
Table of Contents
前提条件
今回の開発環境には、Docker を使用します。 OS はなんでも良いですが、Docker コンテナが動く環境を用意してください。 また、ディスクには 7GB 程度の空き容量があることが推奨されます。
筆者の検証環境は下記の通りです。
・MacBook Pro 2016 13-inch
・macOS 11.5.1 (Big Sur)
・デュアルコア Intel Core i7 3.3GHz
・16GB メモリ
S3 バケットの用意
Glue のデータソースとして、今回は S3 バケットを使用して、その中にある CSV ファイルについてデータの操作を行いたいと思います。 検証では大した費用にならないので実際の S3 を利用しますが、S3 の費用も気になる場合は MinIO などを利用すると良いかもしれません。 なお、今回の開発環境で MinIO が使用できるかどうかは未検証です。
というわけで、S3 バケットを作成していきます。 今回は、入力と出力のバケットは同じものを使用して、プレフィックスで切り分けていきたいと思います。
$ aws s3api create-bucket <検証用のバケット名>
作成したバケットの s3://<検証用のバケット名>/input/ を入力用のプレフィックス、s3://<検証用のバケット名>/output/ を出力用のプレフィックスとします。
Glue ETL 開発環境の構築
コンテナイメージの pull
まずはDocker のサービスを起動して、ターミナルで下記のコマンドを実行します。 かなりイメージが大きいので、ダウンロードに結構な時間がかかります。
$ docker pull amazon/aws-glue-libs:glue_libs_1.0.0_image_01
コンテナの起動
ダウンロードしたコンテナを起動します。 注意点としては、S3 に接続するためのクレデンシャルを実行時に渡してやる必要があるということです。 ホストの環境変数にクレデンシャルが設定されている場合は、下記のコマンドを実行することで ETL 開発用の Jupyter Notebook コンテナが起動します。
$ docker run -e AWS_ACCESS_KEY_ID \
-e AWS_SECRET_ACCESS_KEY \
-e AWS_DEFAULT_REGION \
-itd -p 8888:8888 -p 4040:4040 -v ~/.aws:/root/.aws:ro --name glue_jupyter \
amazon/aws-glue-libs:glue_libs_1.0.0_image_01 \
/home/jupyter/jupyter_start.sh
環境変数を直接渡したい場合は、下記の様に実行しても良いです。
$ docker run -e AWS_ACCESS_KEY_ID="アクセスキー" \
-e AWS_SECRET_ACCESS_KEY="シークレットキー" \
-e AWS_DEFAULT_REGION="リージョン" \
-itd -p 8888:8888 -p 4040:4040 -v ~/.aws:/root/.aws:ro --name glue_jupyter \
amazon/aws-glue-libs:glue_libs_1.0.0_image_01 \
/home/jupyter/jupyter_start.sh
コンテナが起動したら、下記 URL にブラウザでアクセスします。
http://localhost:8080
無事に Jupyter Notebook が起動しました。 早速、ETL スクリプトを開発していきましょう。新しい Python 3 スクリプトを作成します。
今回は、Glue Studio で自動作成されたスクリプトを参考にスクリプトを記載していくのですが、 1点注意事項があって、実際の Glue 実行時には、引数として JOB の情報が渡ってくるのですが、Jupyter で実行する際には引数を渡すことができません。
なので、
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
のようになっている部分を
## @params: [JOB_NAME]
args = {}
args["format_options"] = {"quoteChar":"\"","escaper":"","withHeader":True,"separator":","}
args["connection_type"] = "s3"
args["format"] = "csv"
args["connection_options"] = {"paths": ["s3://<検証用のバケット名>/input/"], "recurse":True}
args["transformation_ctx"] = "DataSource0"
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init("LOCAL_JOB", args)
のように書き換えて実行しないとエラーになります。 ここについて、うまいやり方を知っている方がいましたら、教えていただけると幸いです。
書き換えたコードは大体下記のようになるかと思います。
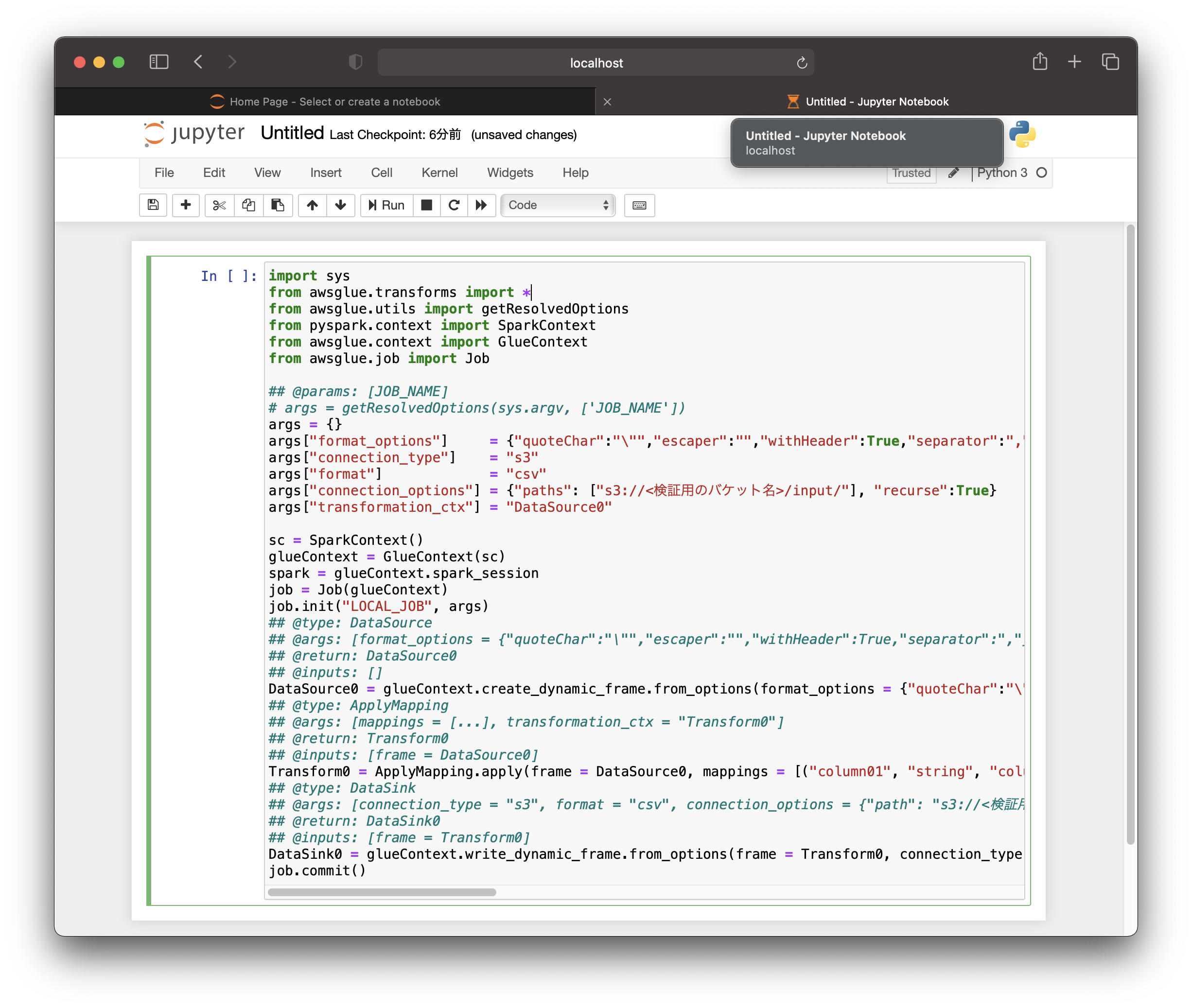
このコードを実行することで、input プレフィックス配下にある CSV ファイルに対してローカルでデータ変換が実行され、output プレフィックス配下に変換後のデータが格納されます。
最後に
今回は、AWS Glue の ETL スクリプトをローカルで開発するための環境を構築しました。 マネジメントコンソール上で試行錯誤しても良いのですが、無駄な料金が発生してしまうことになるので、ローカルで開発するメリットは大きいと思います。
是非、皆様も Glue のスクリプトを実装する際は、ローカル環境を構築して効率的に開発してください。 それでは、皆様もよい Glue ライフを。
k-masatany
インターネットの海で泳ぐときは、だいたいペンギンの姿をしています。