
Table of Contents
こんにちは、初めましての人は初めまして。機械学習チームの瓦です。
つい先日、SageMaker Serverless Inferenceについての発表がありました。クラスメソッドさんの記事にもまとめられているように、アイドルタイムには課金されないので、予測不可能なトラフィックを持つアプリケーションなどで使う場合にとても役立ちそうな機能です。このブログでは、新しく追加されたこの機能を試してみたいと思います!
ざっくり概要
ECR に登録したコンテナで SageMaker にモデルをデプロイし、サーバレスで推論できるエンドポイントを作りました。
サーバレスなエンドポイント作成までの流れ
コンテナの準備
エンドポイントからコンテナへは、ヘルスチェックと推論のリクエストが来ます。
- ヘルスチェックで
/pingが叩かれる - 推論で
/invocationsが叩かれる
ため、その二つを用意しておくことが大事です。今回は、fastapiでその二つを用意しました。
Dockerfile は以下のものを準備しました。
FROM python:3.8.6
MAINTAINER Yuki Kawara <kawara@fusic.co.jp>
ARG WORKINGDIR="/workspace/"
RUN apt-get -y update && apt-get install -y --no-install-recommends \
g++ \
make \
cmake \
&& rm -rf /var/lib/apt/lists/*
RUN pip install fastapi
RUN pip install uvicorn[standard]
WORKDIR ${WORKINGDIR}
RUN mkdir -p ${WORKINGDIR}
COPY src/* ${WORKINGDIR}
ENTRYPOINT [ "/usr/local/bin/python", "app.py"]
コンテナ内では app.py を実行しており、その中で FastAPI を使ってリクエストを処理します。今回は簡単のために毎回同じ結果を返すだけの関数を用意しました。
from fastapi import FastAPI
import uvicorn
app = FastAPI()
@app.get("/ping")
def ping():
return {"Hello": "World"}
@app.post("/invocations")
def transformation():
# 推論のコードをここに書きます。
return {"invocated": True}
if __name__ == "__main__":
uvicorn.run(
"app:app",
host="0.0.0.0",
port=8080
)
書くほどのものでもないですが、ディレクトリ構成は以下のようになっています。
├── Dockerfile # 上述のDockerfile
├── src
└── app.py # ENTRY POINT
docker のビルドは以下のコマンドで行います。
docker build -t sagemaker-serverless-demo .
特にエラーが出なければ、ECR へプッシュしましょう。ECR へのプッシュは AWS Lambdaがコンテナイメージをサポートしたので、Detectron2 を使って画像認識(Object Detection)を行うAPI を作るがとても参考になります。この記事では sagemaker-serverless-demo という名前のリポジトリを作成しました。
モデルの登録
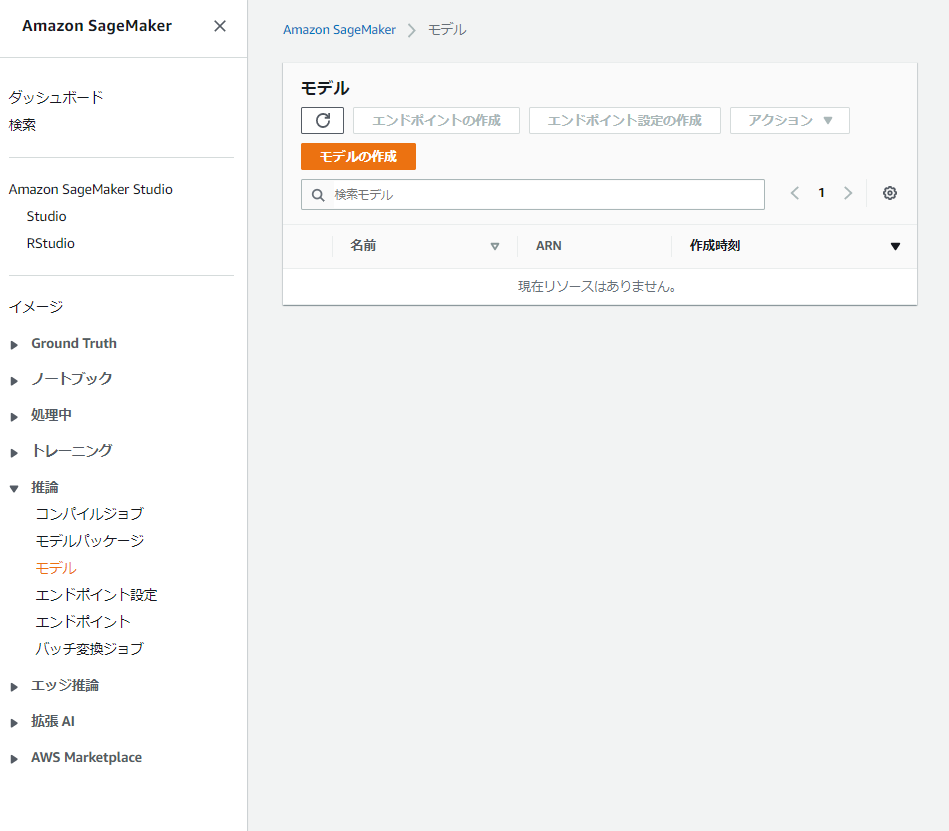
以上で ECR に登録出来たら、次は SageMaker でモデルの登録を行います。Amazon SageMaker のページに移動し、左のメニューから「推論/モデル」を選択します。モデル一覧が表示される画面に移動するので、上の「モデルの作成」ボタンを押します。
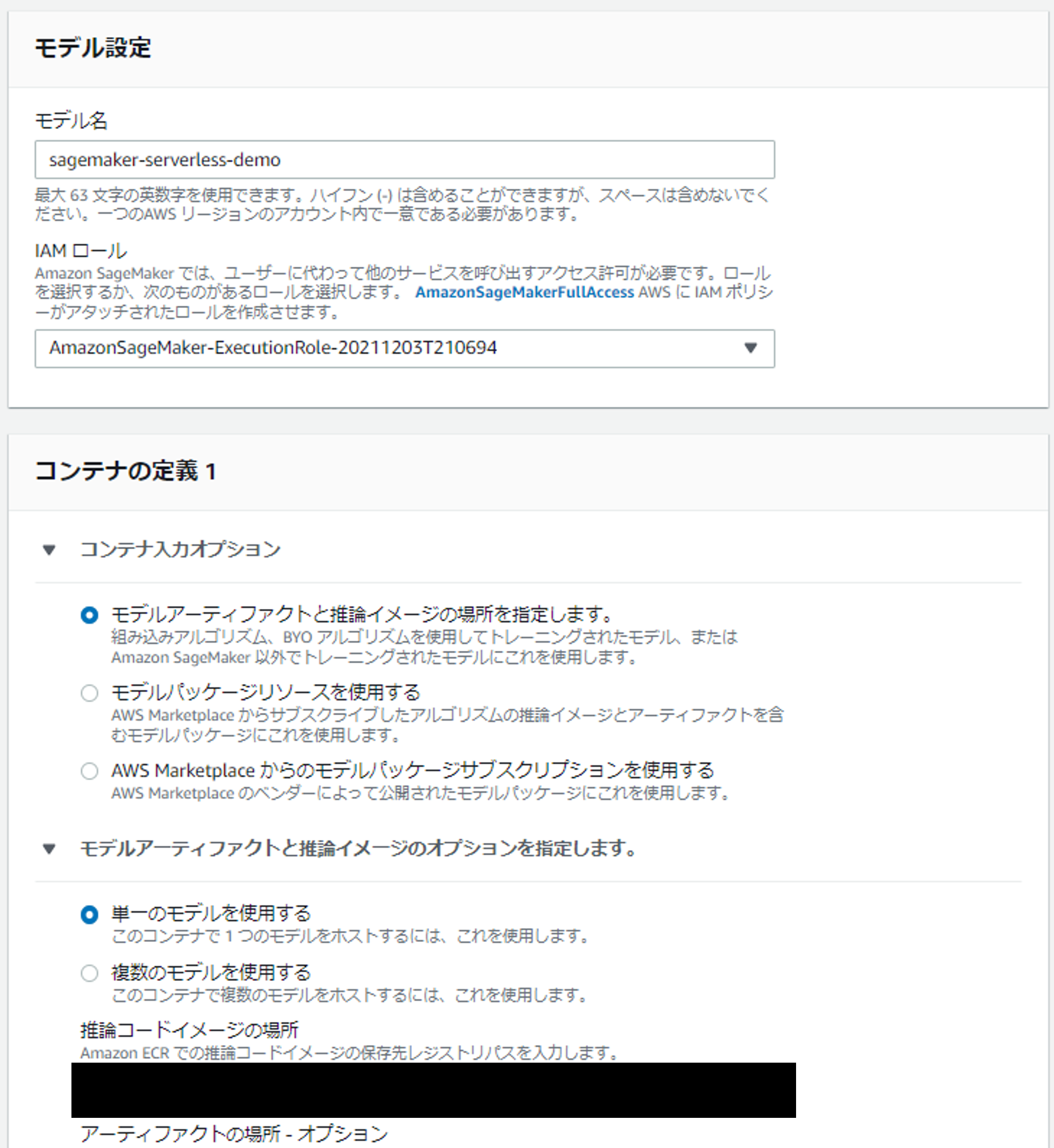
モデル名や IAM ロールは適宜付与してください。今回は sagemaker-serverless-demo という名前にし、新しく IAM ロールを作成、付与しました。
「コンテナの定義」で「モデルアーティファクトと推論イメージの場所を指定します。」を選択し、「推論コードイメージの場所」に先ほど作成した ECR リポジトリの URI を入力します。その後、「モデルの作成」を押すとモデルの登録が完了します。
エンドポイントの設定およびエンドポイント作成
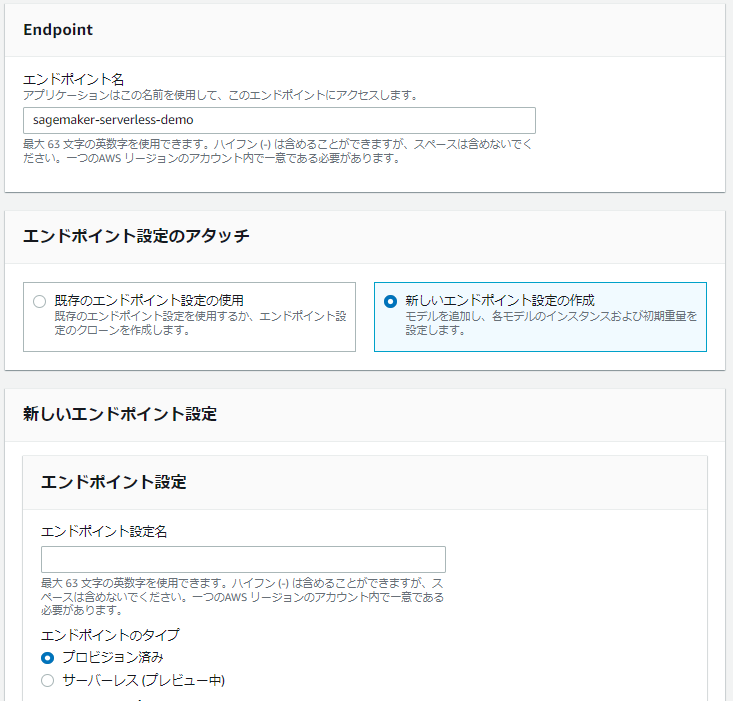
モデルの登録が出来たら、モデル一覧画面からモデルを選択して「エンドポイントの作成」ボタンを押してください。または、左のメニューから「推論/エンドポイント」を選択してください。エンドポイント一覧が表示される画面に移動するので、上の「エンドポイントの作成」ボタンを押します。
「エンドポイント名」は好きな名前を付けてください。今回は sagemaker-serverless-demo という名前にしました。「エンドポイント設定のアタッチ」で「新しいエンドポイント設定の作成」を選択すると、新しいエンドポイント設定が行える画面が下に出てきます。「エンドポイント設定名」は好きな名前を付けてください。今回は sagemaker-serverless-demo という名前にしました。その下の「エンドポイントのタイプ」で「サーバレス(プレビュー中)」を選択してください。それから、「本番稼働用バリアント」で先ほど登録したモデルを選択しましょう。このモデル追加の画面で、メモリサイズや最大同時実行数を変更できます。モデルを追加した後、「エンドポイント設定の作成」ボタンを押すとエンドポイント設定が作成できます。その後、下の「エンドポイントの作成」ボタンを押すとエンドポイントが出来ます。ステータスが Creating から InService に変わると使用できるようになります(5~10 分かかると思います)
テスト
boto3 を使って作成したエンドポイントを叩いてみます。使用したコードは以下。
import boto3
import json
client = boto3.client("sagemaker-runtime", region_name="ap-northeast-1")
bin_pred = client.invoke_endpoint(
EndpointName="sagemaker-serverless-demo",
Body=b"1",
)["Body"].read()
pred = json.loads(bin_pred)
print(pred)
# >>> {'invocated': True}
実行すると {'invocated': True} が返ってきており、動いている事が分かります。
まとめ
ここまで読んでいただきありがとうございました。ボタン一つで簡単にサーバレスで実行できるようになり、今までよりも使う機会が増えそうですね。個人的には、GPU が使えるようになるともっと嬉しいかなという感想です(ちょっと確かめてみたんですが、GPU はサーバレスでは使えなさそうでした)。モデルのデプロイがこれまで以上に便利になりそうなので、これからの動向を見守っていきたいと思います。
以上、瓦でした。
Yuki Kawara
Company: Fusic CO., LTD. 自然言語処理に興味があります。