
Table of Contents
株式会社Fusic 事業本部 クラウドエンジニアリング部門 プリンシパルエンジニアの清家(@seike460)です。
複数の顧客プロジェクトでAIコーディングを実践する中で、いわゆる「バイブコーディング」の限界を感じていました。この課題を組織として共有するため、AWSが提唱するAI-DLC(AI-Driven Development Life Cycle)の社内ワークショップを約20名の参加で実施したので、その実践内容と得られた知見を共有します。

なぜバイブコーディングでは不十分なのか
AIコーディングツールが登場した当初、正直なところ全能感がありました。Claude Codeに何でも任せれば良いという感覚です。ただ、それを本番環境に投入しようとすると話が変わります。
実際に起きた問題を整理すると、根本原因はAIの能力ではなく、AIに渡す情報の構造化にありました。
| 課題 | 根本原因 |
|---|---|
| 機能追加したら関係ないところが壊れた | 設計文脈がAIに伝わっていない |
| 昨日AIに聞いたことを今日知らない | セッション間で文脈が喪失する |
| 同じ指示で毎回異なる結果が返る | 要件が構造化されていない |
| テスト設計が後回しになる | 品質基準が明示されていない |
AIは優秀な実装者ですが、要件・設計・品質の構造を人間側が整えないと力を引き出せません。この構造化を体系的に行う手法がAI-DLCです。
AI-DLC(AI-Driven Development Life Cycle)とは
AI-DLCはAWSがre:Invent 2025で発表した開発手法です。単なるツールの話ではなく、ソフトウェア開発の進め方そのものを再構築する考え方で、論文レベルで体系化されています。実装は awslabs/aidlc-workflows としてOSS公開されています。
3つのフェーズ
- Inception — What/Whyを決める。要件定義・設計の構造化
- Construction — Howを決めて作る。設計・実装・テスト
- Operation — デプロイ・運用・モニタリング
このサイクルを回すことで、システムが漸進的に改善されていきます。
ワークフローが仕事に適応する
AI-DLCの重要な特徴は、AIがユーザーの意図・既存コードの状態・変更の複雑さを分析し、必要なステージだけを実行する点です。シンプルなバグ修正にはシンプルに、複雑なシステム変更には包括的に対応します。
もう一つの核心がHuman in the Loopです。AIが主導しつつ、各ステージの完了時に必ず人間の承認を求めます。やり取りは audit.md にISO 8601タイムスタンプ付きで記録されるため、いつ・誰が・何を決定したかを追跡できます。
ワークショップ教材の設計
参加者がAI-DLCをすぐ体験できるよう、TODOアプリのリポジトリ fusic/todo-ai-dlc を教材として用意しました。
AWSアーキテクチャ
典型的なServerless構成です。
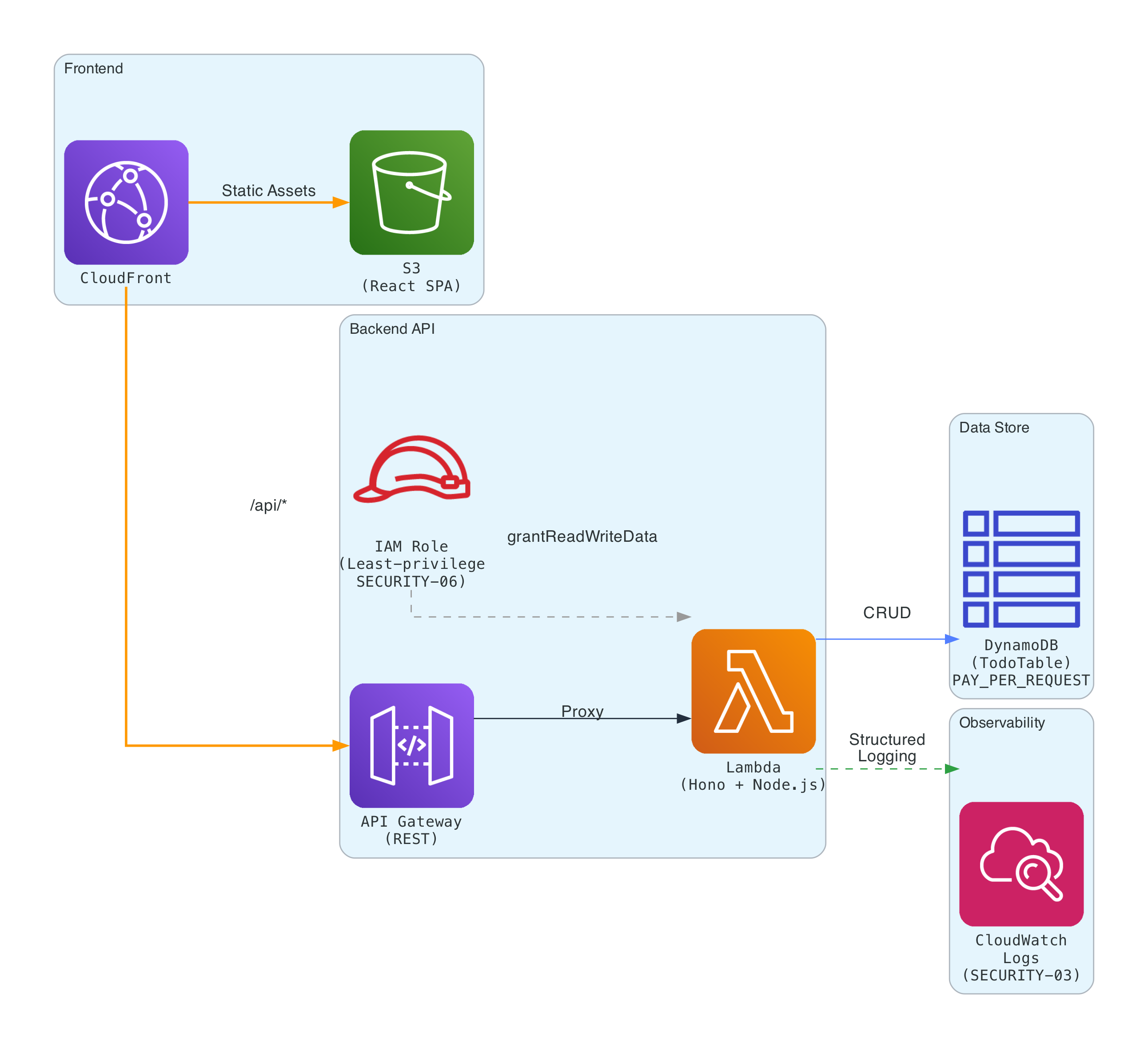
AI-DLCのInfrastructure Designステージが、Reverse Engineeringで読み取った既存のCDK Stackをもとに、このアーキテクチャを自動マッピングしました。
DynamoDBのPAY_PER_REQUESTはServerlessに合わせたコスト最適化、Lambdaへの grantReadWriteData のみの付与はSecurity ExtensionのSECURITY-06(最小権限の原則)、CloudWatch Logsへの構造化ロギングはSECURITY-03に基づく設計です。
AI-DLCのフェーズフロー
3フェーズの連携を図示します。
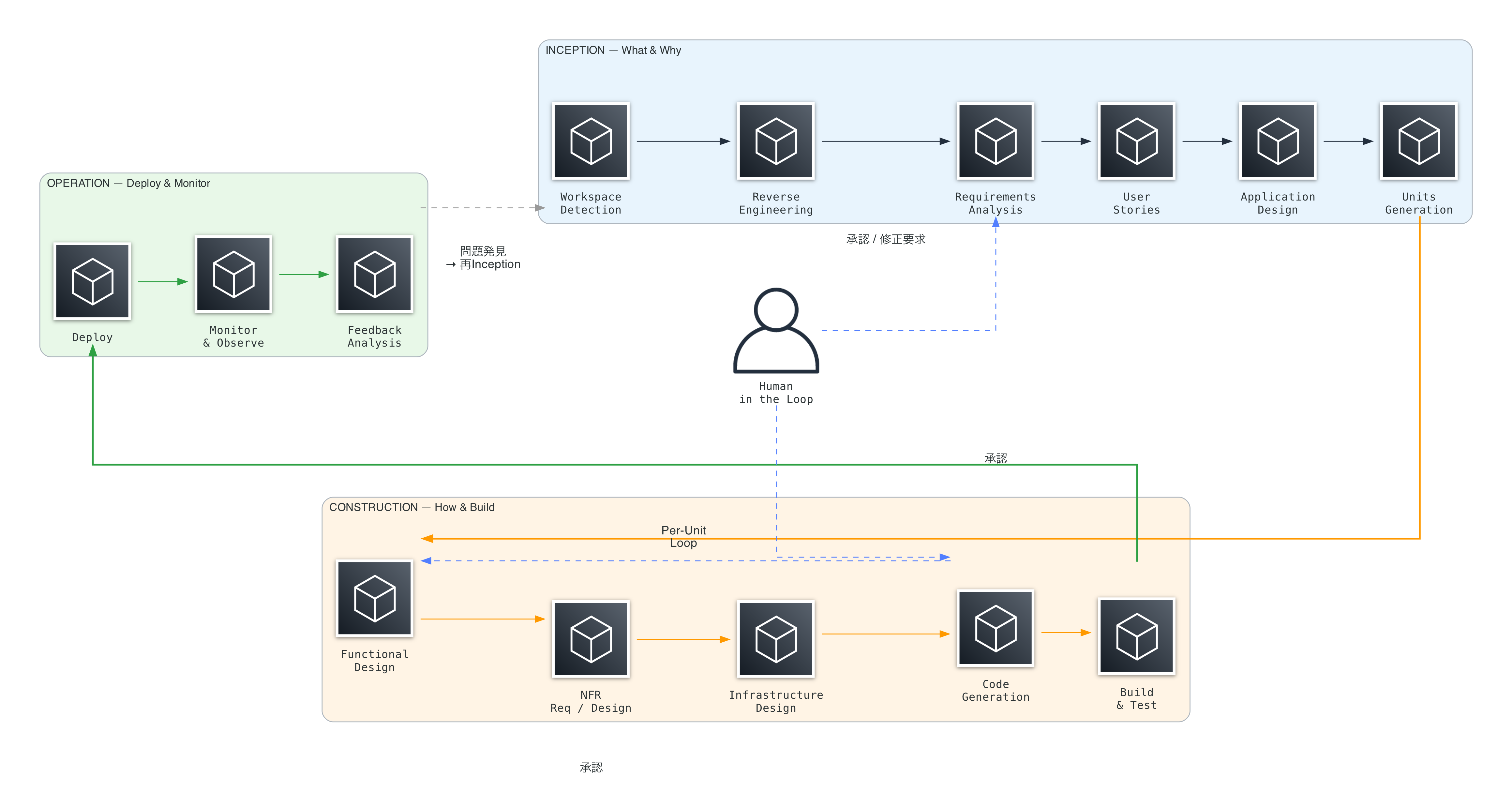
Inceptionで構造化された要件が承認を経てConstructionに渡り、全ユニット完了後にOperationへ。問題発見時はフィードバックループで再びInceptionに戻ります。図中央のHuman in the Loopが、Requirements AnalysisとCode Generationの両方に関与しています。
技術スタック
pnpmワークスペースによるモノレポ構成で、以下を採用しています。
| レイヤー | 技術 | 選定理由 |
|---|---|---|
| Frontend | React 19 + Vite + Tailwind CSS | 最新のReact機能、高速なビルド |
| Backend | Hono 4.6 + Zod | Lambda-nativeな軽量FW、API境界でのランタイム型安全性 |
| Database | DynamoDB (AWS SDK v3) | Serverlessとの親和性、スキーマレスな柔軟性 |
| Infrastructure | AWS CDK (TypeScript) | アプリコードとIaCの言語統一 |
| Testing | Vitest + React Testing Library | 高速なテスト実行、コンポーネントテスト |
| Code Quality | Biome | リンティングとフォーマットの統一 |
| ID生成 | ULID | 時間順序付きの分散ID |
複数IDE対応
もちろん大前提になっている Kiro では .kiro/steering/ のステアリングファイルがそのまま効きますし、Claude Code、Codex、Cursor、GitHub Copilot でも動くよう.claude/commands/ と .codex/skills/ の両方に AI-DLC コマンドを配置しました。
当日も参加者の環境はバラバラでしたが、多くの参加者が Inception を完了できていました。
実践:Inceptionフェーズ
Inceptionでは、What(何を作るか)とWhy(なぜ作るか)を構造化します。ワークショップでは、既存TODOアプリに「タグ機能」と「検索機能」を追加する要件でInceptionを実行しました。
1. Workspace Detection
まずプロジェクトの状態を検出します。既存コードがあればBrownfield、なければGreenfieldです。今回はBrownfieldと判定され、後続のReverse Engineeringが自動的に有効化されました。Greenfieldならスキップされます。
プロジェクトの状態に応じてワークフローが適応する、これがAI-DLCの基本的な動き方です。
2. Reverse Engineering
Brownfieldでは既存コードの自動分析が走ります。プロジェクト構造(pnpmモノレポ)、使用技術(React, Hono, CDK, Vitest, Biome)、データモデル、API構造、依存関係が構造化されます。
参加者がタグ機能を要件として入力した時点で、AI-DLCは「タグという概念が現在のアプリには存在しない」ことを把握済みでした。
3. Requirements Analysis(適応的深度)
要件分析には適応的深度(Adaptive Depth)があります。depth-levels.md で定義されており、6つの要素(リクエストの明確さ、問題の複雑さ、スコープ、リスク、コンテキスト、ユーザーの嗜好)から深度が決まります。
| 深度 | 適用場面 | 成果物の詳細度 |
|---|---|---|
| Minimal | バグ修正、単純な変更 | 簡潔な要件、最小限の質問 |
| Standard | 通常のプロジェクト | 完全なrequirements.md、機能・非機能要件 |
| Comprehensive | 複雑・高リスク | トレーサビリティマトリクス、10問以上の質問、設計代替案 |
今回のタグ機能追加はMinimal判定でした。一般的な要件で複雑さが低いためです。顧客の業務システムのような複雑な要件ではComprehensiveが適用され、より詳細な質問と検証が行われます。
"Keep this at minimal depth" や "Please run at comprehensive depth" で明示的に制御することも可能です。
4. Application Design → Unit of Work分解
Inceptionの最終ステージで、要件がUnit of Work(作業単位)に分解されます。
| Requirement | backend | frontend | infrastructure |
|---|---|---|---|
| FR-001: TODO 作成 | POST /api/todos + Repository.create | TodoForm + handleCreate | Lambda + API Gateway + DynamoDB |
| FR-002: TODO 一覧表示 | GET /api/todos + Repository.findAll | TodoList (useEffect) | Lambda + API Gateway + DynamoDB |
| FR-003: TODO 更新 | PUT /api/todos/:id + Repository.update | TodoItem (edit/toggle) | Lambda + API Gateway + DynamoDB |
| FR-004: TODO 削除 | DELETE /api/todos/:id + Repository.delete | TodoItem (delete) | Lambda + API Gateway + DynamoDB |backend・frontend・infrastructureの各ユニットに100%マッピングされており、Constructionで何を実装すべきかが明確になっています。
実践:Constructionフェーズ
Inceptionで「何を作るか」が固まったら、Constructionで「どう作るか」を決めて実装します。
Per-Unit Loop
各ユニット(backend, frontend, infrastructure)に対して以下を順次実行します。
Per-Unit Loop(ユニットごとに実行)
├── Functional Design(条件付き)— ビジネスロジックの技術非依存な設計
├── NFR Requirements(条件付き)— 非機能要件の分析
├── NFR Design(条件付き)— 非機能要件の設計
├── Infrastructure Design(条件付き)— インフラマッピング
└── Code Generation(必須)— 計画→承認→実装
各ユニットが完了してから次へ進み、全ユニット完了後にBuild and Test(統合テスト)が走ります。
Functional Design
ReactやHonoといった技術スタックを排除した、純粋なビジネスロジック設計です。Clean Architectureでいえば最も内側のドメイン層に相当します。
TODOの作成におけるビジネスルール(タイトル必須・最大100文字、タグは最大5個など)がここで定義され、技術的な実装は後続のCode Generationに委ねられます。
Code Generation:生成されたコードの実際
Code Generationは、まず詳細な実装計画(チェックリスト付き)を生成し、承認を得てから実行します。
実際に生成されたバックエンドのエントリポイントがこちらです。
// packages/backend/src/index.ts
import { Hono } from "hono";
import { cors } from "hono/cors";
import { logger } from "hono/logger";
import { handle } from "hono/aws-lambda";
import { todosRoute } from "./routes/todos";
const app = new Hono();
// Middleware (SECURITY-03: structured logging)
app.use("*", cors());
app.use("*", logger());
// Global error handler (SECURITY-15: fail-safe defaults, SECURITY-09: no stack traces)
app.onError((err, c) => {
console.error("Unhandled error:", err.message);
return c.json({ error: "Internal server error" }, 500);
});
// Routes
app.route("/api/todos", todosRoute);
// Health check
app.get("/api/health", (c) => c.json({ status: "ok" }));
// Lambda handler export
export const handler = handle(app);コメントに SECURITY-03、SECURITY-15、SECURITY-09 というSecurity ExtensionのルールIDが残っています。これはAI-DLCがSecurity Baselineの15ルール(OWASP Top 10 (2025)マッピング)に自動的に準拠したコードを生成した痕跡です。
具体的には、SECURITY-03が「構造化ロギング」、SECURITY-15が「fail-safe defaults」、SECURITY-09が「スタックトレースを返さない」。ExtensionsのBlocking Constraintにより、これらを満たさないとステージが進行しない仕組みになっています。
フロントエンドも見てみます。
// packages/frontend/src/components/TodoForm.tsx
import { useState, type FormEvent } from "react";
import type { CreateTodoInput } from "../types/todo";
interface TodoFormProps {
onSubmit: (input: CreateTodoInput) => Promise<void>;
}
export function TodoForm({ onSubmit }: TodoFormProps) {
const [title, setTitle] = useState("");
const [description, setDescription] = useState("");
const [isSubmitting, setIsSubmitting] = useState(false);
async function handleSubmit(e: FormEvent) {
e.preventDefault();
if (!title.trim()) return;
setIsSubmitting(true);
try {
await onSubmit({
title: title.trim(),
description: description.trim() || undefined,
});
setTitle("");
setDescription("");
} finally {
setIsSubmitting(false);
}
}
return (
<form onSubmit={handleSubmit} data-testid="todo-form" className="space-y-3">
<div>
<input
type="text"
value={title}
onChange={(e) => setTitle(e.target.value)}
placeholder="TODO タイトル"
data-testid="todo-form-title-input"
maxLength={200}
className="w-full rounded-lg border border-gray-300 px-4 py-2 ..."
/>
</div>
{/* description textarea, submit button */}
</form>
);
}data-testid が標準で付与されているのは、Build and Testステージを見据えた設計です。React Testing Libraryでのテストがそのまま書けます。maxLength はSECURITY-05(Input Validation)の一環でもあります。
ワークショップで出た議論と回答
当日は参加者から多くの質問が出ました。ワークショップ後に awslabs/aidlc-workflows のルールファイルを改めて調査したので、当日答えきれなかったものも含めてまとめます。
Q1: Inceptionの成果物はドキュメントとして残るのか?
残ります。aidlc-docs/inception/ 配下に永続的に保存されます。
セッション継続性は session-continuity.md で定義されていて、再開時にはまず aidlc-state.md を読み込んで前回のステージから再開します。ワークショップで実際に生成された aidlc-state.md がこちらです。
# AI-DLC State Tracking
## Project Information
- **Project Type**: Brownfield
- **Start Date**: 2026-03-12T00:00:00Z
- **Current Stage**: INCEPTION - Workspace Detection
## Extension Configuration
- **Security Extensions**:
- **Enabled**: true
## Stage Progress
| Phase | Stage | Status |
|---|---|---|
| INCEPTION | Workspace Detection | IN_PROGRESS |
| INCEPTION | Reverse Engineering | PENDING |
| INCEPTION | Requirements Analysis | PENDING |
| ...(以下略)Brownfield判定、Security Extensions有効化、各ステージの進捗がテーブルで管理されており、セッションをまたいでも状態が保持されます。
成果物のディレクトリ構造は GENERATED_DOCS_REFERENCE.md で以下のように定義されています。
aidlc-docs/
├── aidlc-state.md # 状態追跡
├── audit.md # 全意思決定の監査証跡
└── inception/
├── plans/ # 実行計画
├── reverse-engineering/ # 既存コード分析
├── requirements/ # 構造化された要件
├── user-stories/ # ユーザーストーリー
└── application-design/ # コンポーネント設計、Unit of Work
Q2: チーム開発ではどう運用するのか?
現状のAI-DLCには、per-featureディレクトリの組み込みサポートはありません。WORKING-WITH-AIDLC.md では単一の aidlc-docs/ を前提に、チーム協調はApproval Gates(承認ゲート)で実現する設計です。
具体的には、質問ファイル(requirement-verification-questions.md)にチームメンバーが共同で回答し、設計レビューを経て承認するフローになります。
ワークショップで提案のあったサブディレクトリ方式は、AI-DLCの設計と整合性があります。
aidlc-docs/inception/
├── reverse-engineering/ # 共有(変更なし)
├── tag-feature/ # Feature単位
│ ├── plans/
│ ├── requirements/
│ ├── user-stories/
│ └── application-design/
reverse-engineering/ を共通資産として全Feature間で参照し、それ以外をFeatureディレクトリに分離する方式です。Extensionsでこの構造を強制するルールを追加すれば、運用を標準化できます。
Q3: Inceptionを再実行すると成果物は削除されるか?
自動削除されません。workspace-detection.md の定義によると、aidlc-state.md が存在すれば前回から再開、存在しなければ新規開始です。Reverse Engineering成果物には鮮度チェックがあり、最新ならスキップ、古ければ再生成されます。
「最初からやり直したい」場合は、error-handling.md に従い既存成果物が .backup としてアーカイブされた上で再実行されます。
自分の運用では、Inceptionの成果物を別途ドキュメントディレクトリに退避してからクリーンに開始しています。「Inceptionは今からやることの仕様」なので、過去の仕様が混在すると文脈が汚れるからです。
Q4: Extensionsとは何か?チームでどうカスタマイズするか?
Extensionsはコアワークフローに重ねるブロッキング制約ルールです。非準拠ならステージが進行しません。
組み込みでSecurity Baseline(SECURITY-01〜15、OWASP Top 10マッピング)とProperty-Based Testing(PBT-01〜10)が用意されています。
カスタムExtensionは以下の構造で追加します。
extensions/
└── fusic/
└── development-policy/
├── development-policy.md # ルール定義
└── development-policy.opt-in.md # Opt-In質問
Opt-In機構があり、Requirements Analysis時にユーザーに有効化するか質問します。有効化された場合のみルールファイルがロードされるので、コンテキストウィンドウを圧迫しません。
Fusicの開発ポリシー(Biome必須、TypeScript strict mode等)をここに定義すれば、AI-DLCの全ステージで横断的にチェックが走ります。
Q5: Human in the Loopの具体的な仕組みは?
2つのメカニズムがあります。
1つ目は質問ファイルです。AIが requirement-verification-questions.md に多肢選択式の質問を生成して停止します。チームはオフラインで回答を記入し、完了後にAIに再読み込みを指示します。
## Question: デプロイモデル
A) AWS Lambda (Serverless)
B) AWS ECS Fargate (コンテナ)
C) 既存のオンプレミスインフラ
X) その他([Answer]: タグの後に記述してください)
[Answer]: A2つ目は承認ゲートです。各ステージ完了後に「Request Changes」と「Approve & Continue」の2択が提示され、明示的な承認なしには進みません。Extension違反があると「Approve」自体が消えます。
Q6: AI-DLCの高速サイクルと顧客環境の現実
ワークショップでは、AWSのパートナーソリューションアーキテクトの方が「ガンガン回せばいい」と言っていたのに対して、「顧客環境でそれは無理では?」という議論になりました。
AI-DLCの思想はInceptionを高速にサイクルさせるアプローチですが、顧客環境では本番デプロイ後のバグ発覚は許容されにくい。このギャップに対する現時点の私の回答は3つです。
- dev環境ではAI-DLCサイクルを高速に回して問題発見を早期化する
- staging/prodにはExtensionsで品質ゲートを強化する(Security Baselineに加え、独自チェック)
- Taktを使ったマルチエージェントパイプライン(実装はCodex、レビューはClaude Code)でConstruction品質を上げる
Fusic仕様駆動開発(SDD)との統合
Fusicでは社内の有志メンバーを中心に、仕様駆動開発(Spec-Driven Development)の取り組みが進んでいます。今回のワークショップで両者の関係が見えてきました。
- SDD ≈ Inception — 仕様を構造化するフェーズ
- 実装 ≈ Construction — 仕様に基づいて実装するフェーズ
ワークショップと同日、社内で開発中のAIエージェント向けプラグイン基盤にもAI-DLCの概念(監査証跡・適応的深度・Extensions)を取り入れるPRが出ていました。Slackでも「AI-DLCはspec driven devをめっちゃ細かく分解してステップを踏んで進めてる感じ」というコメントがあり、方向性が一致していることを確認できています。
まとめ
AI-DLCは手段であり目的ではありません。大事なのは「AIに渡す情報を構造化する」という考え方で、AI-DLCはそのフレームワークです。
段階的に導入するなら、
- Phase 1: まず個人プロジェクトでInception → Constructionの流れを体感する
- Phase 2: Extensionsでチーム固有のルール(セキュリティ基準、コーディング規約)を追加する
- Phase 3: サブディレクトリ設計やPRレビューフローでチーム運用に乗せる
というステップが現実的です。
今回約20名で同時にInceptionを回してみて、「構造化されたコンテキストをAIに渡すだけでここまで出力品質が変わるのか」というのが一番の実感でした。AI-DLCのOSSは活発に更新されている(2026年3月時点でv0.1.6)ので、興味のある方はまず awslabs/aidlc-workflows を覗いてみてください。

shiro seike / せいけ しろう / 清家 史郎
Company:Fusic CO., LTD. Slides:slide.seike460.com blog:blog.seike460.com Program Language:PHP , Go Interest:Full Serverless Architecture
Related Posts
shiro seike / せいけ しろう / 清家 史郎
2025/12/21
Guiart Thomas
2025/12/16