
Google ColaboratoryのTPUでFashion-MNISTをやってみた
2018/11/08
Table of Contents
こんにちわ、Fusicの嶋生(しまお)と申します。
普段はPythonで機械学習系のお仕事をしたり、AWSでシステム構築したりしています。(PHPも少し書いてます)
今後、機械学習系・AWS系の情報発信をしていきたいと思っております。
今回は表題の件を実験してみた話です。
やったこと
- Google Colaboratory(以下、Colab)でTPUを使って、Fashion-MNISTを学習させてみた
- ついでにCPU・GPU時の実行時間とカンタンに比較してみた。
- 本来ベンチマークを取るべきだと思うのですが、とにかく使ってみたいという気持ち駆動だったので出力する処理時間で比較しました。
経緯
先日ColabでTPUが使えるようになりました!!
GPUが無料で使えるようになった時も驚きましたが、今回も驚きました…。
なんと、TPUが 無料 で使える時代がになりました!
※TPUはGCPで使う場合、通常$4.50 USD(/時間)の費用が掛かる代物です。(プリエンプティブは別額)
ということで、早速何か試してみたいと思ったのが動機です。
実験内容
- ColabのTPU・GPU・CPUでCnnClassificationを動かしてみて、学習の実行速度を比べてみる
実験環境
- Colabのため、割愛します。
- TPU⇔GPU⇔CPUの切り替えについては、こちらのGPUの手順と同じです。
学習データ・学習時パラメータ
- Fashion-MNIST
- 28×28×1チャンネル、60,000枚
- batch_size=1024、epochs=10、steps_per_epoch=100で実験した。
- batch_sizeは環境に応じて変更すべきかと思うのですが、今回は固定で進みました。
実験に使用したコード
Colab公式をそのまま使っています。そんなに量はないので以下に貼ります。
GPU・CPU
import os
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print(len(x_train), len(x_test))
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('elu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
model.compile(optimizer=tf.train.AdamOptimizer(learning_rate=1e-3),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['sparse_categorical_accuracy'])
def train_gen(batch_size):
while True:
offset = np.random.randint(0, x_train.shape[0] - batch_size)
yield x_train[offset:offset+batch_size], y_train[offset:offset + batch_size]
model.fit_generator(
train_gen(1024),
epochs=5,
steps_per_epoch=100,
validation_data=(x_test, y_test),
)
TPU
↑のコードのmodel.compile()の直前に以下のコードを挿入
model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)ここだけ見ると非常にカンタンですね^^
実験結果
結論
当たり前だが、TPU > GPU > CPUの順で早く学習が終わった。
具体的には、1epoch辺りそれぞれ8sec 、23sec、1578secだった。
※上記は全て2epoch目で比較しています。
以下、参考までに環境ごとの結果出力を記載します。
TPU

GPU
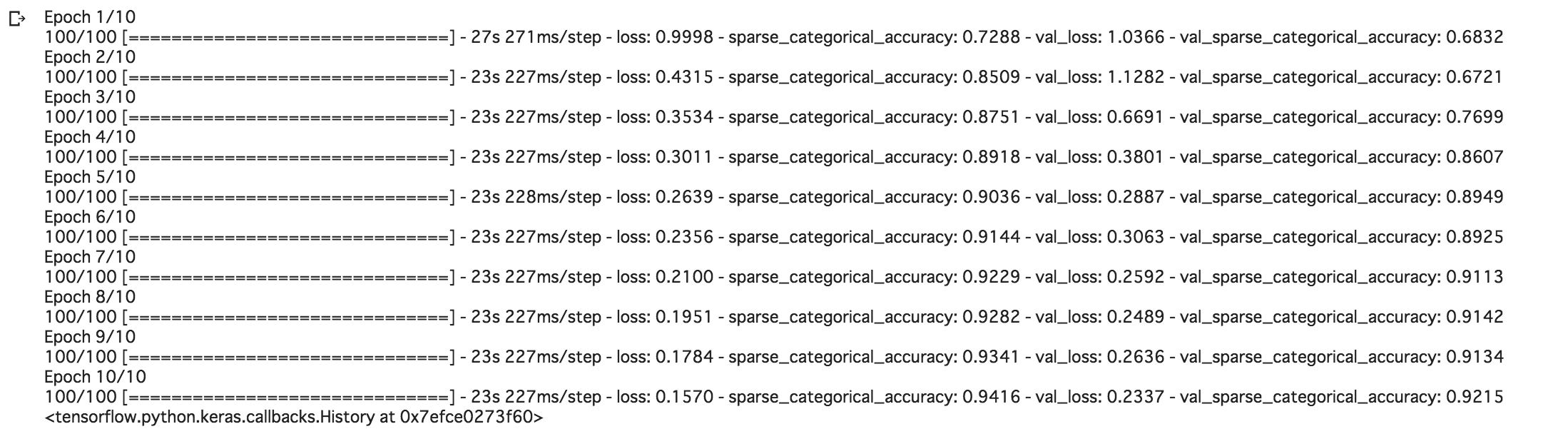
CPU
全然終わらないのでキャプチャは割愛します…
まとめ
- 当たり前なのですが、TPUは早い!
- batch_sizeを適切に変更したり、並列処理を使ったらもっと早くなると思う。
- 効果的なケースにおいては、実案件でも積極的に使いたい。(案件で使用する際は基本GCPになるかと)
- 詳細は後述するが、まだ動かないモデル等があるようなので、アップデート情報にアンテナを貼っておきたい。
Tips:TPUを使おうとしてハマった点
- 実は当初はFashion-MNISTではなく、Pix2Pix(Generativeなモデル)で実験しようとしていました。しかし、実際にやってみた結果、以下の理由で断念しました。
- 現状、Eager ExecutionではTPUは使えない模様
- Estimatorでは使えるが、なぜかmodel_dirにCloudStorageを指定することが必須。
- model_dirの件は我慢してデバッグを進めたのですが、最終的にエラーは出なくなったけど出力も出ない状態になってしまったので諦めました…。もしこの後できたら、公開します。
- tf.kerasを変換する方法(keras_to_tpu_model())であっても、predict()がエラーで動かなかった
- Pix2Pix(GAN)なのでpredict()が動かないと厳しい。
- 公式のノートブックに
Keras/TPU prediction isn't working due to a small bug (fixed in TF 1.12!)と書いてある…。 pip install tensorflow==1.12.0rc0をインストールしてみたが別のエラーが出る。
という感じです。引き続きアップデートを見守りつつ、動くようになったらまた手を出そうとおもいます。
なお、かなり探り探りで調査していたので、上記Tipsに誤りがあるかもしれません。
気になる方はご確認いただけますと幸いです。
参考リンク

shimao
福岡在住。機械学習エンジニア。AWS SAP・MLS。趣味はKaggleで、現在ソロ銀1。福岡でKaggleもくもく会を主催しているので、どなたでもぜひご参加ください。
Related Posts
Teodor TOSHKOV
2022/06/13
Teodor TOSHKOV
2021/09/28
Teodor TOSHKOV
2021/08/24