
Table of Contents
こんにちは、鷲崎です。
最近、画像処理においてもTransformerが使われてきています。実際のところ分かりませんが、私としては、畳み込み演算はローカルな情報、Transformerは大域的な情報を得意にしているのかなというくらいの認識です。もう少し、Transformerについて知りたいと思い調査していたところ、セマンティックセグメンテーションで軽量で性能も良いSegFormerという手法が話題になっていたので、記事にまとめたいと思います。
SegFormerの立ち位置
セマンティックセグメンテーションは、画像ごとではなく、ピクセルごとのカテゴリー分類タスクです。このタスクの性能向上には、バックボーンとなるアーキテクチャの設計が重要となります。バックボーンをVGGにした初期の設計から、より強力な性能を持つものに進化させていったことで、セマンティックセグメンテーションの性能も向上しています。
このバックボーンとして、注目されている手法が、画像分類のためのTransformer(Vision Transformer; ViT)です。ViTに関しては、画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説!という記事が参考になります!簡単に説明すると、自然言語処理におけるTrasformerと同様の設計になっており、画像を複数の線形に埋め込んだパッチに分割し、そのパッチに位置埋め込みを行いTransformerの入力とする標準的な設計になっています。このViTをバックボーンとして採用したSEgmentation TRansformer (SETR)という手法も提案されています。しかし、ViTは、単一スケールの低解像度な特徴を出力し、計算コストも大きいという欠点がありました。
そこで、マルチスケールなPVT(Pyramid Vision Transformer)や、Swin Transformerなど提案されました。しかし、これらの手法は、Transformerエンコーダの設計について改善した一方で、デコーダに関しての改善は、考慮していませんでした。
従来の手法と対照的に、エンコーダとデコーダの両方を再設計したものがSegFormerです。
SegFormerとは
論文には、「Transformerと軽量な多層パーセプトロン(MLP)デコーダを統合した、簡素で効率的でかつ強力なセマンティックセグメンテーションフレームワーク」と記載されています。
簡単に説明すると、
- エンコーダ部分は、位置エンコードを用いておらず、階層型Transformerの構造
- デコーダ部分は、複雑性や計算コストを小さくしたAll-MLP (Allが重要!)
になっています。
エンコーダ部分で、位置エンコードを行わないことで、解像度の変化にロバストになっています。また、階層化されたことで、高解像度の細かい特徴と、低解像度の荒い特徴の両方を抽出することができます。ViTは、固定された解像度の入力で、低解像度の特徴マップの抽出しかできません。
デコーダ部分は、All-MLPにより、異なる層の情報を集約し、局所的なAttentionと大域的なAttentionの両方を混合できます。
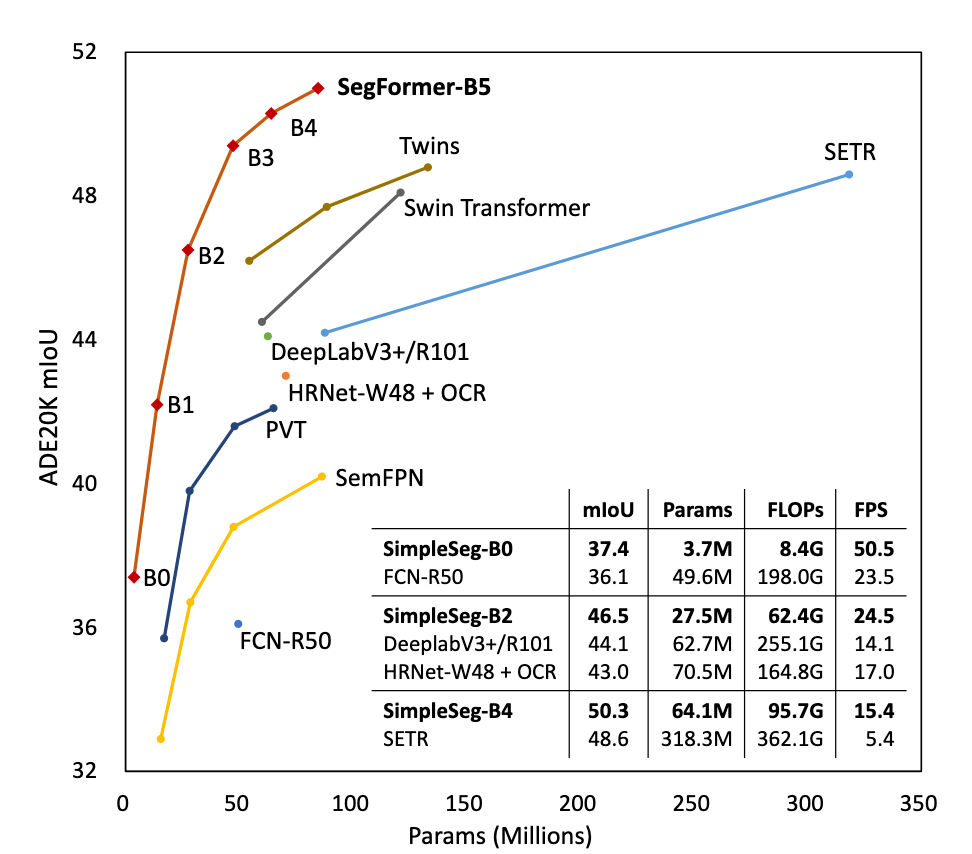
性能としては、下図(論文中 Fig.1)のように、他の手法と比較して、少ないパラメータで高精度を達成しています。
SegFormer モデルの詳細
SegFormerは、下図(論文 Fig.2)のようなモデル構造になっています。先ほど、説明したように階層型TransformerとAll-MLPで構成されています。
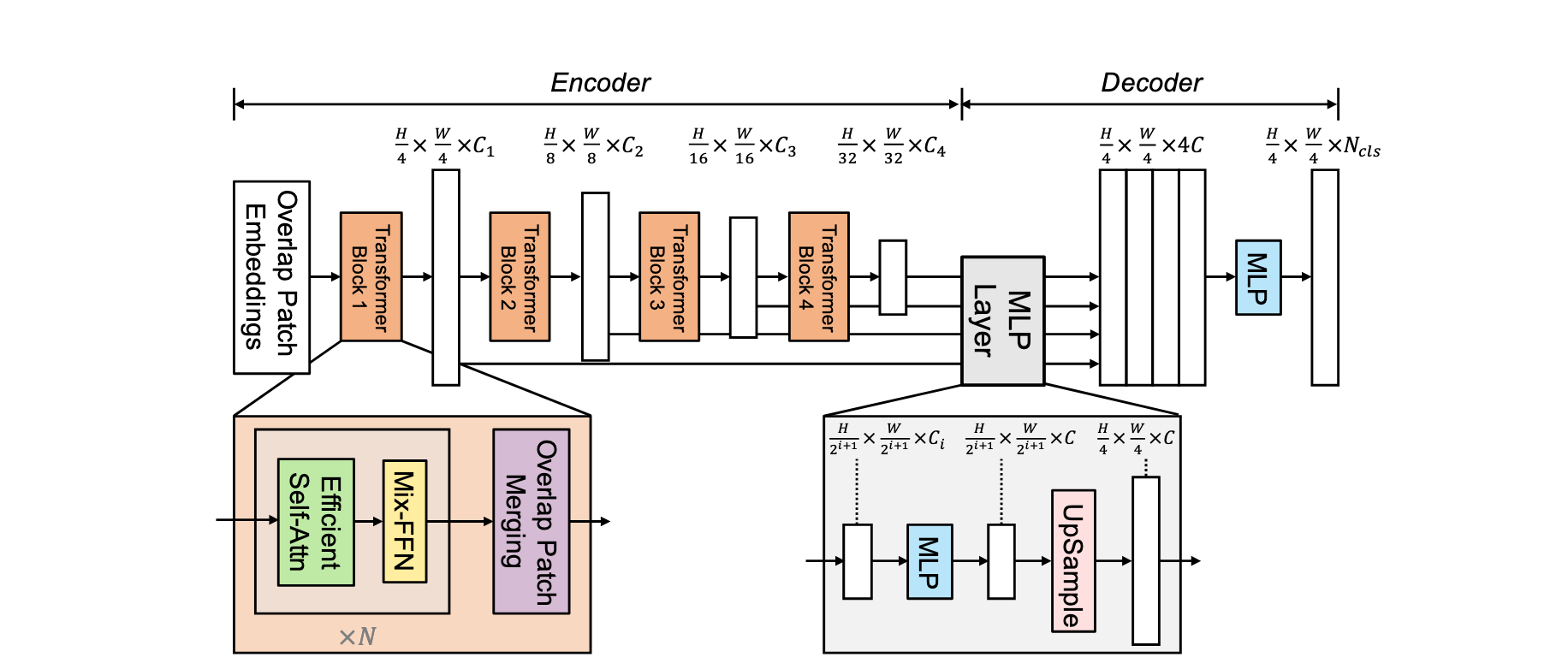
エンコーダ: 階層型 Transformer
階層型Transformerとは、モデル図のエンコーダ部分のように、TransformerのBlockが連なっている構造のことを指します。この構造により、高解像度の細かい特徴と、低解像度の荒い特徴の両方を抽出できます。
Transformer Blockは、Efficient Self-Attention、Mix-FFN、Overlap Patch Mergingからなります。
Overlap Patch Merging
階層の特徴マップをを次の階層の特徴に変換します。 例えば、の場合、を、に変換します。
この時、パッチの連続性を維持するため、パッチサイズ(), パッチ間のストライド(),パディングサイズ()のパラメータにより オーバラップしたパッチの結合処理が行われます。(例えば、K=7, S=4, P=3)
Efficient Self-Attention
シーケンス長をとすると、Attentionの, , は、次元になります。この時、一般的なMulti Head self-atention (MHA)の計算量は、です。
そこで、PVTにて導入されたシーケンス削減の手法を用いています。削減率 (64, 16, 4, 1)を用いて、Keyを 次元に変換し、にします。
具体的な変換は、以下の式です。をして、に突っ込んでいます。
このを用いたMHAを、ここでは、Efficient Self-Attentionとしています。
Mix-FFN
位置埋め込みの代わりに、Feed Forward Network (FFN)において3x3の畳み込み演算を用いるMix-FFNが提案されています。畳み込み演算において、ゼロパディングを用いることで位置情報のリークが期待できます。例えば、この位置情報のリークにより、物体検出で、位置によって物体の検出精度が差が出る要因の一つになります。
Mix-FFNは、以下のように定式化されています。よくある形式ですね。
実験により、3x3の畳み込みで、位置情報の抽出は十分であることが示されています。
デコーダ: All-MLP
All-MLPは、MLPのみで構成される軽量なデコーダです。基本的には、モデル図の通りで、のあとの特徴量は連結されているためになっていること、カテゴリ数分のマスクが出力されることに注意してください。
なぜ、All-MLP デコーダのみで良いのか?
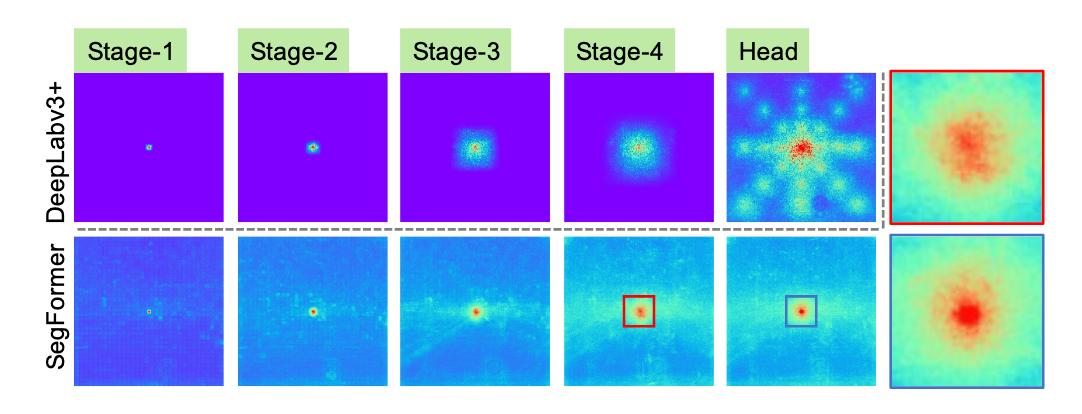
論文では、効率的受容野(Effective Receptive Field; ERF)を解析することで、デコーダが単純なAll-MLPで良いか説明してます。
下図(論文 Fig.3)は、CNNベースのDeepLabv3+とTransformerベースのSegFormerのERFを可視化した図です。Head部分は、SegFormerの場合、All-MLPデコーダのERFです。
入力に近いStage-1では、どちらも局所的な反応が得られています。Stage-4では、CNNベースの手法で受容野が限られている、一方で、Transformerベースの手法の受容野は、広範囲に広がっています。
Transformerに関する図をズームした赤と青のボックスを比較した時、MLPを通した後の方が、局所的なERFが強くなっています。
デコーダを単純にしたい場合、局所的な特徴と広範囲な特徴の両方を抽出できることから、Transformerベースが良いことが分かります。そして、デコーダをAll-MLPにすることで、局所的な特徴を補完し、より強力な表現を獲得できていることが分かります。
まとめ
実験の結果は、一番最初に示した図の通りです。詳細は、実際の論文を参考にしてください。ノイズ、ブラー、天候など様々な環境下で、State of the artなロバスト性を示しているので、要チェックです。
論文を読む前の「畳み込み演算はローカルな情報、Transformerは大域的な情報を得意にしているのかなというくらいの認識」から、Transformerは、MLPを加えることで、ローカルな特徴も捉えられるという認識に変わりました。最近、gMLPなどTrasformerいらないのでは、という論文がでてきていますが、まだまだ、研究されていない部分が多く残っていて、今後もTransfomer最強伝説が作られていくのかもしれません。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps