
Table of Contents
こんにちは、鷲崎です。とうとう、CVPR 2021が開催されました!弊社でも、CVPRの最新論文で話題になっているものを読み、その結果に驚きを得ています。本記事で紹介する、GANs N' Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!) という論文は、最近発表されたGANの論文で、とても面白い結果が見れます。
GANs N' Rosesというタイトルですが、Guns N'Rosesというロックバンドのオマージュとtwitterで見かけたのですが、本当でしょうか。。。 あまりロックバンドについて詳しくないのでYoutubeで調べていると、以前別の論文で見かけた気がしました。
GANs N' Rosesを実際に試してみまして、その結果が以下の通りです。論文のサンプルに合わせてtiktokで撮った動画を用いました。論文の目的は、顔画像からマッピングされるコンテンツコード(顔の向きや、パーツの位置など)と、ランダムに選ばれたアニメ画像のスタイルコード(どのような表現にするか)を対応させるマップを学習させることです。このタスクにおいて、多様性のあるスタイルの生成を可能にしている部分が、論文のすごいところです。
顔を動かした時に、アニメ画像が動いていることから、対応したマップを学習できていることが分かります。下の動画では、顔全体が入っていない部分がありますが、そのような時は、破綻していますね。
GANs N'Roses (GNR) とは
GANs N'Roses (GNR)の枠組みとしては、マルチモーダル 画像翻訳(Image to Image;I2I) です。マルチモーダルという言葉は、あまり馴染みがないですが、今回の場合、コンテンツ表現(顔画像)とスタイル表現(アニメ画像)のことだと思います。
GNRでは、同じ顔画像が入力された場合でも、様々なアニメ画像を表現しています。これはコンテンツコード(顔画像からマッピングされる)とスタイルコード(潜在変数)を受け取り、アニメ画像を生成する関数として表現することができます。
しかし、この表現には、以下を達成する必要があります。
- 制御性: 入力された顔画像を変化させると、アニメ画像の内容も変わる (例えば、人物が顔を傾けると、アニメ画像も顔を傾ける)
- 一貫性: 同じ潜在変数の集合をを使ってアニメ画像を作成した場合、顔画像が変化した場合でもスタイルが一致している必要がある (例えば、人が顔を傾けた場合、潜在変数が変化しない限り、アニメ画像のスタイルは変化しない)
そこで、この論文は、「コンテンツ」とは、顔画像がデータ拡張(拡大、縮小、回転、切り取りなど)により変換された時に変化するもので、「スタイル」とは、変化しないものという明確に定義することで、課題を解決しています。
以下の図(論文中Figure 2.)が、GNRの学習の概要になります。Generater部分の上側を見てください。エンコーダ(E)で顔画像からコンテンツコード(c)とスタイルコード(s)がマッピングされています。また、コンテンツコードとスタイルに関する潜在変数を入力としてデコーダ(F)から、アニメ画像が生成されています。実際のところ、学習時には、アニメ画像の生成と同時に、下の画像の顔画像とアニメ画像の立ち位置が逆転した場合も学習しているようでした。(基本的にはCycle GANと同様な気がしています。)
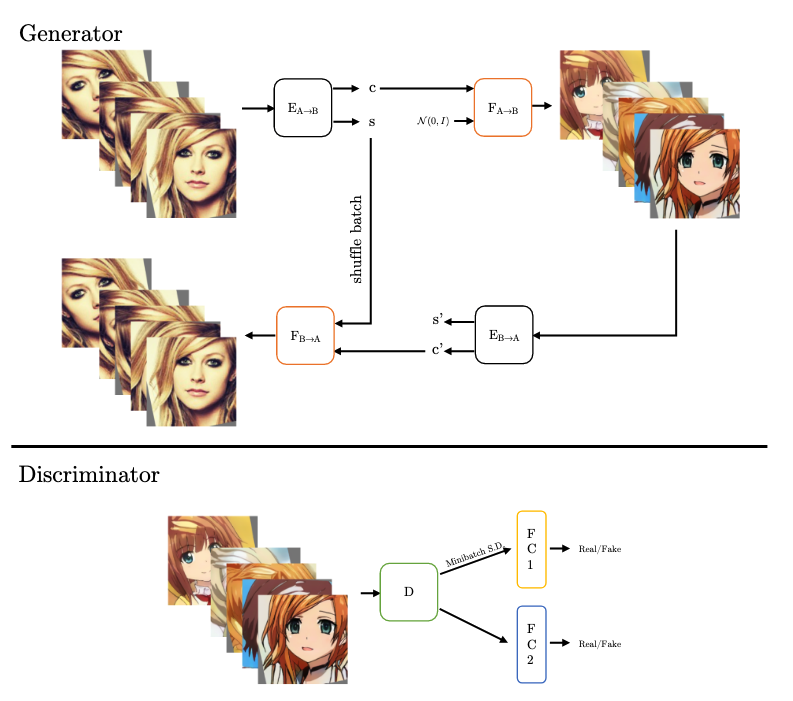
学習は、基本的にサイクル一貫性を保つような形式で行われます。具体的には、コンテンツコードから生成されたアニメ画像は、コンテンツの情報を含んでいるため、Generatorの右下のように、エンコーダを使用して、アニメ画像から、コンテンツコードとスタイルコードを復元できます。そして、このコンテンツコードと最初に生成したスタイルコードを入力として、デコーダで顔画像を生成します。上記の通り、アニメ画像を左側とした場合も学習されます。 これは、基本的には、従来手法でも同じですが、コンテンツのサイクル一貫性を高めるため、スタイルコードを疎かにしてしまっています。
そこで、入力画像をデータ拡張し、それを1バッチとして学習しています。データ拡張を行うことで、スタイルは変わらないが、コンテンツは異なる画像によるバッチが作成できます。エンコーダ(E)によるスタイルコード(s)は、バッチ内では、一貫しているという損失を与えることで、スタイルコード(s)は一貫したものに学習されていきます。また、shuffle batchの部分で、スタイルコードをシャフルしていますが、スタイルコードが同じなら、結果的にサイクル一貫性が保たれるようになります。
多様性の確保に関して、理解が進んでいませんが、個人的には、次のようにして、スタイルの多様性を確保していると考えています。ここで話している多様性とは、スタイルコードが異なると、生成画像のスタイルが変わることです。Generator部分のアニメ画像と顔画像の立ち位置が逆と考えてください。アニメ画像を入力した時、そのアニメ画像のスタイルコード(s)が出力されます。そして、そのスタイルコードを入力として生成されたアニメ画像との誤差により学習されていきます。つまり、あるスタイルAに対するスタイルコード、あるスタイルBに関するスタイルコード、...といった風に、このサイクル一貫性の学習が進むにつれ、スタイルに対応したスタイルコードが決まっていき、スタイルの多様性が保証されると、個人的には解釈しました。
最後に、Discriminatorに関してですが、2つに分岐していますが、これは、PGGANで取り入れられた、ミニバッチ標準偏差を導入したためです。
上記をまとめると、損失は、バッチにおけるスタイルコードの一貫性 + サイクル一貫性 + Dicriminatorにおける識別誤差になります。
まとめ
実際、コンテンツを固定して、スタイルコードを変更すると、以下のように多様性のある変化が行えていることが分かります。

そして、コンテンツのみ変更した場合、スタイルが保たれていることが、以下の図から分かります。

以上、GANs N' Rosesの解説でした。手法や実験の詳細は、論文 を参照してください。個人的に、面白いと思った部分は、バッチ内では、スタイルの一貫性を立つように工夫されているところです。従来手法には、なかった斬新の学習方法だと思います。このバッチごとという考え方は、別のタスクでも使えるかもしれません。
この記事を書いていたら、CVPRが始まってしまいました。参加していませんが、面白い論文を見つけて、調査していきたいです。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps