
Table of Contents
こんにちは、機械学習チーム インターンの石山です。 今回、書類中の表データの構造を保持したままデータ化する技術について調査し実装を行ったので記事にまとめたいと思います。
例えば、下図のように、画像中の書類に含まれいる表を右側のExcelのように抽出することを想定しています。

まえがき
数年前から年々とOCR(光学的文字認識)技術が向上しています。これは写真や画像内の文字情報を認識する技術となります。紙データのPCへの入力作業をOCRにより自動化することは盛んに行われており、例えば、
- 顧客情報を含んだ書類画像に対して文字情報を認識し顧客情報を整理する
- 申込書の画像から文字情報を認識して必要な情報を整理する
- 病院では患者の問診票の文字情報を読み取って自動的に患者の情報を認識し整理する
など非常に多くの分野で取り入れられています。OCRを利用することで人為的コストと時間削減、また、人為的な入力ミスのリスクも少ないなどといった様々な恩恵を受けることができます。
今回は書類画像内の「表」に注目し、画像から表のデータを認識して、表の構造を保ったままエクセルやcsvといった表データに出力することを目指します。また、汎用性の観点から、今回扱う書類画像は文字情報が埋め込まれているpdfデータではなく、文字情報が埋め込まれていないpdfやpngやjpegといった画像データを対象としました。
実装
今回の実装の全体の流れとしては、以下の通りです。
- Google Cloud Vision Apiを利用してOCR
- OCRにより取得した文字情報(文字とその位置)を埋めこんだpdfを作成
- camelotというライブラリを用いて、pdf内部の埋め込まれた文字の座標を用いた表情報の抽出
1. Vision Apiによる文字認識とpdf作成
まずPDFのレンダリング用のライブラリであるpopplerをインストールします。私はwindowsOSのためこちらからインストールしました。
まず、ライブラリの準備です。google cloud viosonで文字認識を行い、reportlabで文字情報を埋めこんだpdfを作成します。
import os
import numpy as np
import cv2
from PIL import Image
from google.cloud import vision
from google.cloud.vision import types
from reportlab.pdfgen import canvas
from reportlab.lib.colors import Color
from reportlab.lib.utils import ImageReader
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont次にgoogle cloud vision apiに画像を送信し、送られるOCRの結果の処理を行います。
img = cv2.imread(str(input_path))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_byte = cv2.imencode('.png', img)[1].tobytes()
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = '*****'
client = vision.ImageAnnotatorClient()
def get_word_info(response): #google cloud visionから送られる結果の処理
document = response.full_text_annotation
bounds_word = []
words = []
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
word_tmp = []
for symbol in word.symbols:
word_tmp.append(symbol.text)
bounds_word.append(word.bounding_box)
word_tmp = ''.join(word_tmp)
words.append(word_tmp)
left_bottoms = [] #reportlabが左下を基準点として文字をレンダリングするため、左下の座標を保存しておく
heights = []
for bound in bounds_word:
temp_xs = []
temp_ys = []
for vertice in bound.vertices:
temp_xs.append(vertice.x)
temp_ys.append(vertice.y)
left_bottoms.append({'x': min(temp_xs), 'y': max(temp_ys)})
heights.append(int(max(temp_ys) - min(temp_ys)))
result = [{'text':text, 'box':bounds_word, 'vertic': vertic, 'height': height} for (text, bound, vertic, height) in zip(words, bounds_word, left_bottoms, heights)]
return result
img_gcv = types.Image(content=img_byte)
response = client.document_text_detection(image=img_gcv) #ocr実行!
results = get_word_info(response) #結果の処理
次に取得した文字情報を埋めこんだpdfを実際に作成します。
small_fix_y = 0.25 #reportlabのレンダリング時に下にずれるのを補正する
Y, X = img.shape[0], img.shape[1]
cc = canvas.Canvas(output_path, pagesize=(X,Y))
cc.drawImage(ImageReader(cv2pil(img)), 0, 0, width=X, height=Y)
for result in results:
cc.setFont('IPAexMintyou', result['height']*0.9)
cc.setFillColor(Color(0, 0, 0, alpha=0)) #色は透明にする
cc.drawString(result['vertic']['x'], Y - result['vertic']['y'] + small_fix_y*result['height'], result['text'])
cc.showPage()
cc.save()これにより下の画像のように文字情報が埋め込まれたpdfを作成することができます。(画像は文字上をドラックして選択している様子)
2. 表データの生成
1で作成したpdfファイルを用いて、表と表内のセルの検出行い、埋め込まれた文字の座標を利用してエクセルデータに直す処理を行います。ここではcamelotというライブラリを用います。
camelotではlatticeとstreamの2種類の表とセルの検出方法が実装されています。latticeでは画像内の水平、垂直の両方向の直線を検出し、、輪郭検出を行い一番外側のものを表の境界線とみなし、直線の交点を見つけることでセルの検出を行います。実装はすべてopncv-pythonで行われています。
streamでは、これは画像からではなく、埋め込まれた文字の座標を用いて、y軸方向の高さに基づいて、グルーピングを行うこと表の行を推定し、そのうえで、単語間の距離を測ることによって列を推定し、その後、推定された列と行に基づいてテーブルの認識を行い、セルの整理を行います。詳しくは元になった論文をご覧ください 。 今回は1での埋め込みに多少のずれが生じることによって、セル検出がうまく働かなかったためlatticeのみを用います。
import camelot
lattice_tables = camelot.read_pdf(str(input_path), flavor='lattice', line_scale=110)
lattice_tables.export(output_path, f='excel') # 今回はエクセルで出力しているがjson csv htmlでの出力も可能実行結果は以下の通りです
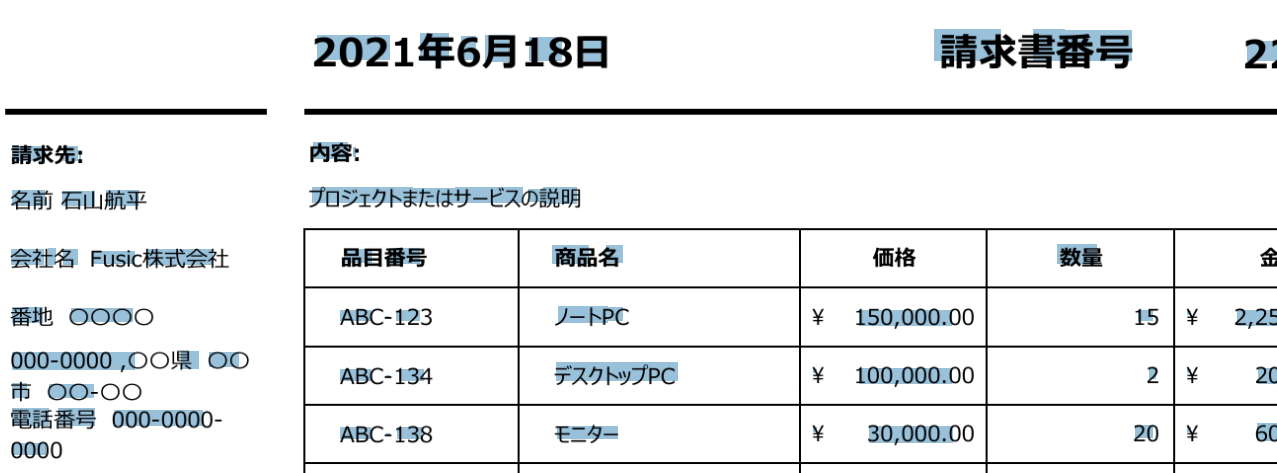
今回は自作した架空の請求書の画像データを用いています。画像の通り、うまく表の情報を抽出できていることがわかります。
まとめ
今回は書類画像からOCRを行い表の情報をエクセルやcsvといった表データに変換する方法を紹介しました。実装して分かった注意点としては、今回OCRや直線の検出を行っているので、精度を出すためにはある程度の解像度が必要であることです。
また、今回の実装の弱点として、今回紹介した手法では表のセルの分割に直線が引かれてある必要があるため、分割線が引かれていない表ではうまく機能しないことです。そのため、文字位置を用いたstreamなどの手法も検討しましたが、OCRで行う場合はやはり元の位置からのずれが生じるので、うまく機能しませんでした。そのため、実際に文字が埋め込まれたpdfデータが十分な量あれば、それらをいったん画像のみのデータにして今回のようにOCRで文字位置を取得して元のpdfの文字位置との対応について学習できれば、直線検出を行わずに表やセルの検出を行うということも可能なのかなとも思いました。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps