
やったこと
- Google Colaboratory(以下、Colab)でTPUを使ってPix2Pixを動かしてみた
- 本当は実行時間の比較をして
TPUすげぇ!って持っていこうとしていたのですが、今回の実験ではGPUのほうが早かったので、その部分はサラッと触れる程度にします
- 本当は実行時間の比較をして
前提
- TPUはEager Executionでは動かない
- tf.kerasではTPUを使ったpredictにバグが有る(TF1.12で直るらしい)
- Estimator形式でTPUを使う
- EstimatorでTPUを使う際はデータの取得先、モデルの保存先をGoogleCloudStorage(以降、gcs)にする必要がある
実験環境
- Colabのため詳細は割愛
学習データ
- 256×256×3チャンネル、400枚
コード
以下のような流れで進めます。
- 前処理
- GPUのコード
- GPUとTPUのコードのdiff
- 解説
なお、コードはTensorFlow Tutorialを参考にEstimator形式にしたものです
今回は動かすことを目的としたため、簡略化しています
性能を求めるのであれば、少なくともBatchNormalizationやDropoutを追加する必要があると思います
前処理
データセットをgcsにアップロードしておきます
import tensorflow as tf
import os
import time
import numpy as np
import matplotlib.pyplot as plt
use_tpu = True
if 'COLAB_TPU_ADDR' in os.environ:
TF_MASTER = 'grpc://{}'.format(os.environ['COLAB_TPU_ADDR'])
bucket_name = '<バケット名>' #@param {type:"string"}
assert bucket_name, 'Must specify an existing GCS bucket name'
print('Using bucket: {}'.format(bucket_name))
from google.colab import auth
auth.authenticate_user()
if use_tpu:
assert 'COLAB_TPU_ADDR' in os.environ, 'Missing TPU; did you request a TPU in Notebook Settings?'
MODEL_DIR = 'gs://{}/model/tpu/{}'.format(bucket_name, time.strftime('%Y-%m-%d-%H-%M-%S'))
print('Using model dir: {}'.format(MODEL_DIR))
origin_url = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'
path_to_zip = tf.keras.utils.get_file('facades.tar.gz', cache_subdir=os.path.abspath('.'), origin=origin_url, extract=True)
data_path = Path(path_to_zip).parent.joinpath('facades')
for i in ['train', 'val', 'test']:
print(i, len(list(data_path.joinpath(i).glob('*.jpg'))))
def create_service():
return discovery.build('storage', 'v1')
def upload_objects(bucket, paths):
service = create_service()
for path in paths:
body = {'name': 'data/' + '/'.join(str(path).split('/')[3:]),}
with open(path, 'rb') as f:
req = service.objects().insert(bucket=bucket, body=body, media_body=http.MediaIoBaseUpload(f, 'application/octet-stream'))
resp = req.execute()
upload_objects(bucket_name, data_path.glob('*/*.jpg'))
GPU
import tensorflow as tf
import os
import time
import numpy as np
import matplotlib.pyplot as plt
bucket\_name = '' #@param {type:"string"}
assert bucket\_name, 'Must specify an existing GCS bucket name'
print('Using bucket: {}'.format(bucket\_name))
from google.colab import auth
auth.authenticate\_user()
MODEL\_DIR = 'gs://{}/model/gpu/{}'.format(bucket\_name, time.strftime('%Y-%m-%d-%H-%M-%S'))
print('Using model dir: {}'.format(MODEL\_DIR))
tf.test.gpu\_device\_name()
BUFFER\_SIZE = 400
TRAIN\_BATCH\_SIZE = 1
TEST\_BATCH\_SIZE = 1
IMG\_WIDTH = 256
IMG\_HEIGHT = 256
def load\_image(image\_file, is\_train):
image = tf.read\_file(image\_file)
image = tf.image.decode\_jpeg(image)
w = tf.shape(image)[1]
w = w // 2
real\_image = image[:, :w, :]
input\_image = image[:, w:, :]
input\_image = tf.cast(input\_image, tf.float32)
real\_image = tf.cast(real\_image, tf.float32)
if is\_train:
# random jittering
# resizing to 286 x 286 x 3
input\_image = tf.image.resize\_images(input\_image, [286, 286],
align\_corners=True,
method=tf.image.ResizeMethod.NEAREST\_NEIGHBOR)
real\_image = tf.image.resize\_images(real\_image, [286, 286],
align\_corners=True,
method=tf.image.ResizeMethod.NEAREST\_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
stacked\_image = tf.stack([input\_image, real\_image], axis=0)
cropped\_image = tf.random\_crop(stacked\_image, size=[2, IMG\_HEIGHT, IMG\_WIDTH, 3])
input\_image, real\_image = cropped\_image[0], cropped\_image[1]
if np.random.random() \> 0.5:
# random mirroring
input\_image = tf.image.flip\_left\_right(input\_image)
real\_image = tf.image.flip\_left\_right(real\_image)
else:
input\_image = tf.image.resize\_images(input\_image, size=[IMG\_HEIGHT, IMG\_WIDTH],
align\_corners=True, method=2)
real\_image = tf.image.resize\_images(real\_image, size=[IMG\_HEIGHT, IMG\_WIDTH],
align\_corners=True, method=2)
input\_image = (input\_image / 127.5) - 1
real\_image = (real\_image / 127.5) - 1
return input\_image, real\_image
def train\_input\_fn(params):
dataset = tf.data.Dataset.list\_files( 'gs://{}/data/train/\*.jpg'.format(bucket\_name))
batch\_size = params['batch\_size']
dataset = dataset.shuffle(BUFFER\_SIZE)
dataset = dataset.map(lambda x: load\_image(x, True))
dataset = dataset.batch(batch\_size, drop\_remainder=True).repeat()
dataset = dataset.prefetch(2)
return dataset
def test\_input\_fn(params):
dataset = tf.data.Dataset.list\_files( 'gs://{}/data/val/1\*.jpg'.format(bucket\_name))
batch\_size = params['batch\_size']
dataset = dataset.map(lambda x: load\_image(x, False))
dataset = dataset.batch(batch\_size, drop\_remainder=True)
dataset = dataset.prefetch(2)
return dataset
class Pix2pix:
def \_\_init\_\_(self):
pass
def model\_fn(self, features, labels, mode):
input\_img = tf.reshape(features, [-1, 256, 256, 3], name='input\_img')
if mode != tf.estimator.ModeKeys.PREDICT:
answer\_img = tf.reshape(labels, [-1, 256, 256, 3], name='answer\_img')
def generator(input\_data):
with tf.variable\_scope('generator'):
d1 = tf.layers.conv2d(input\_data, 64, 4, 2, padding='same', activation=tf.nn.leaky\_relu, name='unet\_d1')
d2 = tf.layers.conv2d(d1, 128, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d2')
d3 = tf.layers.conv2d(d2, 256, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d3')
d4 = tf.layers.conv2d(d3, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d4')
d5 = tf.layers.conv2d(d4, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d5')
d6 = tf.layers.conv2d(d5, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d6')
d7 = tf.layers.conv2d(d6, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d7')
d8 = tf.layers.conv2d(d7, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_d8')
u1 = tf.layers.conv2d\_transpose(d8, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u1')
u1\_ = tf.concat([u1, d7], axis=-1)
u2 = tf.layers.conv2d\_transpose(u1\_, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u2')
u2\_ = tf.concat([u2, d6], axis=-1)
u3 = tf.layers.conv2d\_transpose(u2\_, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u3')
u3\_ = tf.concat([u3, d5], axis=-1)
u4 = tf.layers.conv2d\_transpose(u3\_, 512, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u4')
u4\_ = tf.concat([u4, d4], axis=-1)
u5 = tf.layers.conv2d\_transpose(u4\_, 256, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u5')
u5\_ = tf.concat([u5, d3], axis=-1)
u6 = tf.layers.conv2d\_transpose(u5\_, 128, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u6')
u6\_ = tf.concat([u6, d2], axis=-1)
u7 = tf.layers.conv2d\_transpose(u6\_, 64, 4, 2, padding='same', activation=tf.nn.relu, name='unet\_u7')
u7\_ = tf.concat([u7, d1], axis=-1)
last = tf.layers.conv2d\_transpose(u7\_, 3, 4, 2, padding='same', activation=tf.nn.tanh, name='unet\_last')
return last
# Discriminator
def discriminator(input\_data, target\_data, reuse=False):
with tf.variable\_scope('discriminator', reuse=tf.AUTO\_REUSE):
con = tf.concat([input\_data, target\_data], axis=-1)
l1 = tf.layers.conv2d(con, 16, 3, 3, padding='same', activation=tf.nn.leaky\_relu, name='patch\_gan\_l1')
l2 = tf.layers.conv2d(l1, 32, 3, 3, padding='same', activation=tf.nn.leaky\_relu, name='patch\_gan\_l2')
l3 = tf.layers.conv2d(l2, 64, 3, 3, padding='same', activation=tf.nn.leaky\_relu, name='patch\_gan\_l3')
flat = tf.layers.flatten(l3, name='patch\_gan\_flat')
d1 = tf.layers.dense(flat, 128, activation=tf.nn.leaky\_relu, name='patch\_gan\_d1')
dr1 = tf.layers.dropout(d1, rate=0.5, name='patch\_gan\_dr1')
d2 = tf.layers.dense(dr1, 16, activation=tf.nn.leaky\_relu, name='patch\_gan\_d2')
dr2 = tf.layers.dropout(d2, rate=0.5, name='patch\_gan\_dr2')
output = tf.layers.dense(dr2, 1, activation=tf.nn.sigmoid, name='patch\_gan\_output')
return output
if mode == tf.estimator.ModeKeys.PREDICT:
last\_unet = generator(input\_img)
predictions = {
'input': input\_img,
'last\_unet': last\_unet,
}
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
EPS = 1e-12
last\_unet = generator(input\_img)
loss\_l1 = tf.losses.mean\_squared\_error(last\_unet, answer\_img)
d1 = discriminator(input\_img, answer\_img) + EPS
d2 = discriminator(input\_img, last\_unet, reuse=True) + EPS
loss\_d = tf.reduce\_mean(-(tf.log(d1 + EPS) + tf.log(1 - d2 + EPS)), name='loss\_d')
loss\_g\_GAN = tf.reduce\_mean(-tf.log(d2 + EPS))
loss\_g = tf.add(tf.multiply(loss\_l1, 100), loss\_g\_GAN, name='loss\_g')
loss = loss\_d + loss\_g
t\_vars = tf.trainable\_variables()
d\_vars = [var for var in t\_vars if 'discriminator' in var.name]
g\_vars = [var for var in t\_vars if 'generator' in var.name]
optm\_d = tf.train.AdamOptimizer(learning\_rate=0.0005)
optm\_g = tf.train.AdamOptimizer(learning\_rate=0.001)
train\_d = optm\_d.minimize(loss\_d, var\_list=d\_vars, global\_step=tf.train.get\_global\_step())
train\_g = optm\_g.minimize(loss\_g, var\_list=g\_vars, global\_step=tf.train.get\_global\_step())
tf\_group = tf.group([train\_d, train\_g])
return tf.estimator.EstimatorSpec(mode=mode, train\_op=tf\_group, loss=loss)
run\_config = tf.estimator.RunConfig(
save\_checkpoints\_steps=100,
save\_summary\_steps=100,
model\_dir=MODEL\_DIR)
p = Pix2pix()
estimator = tf.estimator.Estimator(
model\_fn=p.model\_fn,
config=run\_config
)
start = time.time()
estimator.train(
input\_fn=lambda:train\_input\_fn({'batch\_size': TRAIN\_BATCH\_SIZE}),
max\_steps=100
)
elapsed\_time = time.time() - start
print ("elapsed\_time:{0}".format(elapsed\_time) + "[sec]")
pred = list(estimator.predict(input\_fn=lambda:test\_input\_fn({'batch\_size': TEST\_BATCH\_SIZE})))
plt.figure(figsize=(15,15))
display\_list = [pred[0]['input'], pred[0]['last\_unet']]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
plt.imshow(display\_list[i] \* 0.5 + 0.5)
plt.axis('off')
plt.show()
GPUとTPUのコードのdiff
-がGPU、+がTPUです
※diffコマンドの出力そのままではなく、少し見やすいように加工しています
--- pix2pix\_estimator\_gpu.py 2018-11-01 10:36:28.000000000 +0900
+++ pix2pix\_estimator\_tpu.py 2018-11-01 10:36:43.000000000 +0900
@@ -11,6 +11,11 @@
import numpy as np
import matplotlib.pyplot as plt
+use\_tpu = True
+
+if 'COLAB\_TPU\_ADDR' in os.environ:
+ TF\_MASTER = 'grpc://{}'.format(os.environ['COLAB\_TPU\_ADDR'])
+
bucket\_name = '' #@param {type:"string"}
assert bucket\_name, 'Must specify an existing GCS bucket name'
@@ -19,15 +24,15 @@
from google.colab import auth
auth.authenticate\_user()
-MODEL\_DIR = 'gs://{}/model/gpu/{}'.format(bucket\_name, time.strftime('%Y-%m-%d-%H-%M-%S'))
+MODEL\_DIR = 'gs://{}/model/tpu/{}'.format(bucket\_name, time.strftime('%Y-%m-%d-%H-%M-%S'))
+if use\_tpu:
+ assert 'COLAB\_TPU\_ADDR' in os.environ, 'Missing TPU; did you request a TPU in Notebook Settings?'
-tf.test.gpu\_device\_name()
BUFFER\_SIZE = 400
-TRAIN\_BATCH\_SIZE = 1
-TEST\_BATCH\_SIZE = 1
+TRAIN\_BATCH\_SIZE = 8
+TEST\_BATCH\_SIZE = 8
IMG\_WIDTH = 256
IMG\_HEIGHT = 256
@@ -69,6 +74,9 @@
align\_corners=True, method=2)
real\_image = tf.image.resize\_images(real\_image, size=[IMG\_HEIGHT, IMG\_WIDTH],
align\_corners=True, method=2)
+ stacked\_image = tf.stack([input\_image, real\_image], axis=0)
+ reshape\_image = tf.reshape(stacked\_image, [2, IMG\_HEIGHT, IMG\_WIDTH, 3])
+ input\_image, real\_image = reshape\_image[0], reshape\_image[1]
@@ -101,10 +109,11 @@
def \_\_init\_\_(self):
pass
- def model\_fn(self, features, labels, mode):
- input\_img = tf.reshape(features, [-1, 256, 256, 3], name='input\_img')
+ def model\_fn(self, features, labels, mode, params):
+ print(params['batch\_size'])
+ input\_img = tf.reshape(features, [params['batch\_size'], 256, 256, 3], name='input\_img')
if mode != tf.estimator.ModeKeys.PREDICT:
- answer\_img = tf.reshape(labels, [-1, 256, 256, 3], name='answer\_img')
+ answer\_img = tf.reshape(labels, [params['batch\_size'], 256, 256, 3], name='answer\_img')
def generator(input\_data):
with tf.variable\_scope('generator'):
@@ -158,7 +167,7 @@
'input': input\_img,
'last\_unet': last\_unet,
}
- return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
+ return tf.contrib.tpu.TPUEstimatorSpec(mode=mode, predictions=predictions)
EPS = 1e-12
last\_unet = generator(input\_img)
@@ -177,40 +186,50 @@
optm\_d = tf.train.AdamOptimizer(learning\_rate=0.0005)
optm\_g = tf.train.AdamOptimizer(learning\_rate=0.001)
+ optm\_d = tf.contrib.tpu.CrossShardOptimizer(optm\_d)
+ optm\_g = tf.contrib.tpu.CrossShardOptimizer(optm\_g)
+
train\_d = optm\_d.minimize(loss\_d, var\_list=d\_vars, global\_step=tf.train.get\_global\_step())
train\_g = optm\_g.minimize(loss\_g, var\_list=g\_vars, global\_step=tf.train.get\_global\_step())
tf\_group = tf.group([train\_d, train\_g])
- return tf.estimator.EstimatorSpec(mode=mode, train\_op=tf\_group, loss=loss)
+ return tf.contrib.tpu.TPUEstimatorSpec(mode=mode, train\_op=tf\_group, loss=loss)
-run\_config = tf.estimator.RunConfig(
+tpu\_config = tf.contrib.tpu.TPUConfig(num\_shards=8, iterations\_per\_loop=1)
+
+run\_config = tf.contrib.tpu.RunConfig(
save\_checkpoints\_steps=100,
save\_summary\_steps=100,
- model\_dir=MODEL\_DIR)
+ master=TF\_MASTER,
+ model\_dir=MODEL\_DIR,
+ tpu\_config=tpu\_config)
p = Pix2pix()
-estimator = tf.estimator.Estimator(
+estimator = tf.contrib.tpu.TPUEstimator(
+ use\_tpu=True,
model\_fn=p.model\_fn,
+ train\_batch\_size=TRAIN\_BATCH\_SIZE,
+ predict\_batch\_size=TEST\_BATCH\_SIZE,
config=run\_config
)
start = time.time()
estimator.train(
- input\_fn=lambda:train\_input\_fn({'batch\_size': TRAIN\_BATCH\_SIZE}),
+ input\_fn=train\_input\_fn,
max\_steps=100
)
elapsed\_time = time.time() - start
print ("elapsed\_time:{0}".format(elapsed\_time) + "[sec]")
-pred = list(estimator.predict(input\_fn=lambda:test\_input\_fn({'batch\_size': TEST\_BATCH\_SIZE})))
+pred = list(estimator.predict(input\_fn=test\_input\_fn))
解説
基本的にはこう書き換えないと動かなかったなのですが、わかりにくい点を一部解説します
+use\_tpu = True
+
+if 'COLAB\_TPU\_ADDR' in os.environ:
+ TF\_MASTER = 'grpc://{}'.format(os.environ['COLAB\_TPU\_ADDR'])
+
...
+if use\_tpu:
+ assert 'COLAB\_TPU\_ADDR' in os.environ, 'Missing TPU; did you request a TPU in Notebook Settings?'
-tf.test.gpu\_device\_name()
上記はGPUの利用確認をTPUの利用確認に変更しています
なお、TF_MASTERは後ほど使うため、取得しておく必要があります
-TRAIN\_BATCH\_SIZE = 1
-TEST\_BATCH\_SIZE = 1
+TRAIN\_BATCH\_SIZE = 8
+TEST\_BATCH\_SIZE = 8
(Colabの)TPUは8coreあり、8core使用する場合はBatchSizeを8の倍数にしておく必要があるようです
+ stacked\_image = tf.stack([input\_image, real\_image], axis=0)
+ reshape\_image = tf.reshape(stacked\_image, [2, IMG\_HEIGHT, IMG\_WIDTH, 3])
+ input\_image, real\_image = reshape\_image[0], reshape\_image[1]
上記はPredict時に使用するtest_input_fnにおける変更点です
TPUを使う場合はTensorのShapeを明示的に指定してあげないとエラーになるようです
tf.image.resize_images()で終わってしまうと(-1, 256, 256, ?)みたいなShapeになっていて、
この-1や?がダメなんだろうと推察しています
そのため明示的にtf.reshapeでShapeを指定しています
- def model\_fn(self, features, labels, mode):
- input\_img = tf.reshape(features, [-1, 256, 256, 3], name='input\_img')
+ def model\_fn(self, features, labels, mode, params):
+ print(params['batch\_size'])
+ input\_img = tf.reshape(features, [params['batch\_size'], 256, 256, 3], name='input\_img')
if mode != tf.estimator.ModeKeys.PREDICT:
- answer\_img = tf.reshape(labels, [-1, 256, 256, 3], name='answer\_img')
+ answer\_img = tf.reshape(labels, [params['batch\_size'], 256, 256, 3], name='answer\_img')
ここも上述したとおりShapeの指定です
estimator.train(
- input\_fn=lambda:train\_input\_fn({'batch\_size': TRAIN\_BATCH\_SIZE}),
+ input\_fn=train\_input\_fn,
max\_steps=100
)
elapsed\_time = time.time() - start
print ("elapsed\_time:{0}".format(elapsed\_time) + "[sec]")
-pred = list(estimator.predict(input\_fn=lambda:test\_input\_fn({'batch\_size': TEST\_BATCH\_SIZE})))
+pred = list(estimator.predict(input\_fn=test\_input\_fn))
input_fnにlambdaを使って渡すとエラーになったので、使わないで良いような形に変えています。
その他の変更点は、TPUを使う際のお作法的なものかと思います。
その他
- estimator.train()の実行時間は
max_steps=100でGPUが100sec、TPUが130secくらいでした- GPUは
batch_size=1、TPUはbatch_size=8(8shard) - 動かしてみたというレベルなので、おそらく使い方が悪いんだろうなぁと思います。tf.data.Datasetの使い方とかが怪しいと思ってます。
- GPUは
- GPUだとbatch_sizeを大きくしたり、max_stepsを200,300と増やしていくとメモリが足りずにColabが強制終了してしまいました(RAMなのかGPUのメモリなのか不明…)
- その点、TPUのコードでは、
batch_size=64・max_steps=1000にしても問題なく動いています
- その点、TPUのコードでは、
まとめ
- Pix2PixをTPU on Colabで動かすことが出来た
- 処理速度については、現状GPUより遅く、改善の余地があると思っている
- batch_sizeを大きくしたり、step数を大きくしてぶん回すときには使えるかもしれない
- batch_sizeを大きくすることで、性能に悪影響がある可能性はあるため、その点は実験する必要がある
補足:Pix2Pixとは
※詳しくは他にわかりやすくまとめてくださっている方が沢山いらっしゃるので割愛します
ざっくりいうと、最近流行の画像生成技術であるGANの一種で、ある画像から別の画像を作り出す(画像の変換のイメージ)手法です。ペアの画像さえ用意すれば高い性能を発揮する、汎用性に優れたモデルです。
以下、生成された画像例です(Pix2PixプロジェクトHPより)
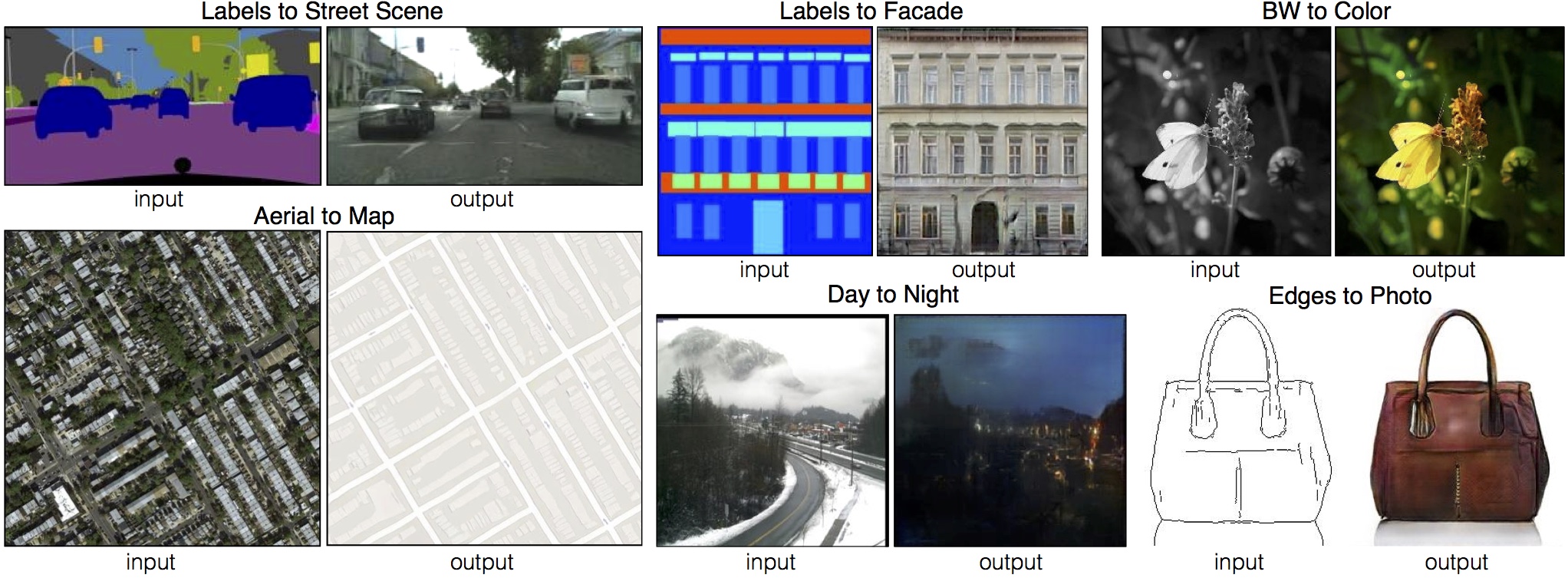
以下、私が理解するときに参考にさせていいただいたサイトです。
– Image-to-Image Translation with Conditional Adversarial Nets – arXivTimes
– pix2pixの紹介 – 株式会社クロスコンパス’s Blog
– 本家論文
あと何気に本実験でも参考にしたTensorFlowのコードが読みやすいので、TensorFlow読める方は何やっているのか理解しやすいと思います。Eager Execution、やっぱりいいですね。
その他参考リンク

shimao
福岡在住。機械学習エンジニア。AWS SAP・MLS。趣味はKaggleで、現在ソロ銀1。福岡でKaggleもくもく会を主催しているので、どなたでもぜひご参加ください。
Related Posts
Yuhei Okazaki
2021/10/27