
Table of Contents
こんにちは、嶋生です。
この記事はFusic Advent Calendar 2018の14日目の記事になります。
昨日は吉野のNuxt + Laravelのプロジェクトのi18n対応でした。フロントエンドとサーバサイドのハイブリッドなi18n対応、面白いですよねー!
さて、以下本題です。
ちなみに自然言語系の領域はまだまだ勉強不足でして、間違っている説明等があるかもしれません🙇
その場合はご指摘いただけると大変助かります。
やったこと
- 公式のBERTを動かしてみる
- 日本語の分類タスクでファインチューニングしてみた
本記事のターゲット
- BERTに興味がある人、日本語タスクでどんな精度が出るのか知りたい人
- 自然言語系の研究に興味がある人
- 実験とか好きな人
BERTって?
少し前にディープラーニング界隈・自然言語界隈で大変話題になった新しいモデルです。
ざっくりいうと、BERTっていうすごい(学習済の)モデルを使えば、色々な自然言語系のタスクを少ない時間で、高い精度が出せるかも!ってことで話題になりました。
2018年10月11日にGoogleから公開されたもので、双方向Transformerで言語モデルを事前学習することで汎用性を獲得し、転移学習させると8個のベンチマークタスクでSOTA(最先端の結果)を達成したそうです。
ちなみに8個のタスクは下図のような感じです。
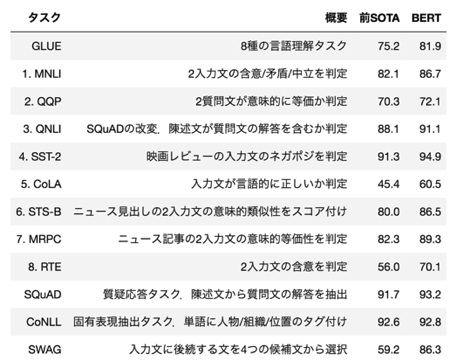
引用元: https://twitter.com/_Ryobot/status/1050925881894400000
まずはサンプルを動かしてみる
GoogleがColabでTPUを使って動かすサンプルを用意してくれているので、これを動かしてみます。
注意点
- GCSのバケットを指定する必要があるのでGCPのアカウントが必要です。
データセット
デフォルトで指定されているMRPCです。
MRPCとは Microsoft Research Paraphrase Corpus の略で、文章の等価性を評価するためのタスクです。要するに2文のペアが同じことを言っているかどうかを判定しているってことみたいですね。コチラの解説がわかりやすかったです。
データ数はファインチューニングに3,668個、評価に408個を使っています。
使用した学習済のモデル
これもデフォルトで指定されているuncased_L-12_H-768_A-12です。
uncased_L-12_H-768_A-12は詳しくは公式の説明を参照していただきたいですが、ようは小さい方のモデル(BaseとLargeがあってBaseの方)で、かつ加工済データ(大文字→小文字変換やアクセントマーカーの除去)を使って学習したモデルのようです。
手順
- 上述したサンプルを自分のGoogleドライブにコピー
- GCSに学習済モデルを配置するためのバケットを作成
- コピーしたノートブックをコピー
これだけです。デフォルトのまま何も変えずに動かしたのですが、体感五分くらいで評価まで行きました。
実際にファインチューニングにかかった時間を出力から抜粋すると、
Started training at 2018-12-14 08:47:22.983040 ...
Finished training at 2018-12-14 08:50:07.751695となんと3分弱です!(TPUを使っているため高速なんだろうなと思ったのですが、GPUを使った記事でも数分程度で完了したとの記述がありました)
結果
評価結果は以下でした。
***** Eval results *****
eval_accuracy = 0.86764705 eval_loss = 0.7126818 global_step = 343 loss = 0.74586976論文に記載されている88.9は下回っていますが、3000強のデータを3分くらい学習させて86%を達成ってめちゃくちゃすごいですよね。
ちなみにBERTの論文によると、BiLSTM+ELMo+Attnの精度が84.9となっているので、このサンプルの時点でELMoの性能を超えていることになります。
BERT半端ない…、転移学習半端ない…!ですね。
日本語タスクでファインチューニングしてみた
次は自分で用意した日本語データでファインチューニングをやってみます。コードは、上記のサンプルを流用しました。
先程のMRPCではなくCoLAのほうが試したいことに近いので、こちらの処理を元にしました。
CoLAはThe Corpus of Linguistic Acceptabilityの略で、与えられた英文が文法的に受け入れられるかどうかを判定(2クラス分類)するタスクです。
データセット
元データとしては、livedoor ニュースコーパスを使用しました。
ダウンロードしたフォルダ内のREADMEに以下のような説明がありました。(一部抜粋)
本コーパスは、NHN Japan株式会社が運営する「livedoor ニュース」のうち、
下記のクリエイティブ・コモンズ ライセンスが適用されるニュース記事を収集し、可能な限りHTMLタグを取り除いて作成したものです。
- トピックニュース
- Sports Watch
- ITライフハック
- 家電チャンネル
- MOVIE ENTER
- 独女通信
- エスマックス
- livedoor HOMME
- Peachy
...
記事ファイルは以下のフォーマットにしたがって作成されています:
1行目:記事のURL 2行目:記事の日付 3行目:記事のタイトル 4行目以降:記事の本文今回はこのデータから記事タイトルだけを抜き出して、記事タイトルから記事のカテゴリを分類するというタスクにしてみます。
CoLAは2クラス分類なのですが、ちょっとだけ変えて3クラス分類にしてみます。
データの中身をチェックする工数は取れないため、できるだけ内容が被って無さそうなスポーツ・映画・ITの3クラスにします。
以下のコードでデータセット(train.tsv, dev.tsv)を作成しました。
import pandas as pd
from pathlib import Path
from sklearn.model_selection import train_test_split
train_file = 'train.tsv'
dev_file = 'dev.tsv'
dataset_df = pd.DataFrame([], columns=['label', 'title'])
category_dirs = ['it-life-hack', 'movie-enter', 'sports-watch']
for index, category in enumerate(category_dirs):
files = Path(category).glob('*.txt')
for file in files:
txt_data = open(str(file), "r")
lines = txt_data.readlines()
dataset_df = dataset_df.append(pd.Series([index, str(lines[2]).replace('【Sports Watch】', '').rstrip()], index=dataset_df.columns), ignore_index=True)
txt_data.close()
train_df, dev_df = train_test_split(dataset_df, test_size=0.2, shuffle=True, stratify=dataset_df.label)
train_df.to_csv(train_file, sep='\t', index=False, header=False)
dev_df.to_csv(dev_file, sep='\t', index=False, header=False)途中【Sports Watch】を削除しているのは、スポーツの記事のタイトルにこの文字列が入っていることに気づいて、分類性能に大きく影響しそうだったためです。
ファインチューニングの学習用のデータが2,114個、評価用のデータが529個になりました。
サンプルコードからの変更部分
以下の部分を作成したデータセットに合わせて修正しました。
import run_classifier
TASK = 'Jp'
BUCKET = '<自分のバケット>'
BERT_MODEL = 'multilingual_L-12_H-768_A-12'
BERT_PRETRAINED_DIR = 'gs://{}/bert/pre_trained/{}'.format(BUCKET, BERT_MODEL)
!gsutil ls $BERT_PRETRAINED_DIR
OUTPUT_DIR = 'gs://{}/bert/models/{}'.format(BUCKET, TASK)
tf.gfile.MakeDirs(OUTPUT_DIR)
print('Model output directory: {}'.format(OUTPUT_DIR))
TASK_DATA_DIR = 'gs://{}/bert/dataset'.format(BUCKET)
!gsutil ls $TASK_DATA_DIR
class JpProcessor(run_classifier.ColaProcessor):
def get_labels(self):
"""See base class."""
return ["0", "1", "2"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
if set_type == "test" and i == 0:
continue
guid = "%s-%s" % (set_type, i)
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[1])
label = "0"
else:
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
run_classifier.InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
...
processors = {
"cola": run_classifier.ColaProcessor,
"mnli": run_classifier.MnliProcessor,
"mrpc": run_classifier.MrpcProcessor,
"jp": JpProcessor, # 追加
}手順
- 作成したデータセットをgcsに上げる
- マルチリンガルなpre_trainedモデルをgcsに上げる
multilingual_L-12_H-768_A-12- 元々のサンプルコードが参照していたgcsにはマルチリンガルモデルはないため、自分であげる必要があります。
- TPUはgcsにおいてあるモデルでないと読み込んでくれません。ローカルに配置しても読み込めません…。
- コードを実行する
以上です。
結果
90.7%程度の正答率になりました!すごい!
***** Eval results *****
eval_accuracy = 0.907197 eval_loss = 0.46347904 global_step = 198 loss = 0.43238112実際に予測された内容を見てみたいですよね。
さくっとestimator.predict()で結果を取得したい所なんですが、実はこのままだとエラーになります。。。
predictするためにはmodel_fn_builder()の一部を書き換える必要があります。以下のような感じで書き換えます。
# 独自の関数にする
def custom_model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate, num_train_steps, num_warmup_steps, use_tpu, use_one_hot_embeddings):
...
def model_fn(features, labels, mode, params):
...
# create_modelをrun_classifierから参照する用に変更
(total_loss, per_example_loss, logits, probabilities) = run_classifier.create_model(
bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
...
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL:
def metric_fn(per_example_loss, label_ids, logits):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(label_ids, predictions)
loss = tf.metrics.mean(per_example_loss)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
eval_metrics = (metric_fn, [per_example_loss, label_ids, logits])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
# mode == tf.estimator.ModeKeys.PREDICTのときのpredictionsがdictでないとTPUではエラーになる
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions={'probabilities': probabilities }, scaffold_fn=scaffold_fn)
return output_spec
return model_fnこれでpredictできるようになりました。
以下の先頭の3行に対して、
ラベル タイトル
1 峰不二子に勝るとも劣らない、スタイル抜群の“イイ女”が映画デビュー
2 試合中、ピンチの場面でダルビッシュが見せた“ある変化”とは?
1 坂本真綾が新たなヒロイン像「あんなに可愛い酔っ払いはいない」予測結果は以下になります。
[5.4155273e-04 9.9806267e-01 1.3957798e-03]
[3.4572129e-04 1.6356092e-03 9.9801862e-01]
[0.00136291 0.9968753 0.00176175]確かに当たってますね!
まぁタイトルに映画とか試合とかヒロインとか入ってるので、簡単すぎるタスクなのかもしれません。
補足
今回Googleが用意しているマルチリンガルな学習済モデルを使いましたが、日本語に関してはあまりよいものではないという話もあります。
こちらのブログの解説がわかりやすかったです。
実際にtokenizeされた文を見てみると
[CLS] 峰 不 二 子 に 勝 ると ##も 劣 らない 、 ス ##タ ##イル 抜 群 の [UNK] イ ##イ 女 [UNK] [UNK] 映 画 [UNK] [SEP][UNK]が複数あったり、スタイルを無駄に分割していたりと改善の余地はかなりありそうです。
とはいえ、個人的には今回の実験結果を受けて、現状でも結構使えるんじゃないかなと思いました。
(もちろんもっと高い精度が実現できるポテンシャルはあると思います)
感想
- 転移学習でBERTを使うのは結構簡単にできた。
- 日本語については改善の余地はありそう。とはいえ、現状でもそこそこの精度は出そう。
- 自然言語難しい…。tokenizeの処理とか正直わかってない。これから転移学習がホットになって、色々な成果が出てきそうだし、ちゃんと勉強していきたい。
- 今回の実験以外の色々なタスクに応用してみたい。要約とかQ&Aとか。
参考にさせていただいたサイト
BERT
- 本家論文
- 汎用言語表現モデルBERTを日本語で動かす(PyTorch)
- 本家リポジトリ
- [DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT使ってみた系

shimao
福岡在住。機械学習エンジニア。AWS SAP・MLS。趣味はKaggleで、現在ソロ銀1。福岡でKaggleもくもく会を主催しているので、どなたでもぜひご参加ください。