのインストール
!pip install transformers
# Mecabのインストール
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3
# fugashi
!pip install fugashi ipadic
次にimportやGPUを使う準備等をします。
必要なデータもここでダウンロードします。
import os
import urllib.request
import re
import csv
import tarfile
import torch
import numpy as np
import pandas as pd
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# データのダウンロード(カレントディレクトリに圧縮ファイルがダウンロードされる)
urllib.request.urlretrieve("https://www.rondhuit.com/download/ldcc-20140209.tar.gz", "ldcc-20140209.tar.gz")
# ダウンロードした圧縮ファイルのパスを設定
tgz_fname = "ldcc-20140209.tar.gz"
#処理をした結果を保存するファイル名
tsv_fname = "all_text.tsv"
次がちょっと改造をしたところです。 辞書を用意して、それぞれのキーで配列を用意しています。
target_genresは辞書内に存在するキーのリストをもつので、使わないものを消せばよしなに反映されます。
# 分類したい種類の対象や数はここで調整する
fname_class_list = {
"dokujo-tsushin": [],
"it-life-hack": [],
"kaden-channel": [],
"livedoor-homme": [],
"movie-enter": [],
"peachy": [],
"smax": [],
"sports-watch": [],
"topic-news": []
}
target_genres = list(fname_class_list.keys())
いよいよデータに前処理を施していきます ここでは先ほど作成した
- fname_class_list
- target_genres
を利用しているので、よしなに作成されます。 ただ、indexは変わる可能性があるので、変更時はどのインデックスがどのカテゴリに対応しているのかをしっかり確認しましょう。
def remove_brackets(inp):
# 記号とかを除く
brackets_tail = re.compile('【[^】]*】$')
brackets_head = re.compile('^【[^】]*】')
output = re.sub(brackets_head, '', re.sub(brackets_tail, '', inp))
return output
def read_title(f):
# 2行スキップ
next(f) # URL
next(f) # タイムスタンプ
title = next(f) # 3行目を返す:タイトル
title = remove_brackets(title.decode('utf-8'))
return title[:-1]
# all_text.tsvを作る
with tarfile.open(tgz_fname) as tf:
# 対象ファイルの選定
for ti in tf:
"""
・ライセンスファイルはスキップ
・genre内のtxt意外ならスキップ
・txtファイル意外ならスキップ
・用意したgenre意外ならスキップ
"""
if "LICENSE.txt" in ti.name:
continue
if len(ti.name.split('/')) < 3:
continue
if not ti.name.endswith(".txt"):
continue
genre = ti.name.split('/')[1]
if not genre in target_genres:
continue
genre_index = target_genres.index(genre)
fname_class_list[target_genres[genre_index]].append(ti.name)
with open(tsv_fname, "w") as wf:
writer = csv.writer(wf, delimiter='\t')
for i, genre in enumerate(target_genres):
for fname in fname_class_list[genre]:
f = tf.extractfile(fname)
title = read_title(f)
row = [genre, i, title]
writer.writerow(row)
では、作成したデータを確認してみましょう
nanが含まれるデータは今回は捨てておきます。
# 作成したデータの読み込み
df = pd.read_csv("all_text.tsv", delimiter='\t', header=None, names=['media_name', 'label', 'sentence'])
df = df.dropna(how='any') # nanのところは落とす
# データの確認
print(f'データサイズ: {df.shape}')
display(df.sample(10))
"""
データサイズ: (7325, 3)
media_name label sentence
317 dokujo-tsushin 0 うっとうしい? うらやましい? 自分好きな人
1989 kaden-channel 2 一晩平均30通!? アメリカのティーンはケータイしすぎで睡眠不足
7213 topic-news 8 AKB指原莉乃の衝撃交際報道、小林よしのり氏の見解は?
2754 livedoor-homme 3 サラリーマン必見!素人最強軍団「あやまんJAPAN」が語る“飲み会の極意”とは!?
6698 topic-news 8 韓流モンスター番組の生放送決定、ネット上の反応は?
5346 smax 6 Google、Android 4.1 JellyBeanのソースコードを公開!Nexu 7と...
2226 kaden-channel 2 新時代の「カセット」持ち運び自由なHDDを楽しめ!日立マクセルからiVプレーヤー新発売
5370 smax 6 NTTドコモの女子力アップスマートフォン「F-09D ANTEPRIMA」に内蔵されている豊...
6780 topic-news 8 フジテレビ「FNS歌謡祭」で機材トラブルか 嵐の生歌に批判殺到
6774 topic-news 8 原発用語の言い換えに「騙されるな!」
"""
いい感じにできてますね
では、BERTが読めるようにしていきましょう
BERTは一度に512トークンまでしか読めないので気をつけましょう
# モデルに飲ませるデータと、ラベルを準備
sentences = df.sentence.values
labels = df.label.values
# トークナイズする
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
## 確認
print(' Original: ', sentences[0])
print('Tokenized: ', tokenizer.tokenize(sentences[0]))
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
"""
Original: 友人代表のスピーチ、独女はどうこなしている?
Tokenized: ['友人', '代表', 'の', 'スピーチ', '、', '独', '女', 'は', 'どう', 'こなし', 'て', 'いる', '?']
Token IDs: [3676, 542, 5, 22130, 6, 569, 335, 9, 1704, 12056, 16, 33, 2935]
"""
# 最大トークン数の確認
max_len = 0
# 1文づつ処理
for sentence in sentences:
# Tokenizeで分割
token_words = tokenizer.tokenize(sentence)
# 文章数を取得してリストへ格納
if len(token_words) > max_len:
max_len = len(token_words)
# 最大の値を確認
print('最大単語数: ', max_len)
print('上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数')
"""
最大単語数: 74
上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数
"""
最大トークン数が74 + 2なので今回は、このまま使って良さそうですね。
では、いよいよトークナイズ処理をかけて入力データを作ります
ここでは、max_lengthなどを変数で表現しているので、動的に設定が可能なので何も考えずにプログラムにお任せできるようにしました。
input_ids = []
attention_masks = []
# 1文づつ処理
for sentence in sentences:
encoded_dict = tokenizer.encode_plus(
sentence,
add_special_tokens = True, # Special Tokenの追加
max_length = max_len + 2, # 文章の長さを固定(Padding/Trancatinating)
pad_to_max_length = True,# PADDINGで埋める
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
input_ids.append(encoded_dict['input_ids'])
attention_masks.append(encoded_dict['attention_mask'])
# リストに入ったtensorを縦方向(dim=0)へ結合
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
# tenosor型に変換
labels = torch.tensor(labels)
# 確認
print('Original: ', sentences[0])
print('Token IDs:', input_ids[0])
データローダーなどを用意します。
from torch.utils.data import TensorDataset, random_split
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
dataset = TensorDataset(input_ids, attention_masks, labels)
# 90%取得
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# データセットを分割
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('訓練データ数:{}'.format(train_size))
print('検証データ数: {} '.format(val_size))
# データローダーの作成
batch_size = 32
# 訓練データローダー
train_dataloader = DataLoader(
train_dataset,
sampler = RandomSampler(train_dataset), # ランダムにデータを取得してバッチ化
batch_size = batch_size
)
# 検証データローダー
validation_dataloader = DataLoader(
val_dataset,
sampler = SequentialSampler(val_dataset), # 順番にデータを取得してバッチ化
batch_size = batch_size
)
from transformers import BertForSequenceClassification, AdamW, BertConfig
# BertForSequenceClassification 学習済みモデルのロード
model = BertForSequenceClassification.from_pretrained(
"cl-tohoku/bert-base-japanese-whole-word-masking", # 日本語Pre trainedモデルの指定
num_labels = len(target_genres), # ここもよしなに反映される
output_attentions = False, # アテンションベクトルを出力するか
output_hidden_states = False, # 隠れ層を出力するか
)
# モデルをGPUへ転送
model.cuda()
いよいよ学習です。
from torch.nn import functional as F
# 最適化手法の設定
optimizer = AdamW(model.parameters(), lr=1e-5)
# 訓練パートの定義
def train(model):
model.train() # 訓練モードで実行
train_loss = 0
for batch in train_dataloader:# train_dataloaderはword_id, mask, labelを出力する点に注意
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
optimizer.zero_grad()
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = F.cross_entropy(outputs.logits, b_labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
train_loss += loss.item()
return train_loss
# テストパートの定義
def validation(model):
model.eval()# 訓練モードをオフ
val_loss = 0
with torch.no_grad(): # 勾配を計算しない
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
with torch.no_grad():
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = F.cross_entropy(outputs.logits, b_labels)
val_loss += loss.item()
return val_loss
# 学習の実行
max_epoch = 4
train_loss_ = []
test_loss_ = []
for epoch in range(max_epoch):
train_ = train(model)
test_ = validation(model)
print(f'epoch {epoch} loss : {test_}')
train_loss_.append(train_)
test_loss_.append(test_)
さあ、お楽しみの正解率をみてみましょう
model.eval()# 訓練モードをオフ
try_count = 0
correct_count = 0
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
with torch.no_grad():
# 学習済みモデルによる予測結果をpredsで取得
preds = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
logits_df = pd.DataFrame(preds[0].cpu().numpy(), columns=['logit_0', 'logit_1', 'logit_2', 'logit_3', 'logit_4', 'logit_5', 'logit_6', 'logit_7', 'logit_8'])
pred_df = pd.DataFrame(np.argmax(preds[0].cpu().numpy(), axis=1), columns=['pred_label'])
label_df = pd.DataFrame(b_labels.cpu().numpy(), columns=['true_label'])
result_df = pd.concat([logits_df, pred_df, label_df], axis=1)
df_bool = result_df['pred_label'] == result_df['true_label']
try_count += df_bool.shape[0]
correct_count += sum(df_bool)
print(f'accuracy = {correct_count/try_count}')
僕の環境では82%ほどでした。 いろいろ工夫をすればまだまだ正答率をあげる余地はありそうですね。
future work
データオーギュメンテーションなどは一番効果がありそうな気がします。
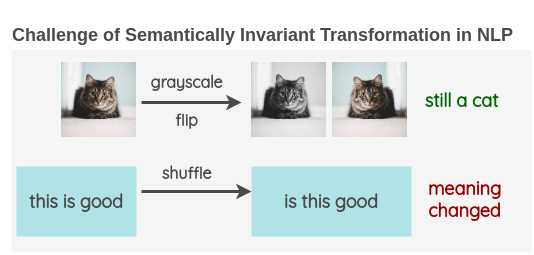
こちらにデータオーギュメンテーションの方法がまとめられています。
英語での手法なので真似できないこともいくつかありますが、使えるテクニックもたくさんあります。

Ryu Ishibashi
機械学習/Vue/React/Laravelとかやってます