
Table of Contents
複数チャネルの音源分離
複数のマイクロホンを用いて収録した複数チャネルの混合音は、音の到達時間差などから音源方向を推定できるため、容易に音源分離が可能です。また、マイクロホン同士の相対位置が未知の場合や、残響がある空間での収録音に対しても、機械学習を用いれば対処可能です。この複数チャネルの混合音の分離に関しては、Pythonで学ぶ音源分離という名著が出版されています。独立低ランク行列分析(Independent Low-Rank Matrix Analysis; ILRMA)など統計的モデリングによる音源分離の最新手法が記載されており、読み応えがありました。
単一チャネルの音源分離
一般的に多くの収録音は、単一チャネルであることが多いです。それは、複数チャネルの収録には、複数マイクロホンの機材が必要で、昨今のデバイスの小型化の傾向からハードルが上がっていることも理由の一つだと思います。しかし、単一チャネルの混合音を分離することは、各音源の特徴を用いて分離する必要があり、とても難しいです。そのため、最近は、深層学習によりニューラルネットワークを学習させることで複雑な音源特徴をモデリングし音源分離を行う研究が活発に行われています。
そして、この度、Attention is All You Need in Speech SeparationというAttentionを用いた音源分離手法が発表されました。
Attention is All You Need in Speech Separation
この論文では、SepFormer(Separation Transformer)というRNNを用いないTransformerに基づく音源分離ニューラルネットを提案し、音源分離で最先端の性能を示しています。
Transformerには、以下の利点があります。
- 短期、長期の情報依存関係を学習できる
- RNNは逐次的なモデルで計算の並列化が困難であるが、Transformerは並列化が可能
RNNは、昨今の音声処理システムにおいて重要な要素となっており、音声認識、音声合成、音声強調など様々な分野で使用されています。しかし、RNNの再帰処理により逐次的な計算が必要なため、計算の効率的な並列化が難しく、長いシーケンスを持つ大規模データセットを処理するのが困難になります。
Transformerでは、その再帰処理を排除し、Attentionベースの処理に置き換えることで、このボトルネックを排除しています。
RNNによる音源分離の研究として、Dual-Path RNN (DPRNN)にて、分離性能を向上させるためには、より良い長期モデルを作成することが重要であることが示されています。そこでは、ローカル特徴を扱うRNNとグローバル特徴を扱うRNNの2段階のRNNを用いることで達成していました。しかし、RNNを使用しているため、グローバル特徴のモデリングに関する限界があるという課題がありました。
SepFormerでは、DPRNNで導入されたDual pathフレームワークを使用し、RNN部分をTransformerに置き換えたものです。大まかなアーキテクチャは、下図(論文中Fig. 1)のようになっています。
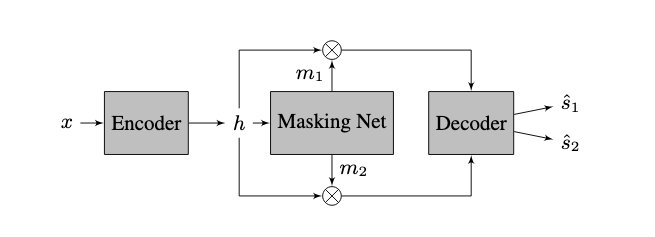
Encoder, Decoder部分では、Conv1Dを用いて、時間領域の混合音とSTFT(短区間フーリエ変換)による周波数領域に似た表現への変換を行っています。
Masking Networkは、encoderにより変換されたを入力とし、分離対象()の音源ごとにmask()を推定します。maskは、encoder表現が周波数表現とすると、各周波数を音源に割り当てるかどうかを表しています。このことから、Decoder部分では、で時間領域の音源()が計算されます。
Masking Network
Masking Networkは、以下の図(論文中 Fig.2)のようなアーキテクチャーになっています。一番上の図がMaskingNetwork、中段がTransformerを使用しているSepFormer Block、下図が中段のIntra&Inter Transformerに関する図です。
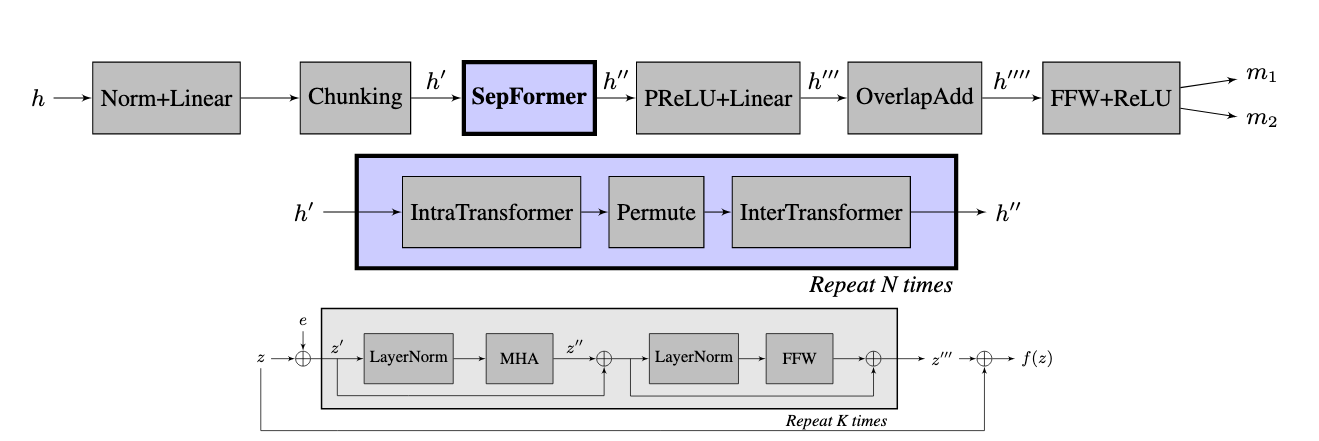
まずは、大まかなネットワーク(上図の上段)について説明します。
-
Norm+Linear+Chunking
Layer Normalizationで正規化し、Linear layerを通した後、時間方向に50%オーバラップさせて分割したチャンクを作成します。 -
SepFormer Block
上図の中段の図です。詳細は、後ほど説明します。 -
PReLU+Linear
PReLU(Parametric ReLU)は、Leaky LeRUの拡張版で、0より下の値の出力は入力値をα倍した値をしたもののとなり、このαも学習対象にした部分が拡張部分です。PReLUで処理した後、Linear Layerで処理することで、SepFormerで計算されたmask表現に関する特徴を各音源ごとに割り当てるように変換します。 -
OverlapAdd
50%オーバラップさせて作成したチャンク情報を時間情報に戻します。 -
FFW+ReLU
3, 4で得られたmask表現に対して、feed forward layerとReLUの処理を行うことでmask()を計算します。
SepFormer Block
SepFormer Blockは、上図の中段のようにIntraTransformerとInterTransformerで構成されます。IntraTransformerは、短期間の依存性をモデル化し、InterTransformerは長期依存性をモデル化します。
Intra&Inter Transformerの構造は、上図の下段です。を各Transformerへの入力とします。まず、で入力に位置情報を表現したPositional encoding ()を加えます。その後、Layer Normalizationにて正規化され、Multi Head Attention(MHA)へ入力されます。MHAがAttention部分です。その後、Layer Normalizationで正規化し、Feed Forward Layer処理が行われます。これらの処理は、図の通り部分的にresidual connectionの構造になっており、勾配逆伝搬の改善に寄与しています。
実際に試してみた
SepFormerがHugging Faceにて公開されていたので、実際に試してみました。

下図の上段が男性と女性の声を混合した単一チャネル混合音のスペクトログラムです。中段、下段は、それぞれ男性と女性の正解音声、SefFormerによる分離音のスペクトログラムです。混合音は、それぞれの正解音を合成して作成しました。分離音と正解音を見比べると、かなり精度良く分離できていることが見てとれます。

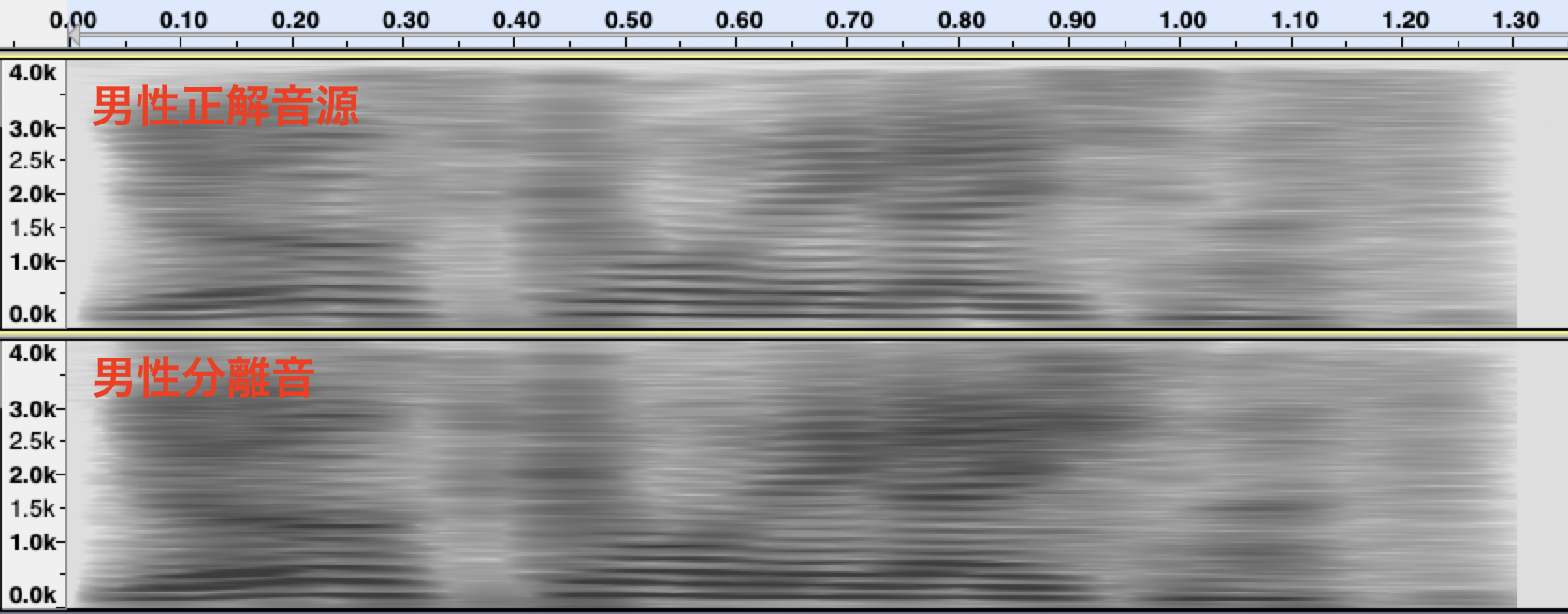
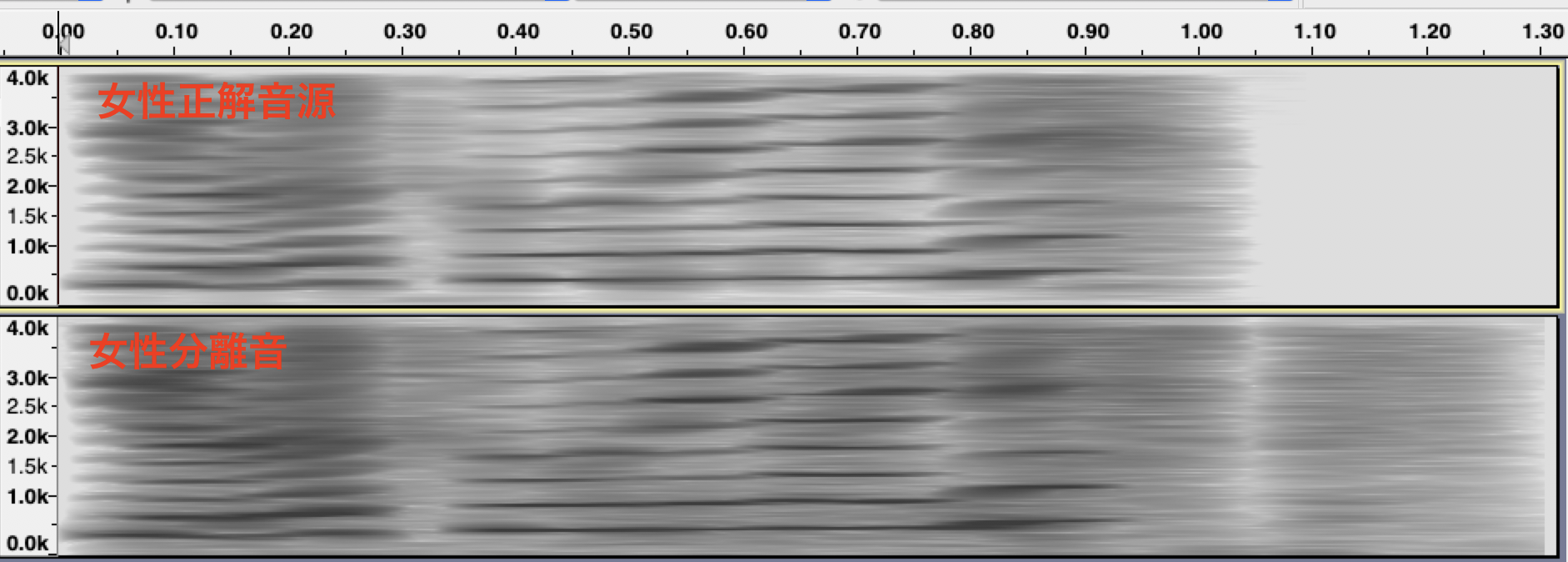
他にも、私の声で、異なる発話パターンを重ね合わせた混合音の分離を試してみました。結果は、芳しくなく、これは、音声の特徴が似た発話が重なると分離できないことを示しています。SepFormerを含め音声の特徴で分離する手法は、このパターンの分離が困難です。しかし、単一チャネルの音源分離を同様に人間が行った場合に、聴き比べられるかというと、とても難しい課題だと思います。
まとめ
今回は、Atteintionを音源分離に適用する手法を試してみました。学生時代、統計的な音源分離について研究していましたが、深層学習でここまで精度が出るのは、とても驚くべき進展だと思います。一方で、複数マイクロホンで収録できる場合は、方向情報も用いることができるので、深層学習ほどの複雑なモデリングが必要なく、ある程度良好な結果が得られると思います。
しかし、学生時代に難しいと思っていたことが、可能になったように、複数マイクロホンにおいても、面白く驚くべき研究がでてくるかもしれないと期待しています。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps