
Table of Contents
wav2vec 2.0とは?
Transformerを使用した音声認識フレームワークであり、大まかなアーキテクチャは以下の図のようになっています。
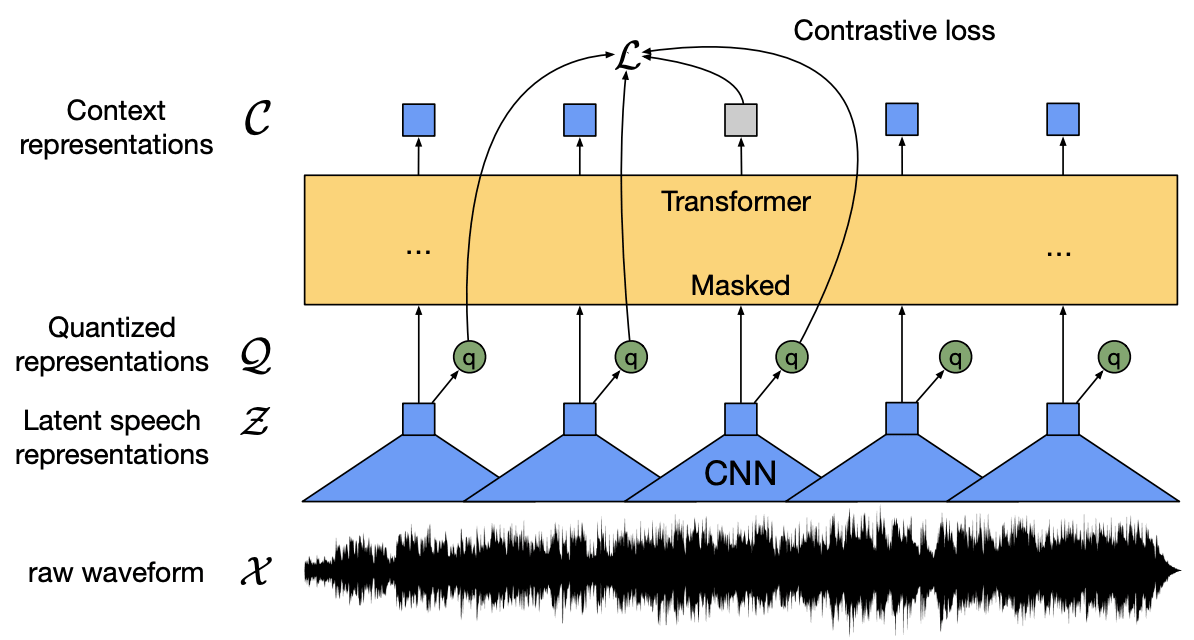
音声信号から潜在表現に畳み込むCNNエンコーダ部分と、潜在表現から文脈表現を得るtransformerエンコーダ部分からなっています。
wav2vec 2.0は従来の音声認識モデルと違い教師あり学習に加え、自己教師あり学習も取り入れています。自己教師あり学習ではオリジナルの音声と変更を加えたバージョンのいずれかを選択させ、モデルをトレーニングします。 考え方としてはContrastive Learningが近いかもしれません。これにより音声のラベル付きデータが少なくても、ラベル無しデータから音声の特徴を学習しラベル付きデータでファインチューンを施す事で高い精度を得られるためです。
そして、少量のラベル付きデータを用いて、このモデルをファインチューニングすることで、実際に使用するテキスト情報に高い精度で変換可能にしています。
実際に日本語で学習させる
環境は全てGoogle colaboratory proを使用しています。
データセットはcommon voiceからとってきました。notebookは
こちら
の実装を参考にして、日本語ラベルを全てローマ字に変換しました。
日本語ラベルは、そのままひらがなに変換したものを使用した場合も学習させてみましたが、
発音に近いローマ字のほうが精度が高かったのでローマ字で進めています。
学習済モデルはfacebookが公開している53の言語で学習している物を使用し
train: 2193
valid: 632
の日本語データセットで学習させました。パラメータは
batch size: 8
gradient accumulation: 4
learning rate: 5e-4
学習速度はtesla p100使用時0.34step/sほどで、2000stepまで1時間40分でした。
| step | train loss | valid loss |
|---|---|---|
| 1000 | 2.588200 | 0.574359 |
| 2000 | 0.178700 | 0.672339 |
1000stepから2000stepでいきなりvalid lossが上がり、過学習気味になりました。 これはそもそものラベル付きデータセットの数があまりにも少なすぎたのが原因だと思われます。
推論してみる
今回はmodelの重みは2000stepの物を使用します。 推論部分は音声ファイルのサンプリングレートを16000まで落としその配列を入力することで文字が推論されます。
def load_and_resample(file_path, resamling_rate=16000):
signal_tensor, samling_rate = torchaudio.load(file_path)
signal_array = signal_tensor[0].numpy()
signal_array = librosa.resample(signal_array, 48000, resamling_rate)
return signal_array
signal = load_and_resample(path)
signal_list = signal.tolist()
input_dict = processor(signal_list, return_tensors="pt", padding=True, sampling_rate=16000)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
そして出てきた結果がこちら
Prediction: kimurasannidenwawokakitemoraimashita
きむらさんにでんわをかきてもらいました
Prediction: kinouhahachijikannemashita
きのうははちじかんねました
Prediction: chiisanaunagiyaninekkinoyounamonogaminagiru
ちいさなうなぎやにねっきのようなものがみなぎる
Prediction: iserehahawaiyakariforunianadonihonjingaookusumuatsuitochidesuwatetemitai
いせれははわいやかりふぉるにあなどにほんじんがおおくすむあついとちですわててみたい
Prediction: kikaigakushuuenjinianoaokidesu
きかいがくしゅうえんじにあのあおきです
かなり惜しい感じに推論されました、2000とかなり少ないデータセットのわりに結構な精度が出ていると思います。このほかにも多くのデータを検証しましたが、特定の発音や単語が苦手などの傾向はみられ ませんでした。データによっては人間である私も聞き取りにくいものや、活舌の問題で複数の発音に聞こえたりしており(特に ”き” と ”し”)発音する人間に依存する部分が大きい傾向にありました。最後のPredictionは私自身の声で、これ以外にもいくつか推論させましたが早口だったりすると発音がはっきりできておらず推論結果が望んだ結果にならないことが多くありました。
課題などその他
今回wav2vec 2.0を日本語でファインチューンしましたが日本語での学習は多くの課題を感じました。 日本語をローマ字として学習させるためpythonライブラリpykakashiを使用し漢字もひらがなも全てローマ字に変換しましたが、音読み訓読み等で 本来発音していない文字をラベルとして学習することになりました。ただでさえ少ない日本語データセットですのでこの部分は 大きいと感じました。
aoki masataka
Fusicでインターンをしています。