
Table of Contents
こんにちは、鷲﨑です。弊社の機械学習チーム勉強会で、Exploring Simple Siamese Representation Learning という画像の表現学習に関する論文を読みました。自然言語処理におけるBERTのように、画像処理においても表現学習(Representation Learning)の手法が重要だと考えられており、この論文も、画像処理にて表現学習を行う手法の一つであるSiamese学習の新しいアーキテクチャを提案していました。この論文では、教師なしで表現学習を行うこれまでの手法の中でも、より簡単に実装可能な手法を提案しており、また、提起している仮説にもとても感動したので、紹介したいと思います。
今までのSiamese Learningとの違い
下図(論文中 Fig.3)は、論文にて提案されているSimSiamと、代表的なSiamese学習を用いた表現獲得の手法を示しています。 各手法は、下図の2つのencorderの出力を、それぞれ, とした時、に収束してしまうという崩壊問題に対して、様々な方法で対処しています。 崩壊問題がなぜ、問題であるかというと、ここでは類似度を学習したいわけではなく、画像の表現を学習したいためです。
以下、SimSiam以外の各手法を簡単に説明します。
- SimCLR
崩壊問題を解決するため、大量のネガティブサンプリング(対象と無関係なデータ)が必要で、様々な負例との比較を行うため、バッチサイズを大きくする必要があります。実際、論文中でもバッチサイズが4096や8192など大きなバッチサイズで、良好な精度を達成していました。しかし、この手法は、各encoderに入力している拡張した画像同士の類似度を近くしているだけで、表現を学習しているわけではありません。 - BYOL
momentum encorderの導入と、stop gradientによる勾配伝搬の停止によりパラメータ更新の停止により、ネガティブサンプリングと崩壊の問題を解決しています。しかし、momentum enconderは、勾配停止により学習されないため、encoderのパラメータとmomentum encoderのパラメータを適当な割合で足し合わせて更新する必要があり、実装が複雑になります。 - SwAV
この手法は、崩壊問題に対して、クラスタリングを用いて、対処しています。具体的には、各encoderの出力とクラスタベクトルとの類似度を取り、Sinkhorn-Knoppアルゴリズムを用いて最適化したクラスタ割当確率と、Softmaxから得られるクラス割当確率が一貫していることを仮定して問題を解いています。(詳細は、この記事がわかりやすかったです。) この手法も、ネガティブサンプリングの問題を解決していますが、実装が複雑です。
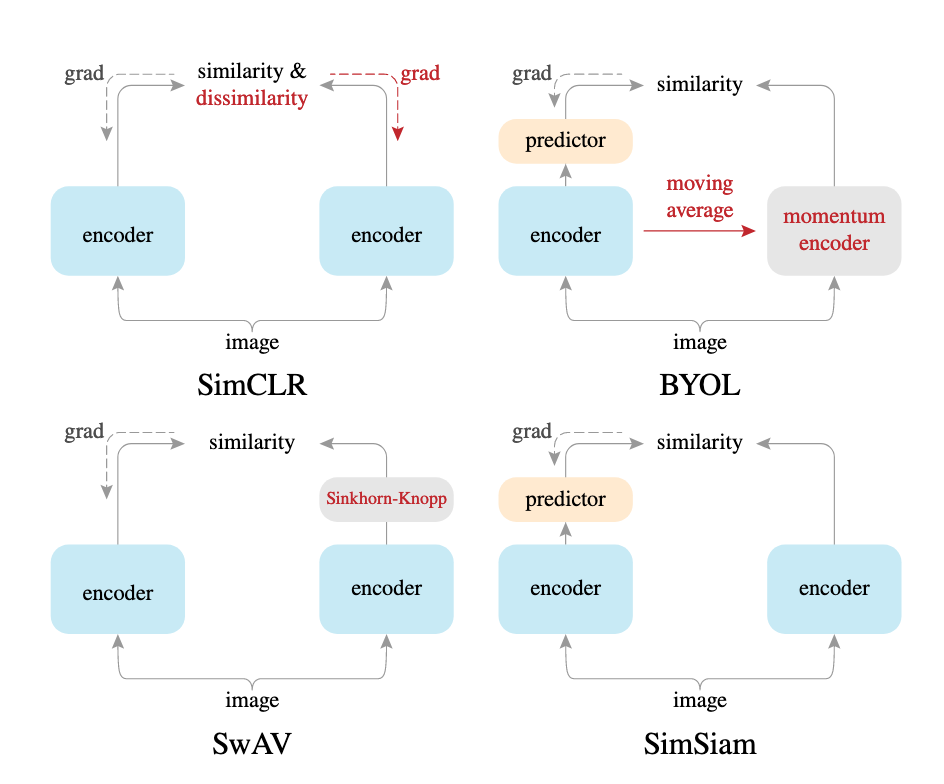
上記のように、これまでの手法は、ネガティブサンプリングを行い必要なデータが増える、または、momentum encoderやクラスタリングを行い実装が複雑なるなどの問題がありました。そこで、提案されたのが、SimSiamです。これは、ネガティブサンプリングが必要なく、stop gradient(勾配停止)と、予測レイヤを追加するのみで、以下の疑似コードのように簡単に実装可能です。ここでは、予測レイヤ(h)を導入しており、また、損失(D)の中では、detachを使用して、勾配計算を止めています。

論文の結果を見ると、既存の手法より良い結果を示していました。この理由を、勾配停止と、予測モデルにあるとしており、実際、勾配停止がない場合と予測レイヤーがない場合の実験で、大きく精度が低下していました。
なぜ、勾配停止と予測モデルが必要なのかの仮説
表現学習の損失を定式化すると、以下のように書くことができます。
ここで、は、パラメータで定義されたニューラルネットワークで、はAugmentation(データの拡張)、は画像です。 は、画像の特徴表現で、最終的には、あらゆるデータ拡張の平均で更新されていきます。ここでの目的は、画像の表現を出力する、ネットワークを学習することです。しかし、のように損失を最小化するためには、ネットワークを学習するだけでなく、特徴表現も学習する必要があります。
そこで、EMアルゴリズムのように、以下のように更新することで、この損失を最小化しています。
- を固定し、損失が最小となるを計算
- を固定し、損失が最小となるを計算
これらの計算を繰り返すことで、を最小化することができます。
まず、2.から考えていきます。の更新は表現学習の損失より、で計算できます。これは、データ拡張に関する分布における画像の平均的な表現を割り当てていることになります。
しかし、データ拡張に関する分布は未知であるため、実際にこれを計算することは困難です。
SimSiamにおける近似
そこで、SimSiamでは、期待値計算をせず、以下の式でを更新するように近似しています。これは、適当な一回のサンプリングによる画像とデータ拡張で更新していることになります。
また、この結果、の更新も以下のようになります。この式は、一般的なSiamese学習の使用する定理ですね。
さて、上のを更新する式では、片方のネットワークのパラメータは定数()で固定されています。つまり、SimSiamでは勾配停止を適用することになります。
一方で、SimSiamの近似により、表現学習の損失に対するEMアルゴリズムライクな更新とのギャップが発生しています。それは、の計算時に、期待値計算を除去したことです。 この期待値計算を補助するために、予測レイヤーを導入しています。各ネットワークの出力をとした時、予測レイヤの出力は、との誤差が最小となることがゴールになります。これは、任意の画像に対して、を満たすを計算することになり、画像の特徴表現の更新式になります。このは実際に期待値を求めるわけではありませんが、論文では、この予測レイヤを用いることで、近似によるギャップを埋めてくれるのではないかと仮定していました。
まとめ
上記のように、順序だって学習のアーキテクチャを作ることは、憧れます。そして、実際に性能が出ていることも、すごいと思います。 SimSiamは、実装も簡単なので、今後、Siamese学習を行う際には、使用も検討に入れて良いのではと思います。 論文中には、他にも、パラメータに関する考察や比較実験があり、面白いので是非読んでみてください。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps