
Table of Contents
近年Vision and Languageのpre-trainedモデルを用いた事例が少しずつ増えてきています。
ViLBERTを皮切りに、OscarやUNITERなど様々なモデルが提案されてきました。 しかし、これらのモデルで画像の特徴抽出では物体検出などを用いており、そこが処理速度におけるボトルネックになっていました。
実際僕もText Image Retrievalの機能をViLBERTで実装した際には処理速度が問題になるなと思った経験があります。
そんなときに、2021のICMLでViLTなるものを見つけました。 どうやたViTをベースにしているらしいのですが、かなり高速らしく10倍近くも高速化されるとのこと。 気になるのでちょっと論文を読んでみます。
従来手法の課題
論文内では従来手法の課題として以下の点が挙げられています
- 効率さ、速度に課題がある。特に画像の特徴抽出はマルチモーダルなインタラクションの計算部分よりも計算コストがかかっている
論文の図1でわかりやすい図が載ってました
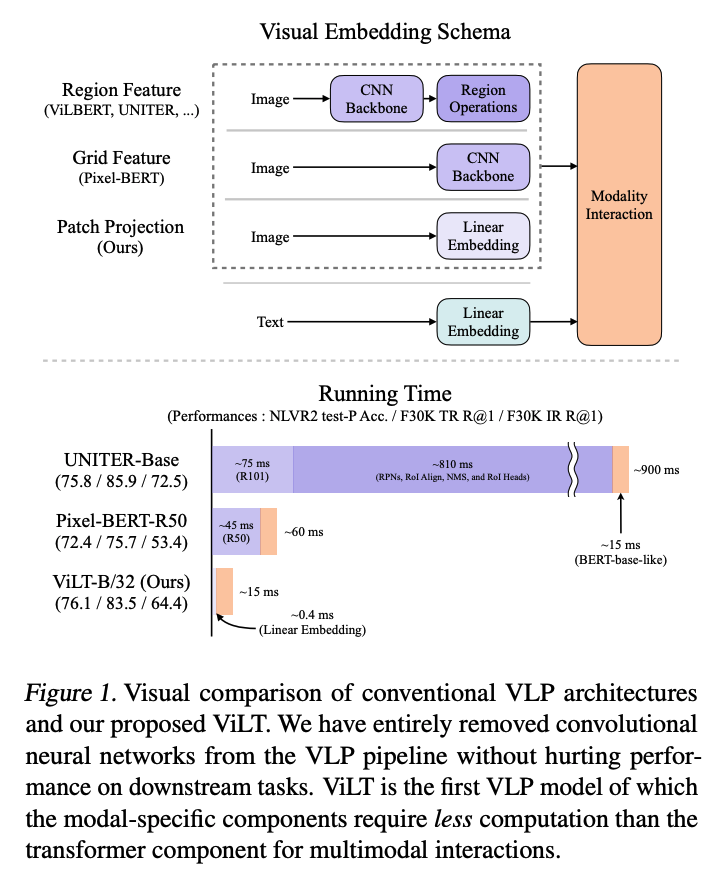
有名なViLBERTとかであれば一番上のものが該当しますね CNNで特徴抽出を行ってその結果をModality Interactionの層に入力するという流れが、これまでは一般的でした。
図1の下半分を見てみるとそれぞれのパートでどれくらいの実行時間がかかるのかが見て取れます。 この図の紫の部分が画像を処理している時間になります。 これをみるとほとんどの時間は画像を処理している時間ということになりますね。
今回提案されたViLTではCNNを使わず、画像をpatchに分解し、Linear projectionに通して特徴抽出をするという手法をとっています。 これは、2020 ~ 2021年にかなり話題になったViTと同じ考え方を利用しています。 ViTはSoTAを更新しつつもpre-trainにかかる時間がTPUを使用したときにBiTと比較して数倍 ~ 十数倍ほども早かったこともあり、話題になったモデルです。
ちなみにViLTの論文はこちら
ViTの論文はこっち
日本語ではこの解説記事が分かりやすかったです

Background
ここではVision and Languageのモデルたちを以下の2つの着眼点に基づき分類をしています。
- 2つのモダリティが専用パラメータや計算量において同程度の表現力を持つかどうか
- 2つのモダリティがdeep networkで相互作用するかどうか
Fig.2を見てみます
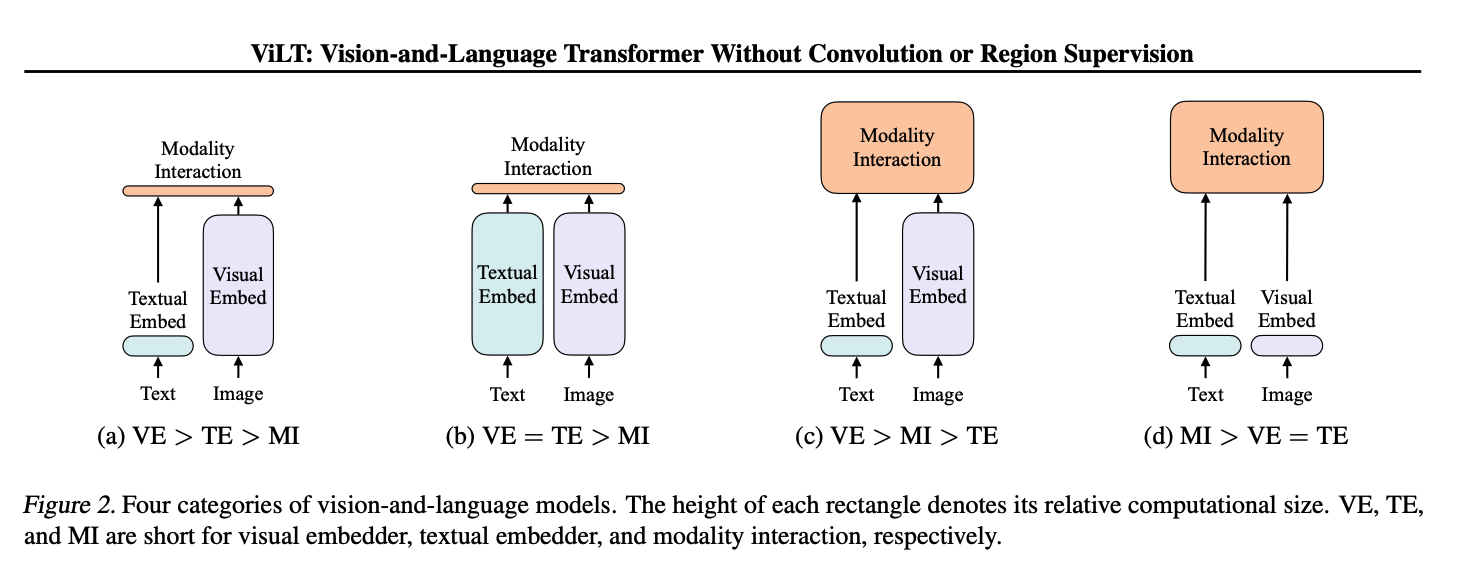
(a)は
画像埋め込み > テキスト埋め込み > モダリティ計算 の順に計算量や表現力の規模が大きいタイプのモデルになります。
これにh該当するモデルとしては
- VSE
- VSE++
- SCAN
などが該当します。
(b)は
画像埋め込み = テキスト埋め込み > モダリティ計算
となっており画像の埋め込みとテキスト埋め込みの計算量や表現力が同程度で、モダリティの表現力がそれに次ぐというような大小関係のモデルになります。
これに該当するモデルとして
高いZero Shot性能で話題になったCLIPが挙げられています
(c)は 画像埋め込み > モダリティ計算 > テキスト埋め込み の順に計算量や表現力の規模が大きいタイプのモデルになります。
近年のVLPモデルたちはここに該当すると論文内で書かれているので
- ViLBERT
- UNITER
- Oscar
などがここに該当すると思われます。
(d)は
今回提案されているViLTが該当するものになります。
モダリティ計算が最も大きな部分になり、画像の埋め込みとテキスト埋め込みは比較的小さな部類になります。
モデル構造
論文内のFig3にモデルの全体像が描かれています。 特筆すべきは右側の画像をパッチに分解してLinear projectionを用いてTrainsformer Encoderに入力していることですね。これが高速化に寄与しているそうです。
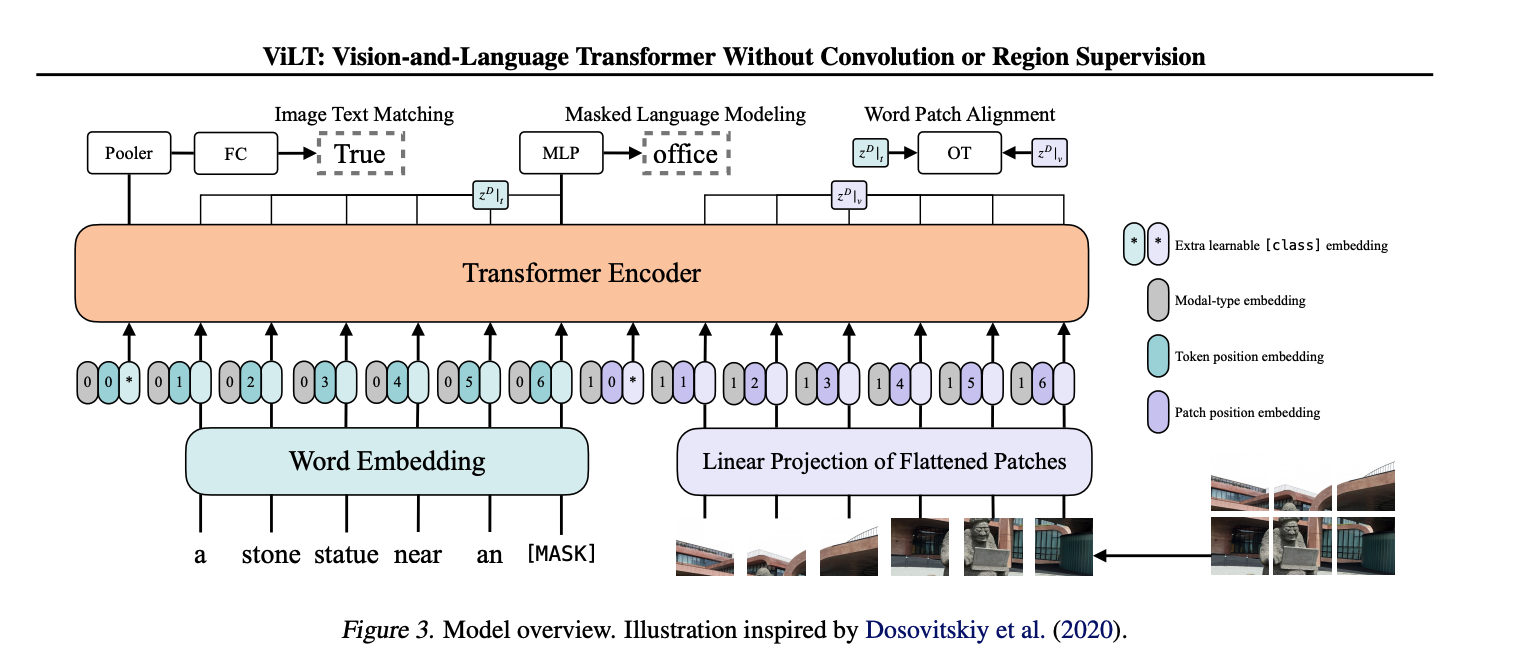
実装はgithubで公開されています。
この辺りとかを見てみると、text_embeddingにはBERTが使われていること
これを見てみると、画像の特徴抽出ではViTのコードが利用されていることが分かりますね
pre-training task
ViLTもBERTなどのようにpre-trainedモデルが公開されていて、それをfine tuningすることで任意の下流タスクを学習させることが多いと思います。
では、自分たちが直接やることはあまりないと思いますがpre trainで何やっているかだけはざっと把握しておきましょう。
論文の3.2章を見てみると
- ITM(image text matching)
- MLM(masked language modeling)
と書いてあります。
ITMに関しては、50%の確率でランダムにテキストを置き換えて、画像とテキストがペアのものかどうかを学習します(BERTのNSPに似ていますね)
MLMはBERTと同じですね。
使用されているデータセットは
- MSCOCO
- Visual Genome
- SBU Captions
- Google Conceptual Captions
の4つです。 どれもcaptioningなど、文字と画像のペアデータセットととしてはよく見かける面々ですね。
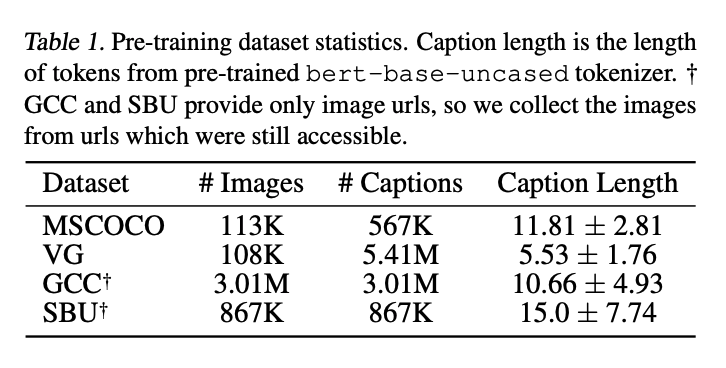
それぞれのデータセットの規模感についてはTable1で紹介されています
合計で
画像:約400万枚
テキスト:約1000万文
を用いて学習しているのですね
結果
モデルをretrievalタスクでfine tuningした結果がtable4にあります (他にも色々なパターンがあるので時間がある人はぜひ他の表も眺めてみてください)
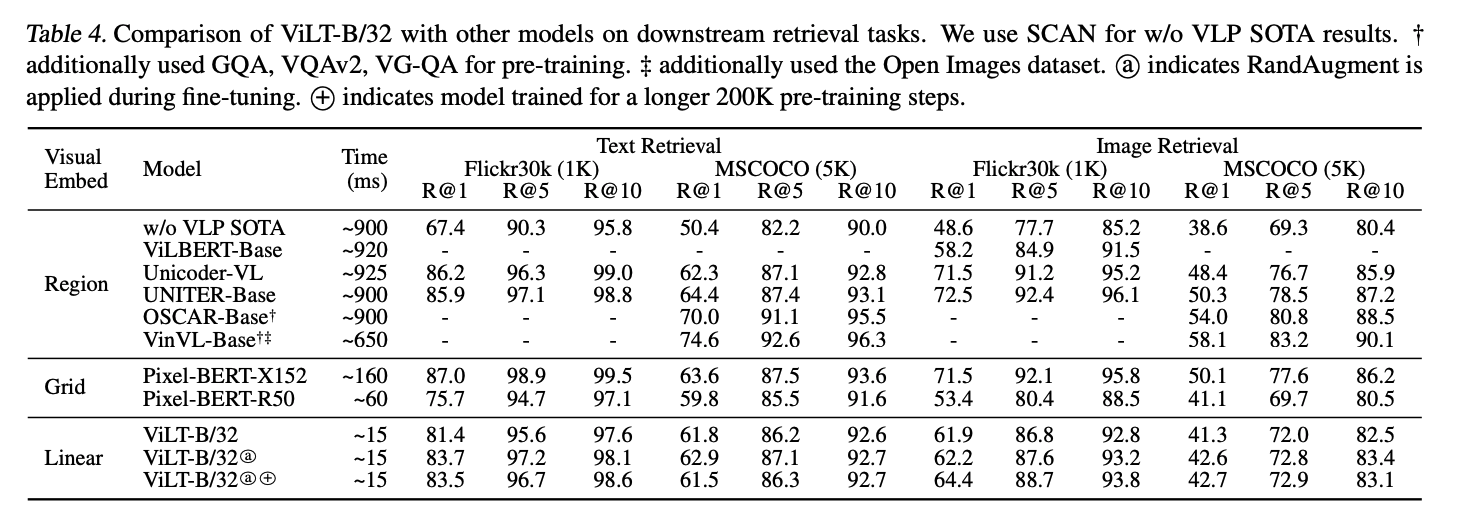
これをみると、ViLTがViLBERTなどと比較して60倍ほど高速であることが分かりますね。
(ちなみにですが、ViLBERTのgithubで公開されている実装を見てみると予め特徴抽出したデータはlmdbに保存してそこから読み出すという実装がされています。なのでアプリケーションにViLBERTを組み込んだ際にはもしかしたらViLBERTはこれより少し早い可能性があるかもなぁと思ったりもしました。)
この表をみるとViLTはViLBERTやUNITERなどと同程度(ここはかなり主観が入りますがw)の精度を持ち合わせながらも数十倍高速であるということが見て取れます。
論文内では、文章中の単語と画像内のどこが関連性がありそうかの可視化がされています(各tokenとパッチの関連性)
Fig.4を見てみましょう

これをみてみると、確かに単語が、画像内で注目すべきところが人間の感覚に比較的近いことが分かりますね。
物体検出をしているわけではないので、学習時には画像内のどこがどの単語とペアになっているかは与えていないはずなのに、大量のデータからそれぞれを学習しているということなんでしょうかね? すごく賢いですねw
Conclusion
結論のパートを見てみるとまだまだ精度向上の可能性があることが示唆されています。
BERTなどpre trainedモデルのpre trainデータセットの規模としては今回用いた4つのデータセットを合わせても同規模とはまだまだいえません。 そのため、データセットがもっと増えて大規模になり、モデルサイズも大きくすればさらに精度向上の可能性があるそうです(GPTとかがそうでしたね)。
この論文を読んでみて
Vision and Languageの領域はまだまだビジネス分野では公開事例が少ないですが、今後非常にインパクトのある技術だと個人的には思っています。
これまでの機械学習プロジェクトでは、画像 or 自然言語のように単一の情報だけを考えることが主でしたが、画像とテキスト両方の関係性を同時に考えたいということもちょくちょくあります。
例えば、身の回りではtwitterやinstagramなどの投稿では画像とテキストがペアになっていることが多いですね。 その中で任意の基準でツイートや投稿を分析することで面白い視点が得られるかもしれません。
他にも、youtubeの動画の再生数に対してサムネとタイトルは非常に大きな影響を及ぼすと考えられます。youtubeの再生数を伸ばすためのサポートツールとしてサムネとタイトルを評価するモデルだったり、逆にタイトルを入力すると最適なサムネ候補から探してきてくるなんてこともできるかもしれませんね。
さらに、生成系のモデルと組み合わせるとタイトルを入力すると最適なサムネを自動生成するなんてことも将来的にはできるのかもしれませんね。
こんな感じで、身の回りには画像とテキストが相互作用をしている事例がたくさんあります。 そんなときに、ViLTなどのマルチモーダルな情報を扱える機械学習モデルは非常に興味深い選択肢になる可能性を秘めています。
ぜひ、色々な実験をしてみたいですね

Ryu Ishibashi
機械学習/Vue/React/Laravelとかやってます