
Table of Contents
こんにちは。Fusicの塚本です。
趣味で、ゲームを嗜んでる人、多いかと思います。
そんな中、僕は趣味としてポケモンをプレイしています。
今回は、個人的に集めたオンライン対戦のデータを使って、そのポケモンの持ち物判定を行うというものです。
持ち物とは、対戦で1匹1つだけ持たせることのできるアイテムのことを指します。
その持っているものをある程度判定できれば、プレイを少し有利に進められる(かもしれません)。
本当は、自動で対戦してくれるエージェントを作ろうとなったときに評価基準として入れられるんじゃないかなあと思ったから、、、という試みです。
今回の目的
まず、オンライン対戦についてですが、軽く説明すると
- ポケモン上限6体までを選び1パーティとする
- 6匹の見せ合いから3匹選んでバトル
- 同じポケモン/道具は使用できない と言ったものです。
それで今回はパーティからポケモンが持っている持ち物を判定させることが目的です。
対戦によく使われるアイテムの総数は20~30種類あります。
なので、持ち物を判定させると言っても、どのポケモンがどの持ち物を持っているかの完全な判定は不可能だと思ってます。
ということで、持ち物自体に分類を持たせ、その分類で判定を行いたいとおもいます。
具体的には以下の3つの分類で、判定していきます。
| itemのラベル | |
|---|---|
| 0 | 攻撃系のアイテム |
| 1 | 耐久系のアイテム |
| 2 | 起点系のアイテム |
使うデータの内容について
今回は、Twitterで「#レンタルパーティ」とタグ付された画像データを利用します。 具体的な流れは以下の感じです。
「TwitterAPI」→「レンタルパーティ画像取得」→ 「6体のポケモン画像へ分割」 → 「1体ずつのポケモンの画像をデータへ変換」
これを行った結果が以下です。
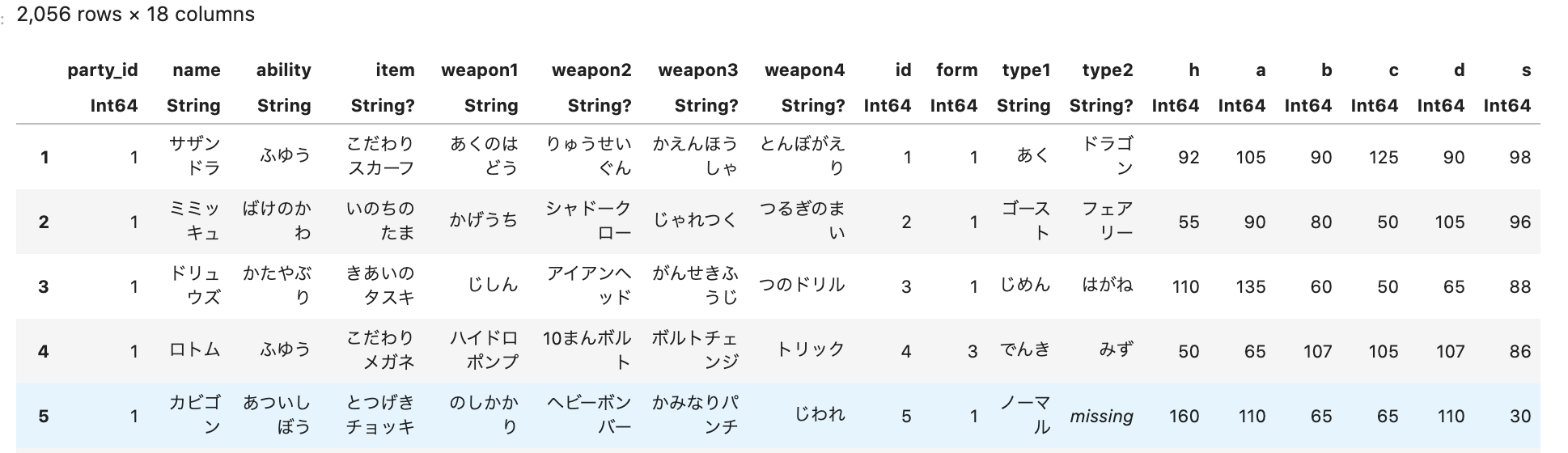
h~sについてはポケモンのステータスを表す俗称です。
この中のitemを上記のルールで0~2へラベルし直しました。
また、他のデータに関しては、基本的に以下の4つの観点から観察し、分析を行いました。
- 攻撃系の特性
- ステータスの耐久性能
- ステータスの攻撃性能
- パーティ構成
実装
今回はよく使われるPythonより自分がよく使っているJuliaを使って実装します。
その中でも、Flux.jlとGen.jlの二種類を使って試してみました。
Flux.jlでは深層学習、Gen.jlではベイズロジスティック回帰をそれぞれ行っていきます。
Flux.jl
まず必要なモジュールを読み込みます。
using Flux
using Flux: crossentropy
using Flux: ADAM
using Flux: train!
using Flux: @epochs
using CSV
using DataFrames
using NNlib
using Base.Iterators: partition
using Statistics
using ProgressMeter
using MLDataUtils- 学習
train_df = CSV.File("./dataset/train.csv") |> DataFrame
test_df = CSV.File("./dataset/test.csv") |> DataFrame
train_X = train_df[!, Not(:item)] |> Array |> adjoint |> Array
train_Y = Flux.onehotbatch(train_df[!, :item], 0:2)
test_X = test_df[!, Not(:item)] |> Array |> adjoint |> Array
test_Y = Flux.onehotbatch(test_df[!, :item], 0:2)
layer_1 = Flux.Dense(size(train_X, 1), 32, NNlib.relu)
dropout_layer_1 = Flux.Dropout(0.5)
layer_2 = Flux.Dense(32, 32, NNlib.relu)
dropout_layer_2 = Flux.Dropout(0.5)
layer_3 = Flux.Dense(32, category_size)
model = Flux.Chain(layer_1, dropout_layer_1, layer_2, dropout_layer_2, layer_3, NNlib.softmax)
loss(x, y) = crossentropy(model(x), y)
accuracy(x, y) = mean(Flux.onecold(model(x)) .== Flux.onecold(y))
opt = ADAM()
early_stop = 0
epoch = 100
folds = kfolds((train_X, train_Y), k=10)
for ((X, Y), (val_X, val_Y)) in folds
cb() = loss(X, Y)
train_dataset = Flux.Data.DataLoader((X, Y), batchsize=32, shuffle=true)
for _ in 1:epoch
valid_loss = loss(val_X, val_Y)
train!(loss,
Flux.params(model),
train_dataset,
opt,
cb = Flux.throttle(cb, 10))
if valid_loss < loss(val_X, val_Y)
early_stop += 1
end
early_stop > 100 && break
end
early_stop > 100 && break
end
- 推論
accuracy(x, y) = mean(Flux.onecold(model(x)) .== Flux.onecold(y))
accuracy(train_X, train_Y)> 0.8105810473815462テストデータについても比較してみましょう。
accuracy(test_X, test_Y)> 0.7778542713567839まあまあな精度を出せたと思います。
様々な型で使うことのできるポケモンのアイテムを8割ないくらいで読めるなら充分なんじゃないかなあ。
Gen.jl
次はベイズロジスティック回帰を行っていきます。
using Gen
using CSV
using DataFrames
using Statistics
using ProgressMeter
using LinearAlgebra
using NNlib- フィッティング
train_df = CSV.File("./dataset/train.csv") |> DataFrame
test_df = CSV.File("./dataset/test.csv") |> DataFrame
train_X = Matrix{Float64}(train_df[!, Not(:item)])
test_X = Matrix{Float64}(test_df[!, Not(:item)])
train_Y = train_df[!, :item]
test_Y = test_df[!, :item]
@gen function logistic_model(x)
σ = 3.0
n, m = size(x)
y = Vector{Float64}(undef, n)
intercept1 = @trace(normal(0, σ), :intercept1)
intercept2 = @trace(normal(0, σ), :intercept2)
cofficient1 = @trace(mvnormal(zeros(m), Matrix(I * σ, m, m) * σ), :cofficient1)
cofficient2 = @trace(mvnormal(zeros(m), Matrix(I * σ, m, m) * σ), :cofficient2)
value1 = intercept1 .+ x * cofficient1
value2 = intercept2 .+ x * cofficient2
for i in 1:n
v = softmax([0, value1[i], value2[i]])
y[i] = @trace(Gen.categorical(v), (:y, i))
end
end
function do_inference(model, xs, ys, amount_of_computation)
observations = Gen.choicemap()
for (i, y) in enumerate(ys)
observations[(:y, i)] = y
end
(trace, _) = Gen.importance_resampling(model, (xs, ), observations, amount_of_computation);
return trace
end
trace = do_inference(logistic_model, train_X, train_Y, 1000)- 予測
function predict_new_data(model, trace, new_xs, param_addrs)
constraints = Gen.choicemap()
for addr in param_addrs
constraints[addr] = trace[addr]
end
(new_trace, _) = Gen.generate(model, (new_xs,), constraints)
n = size(new_xs, 1)
ys = [new_trace[(:y, i)] for i=1:n]
return ys
end
predict_data = predict_new_data(
logistic_model, trace, test_X,
[
:intercept1,
:intercept2,
:cofficient1,
:cofficient2,
])
Statistics.mean(predict_data .== test_Y)> 0.7376884422110553若干、こちらの方が低いですが大きな差はないですね。
興味のある方はデータをおいてるので、いろいろ試してみてください。

Tsukamoto Makoto
Company: Fusic CO., LTD. お仕事はRuby 趣味ではJulia jl.devというJuliaのユーザーグループの管理人しています。Juliaが好きな方は是非に〜