
自由気ままに、上下を気にせず取得された画像が襲ってきたら、
皆様ならどのように対応されますか?
画像を一つずつ開き、方向を整えますか?
それとももっとスマートな感じで、いい感じのツールを使って画像の向きを揃えますか?
僕は、今回試しに 機械学習を使って、その方向を整えるのにチャレンジしてみました。
簡単にできるので、是非試してみてください!
今回はデモとして、Pokémon GOのゲーム画面のスクリーンショットを使います。
以下の 例1 や 例2のように、上下バラバラの画像がたくさんあるという想定です。
今回は試しに、41枚の画像(※)を使ってやってみました。
例1
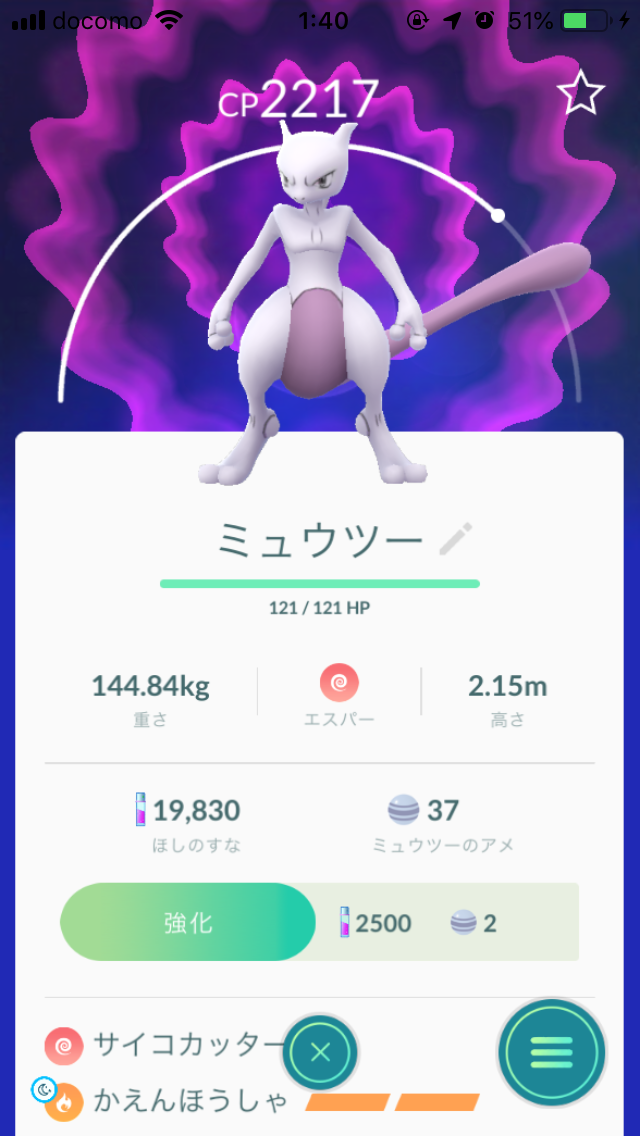
例2
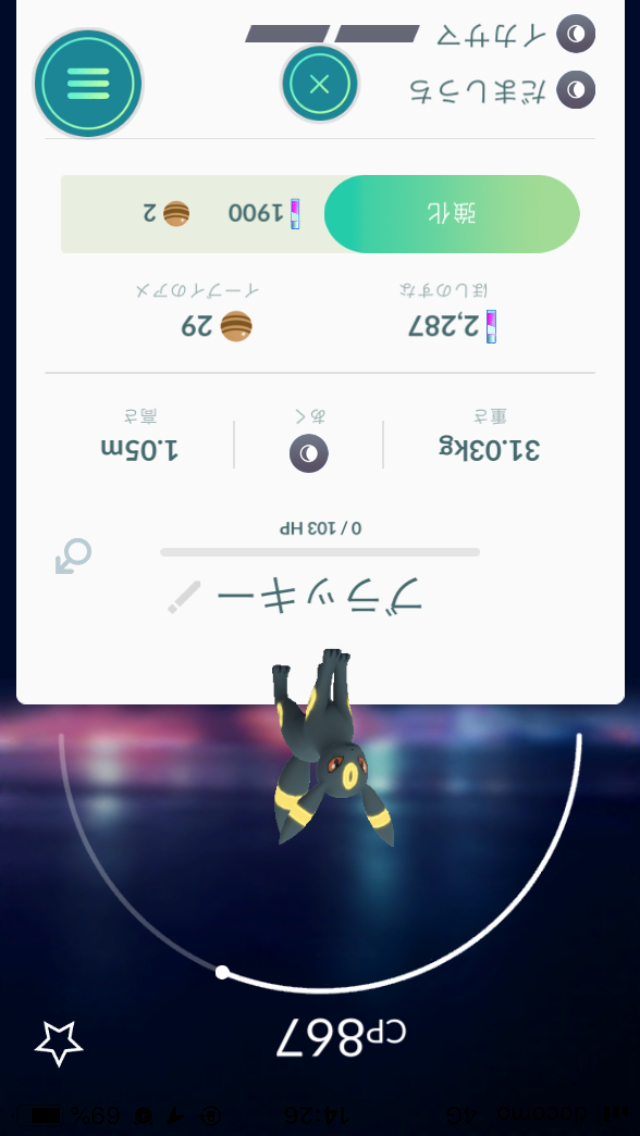
用いた手法は、 k平均法 という手法です。
データセットを与えると、それをいい感じに kクラスに分類してくれます。
今回の場合だと、画像は 上向き、下向きの二種類あるので、 k=2 となります。
ここから、少しだけpython が出てきます。
環境は、 Mac Book Pro 2015 で、Mac 上に起動した jupyter notebook を使っています。
まずは、画像が入っているディレクトリを見てみます。
from pathlib import Path
import numpy as np
pngs = Path('imgs').glob('\*.png')
pngs = np.array(sorted([str(i) for i in pngs]))
len(pngs) #=> 4141枚の画像が存在することがわかりました。
ここからが本番です。
scikit-learn というライブラリからKMeansというモジュールをインポートします。
そして、 n_clusters という引数に k=2 の 2 を与えます。
n_init は、何回学習するか? という引数で、デフォルトは10です。
from sklearn.cluster import KMeans
import cv2
k_means = KMeans(n_clusters=2, n_init=10)
data = []
for file in pngs:
# 画像を読み出して、サイズを変更して、1次元にする
res = cv2.resize(cv2.imread(file), (20, 40)).reshape((-1))
data.append(res)
k_means.fit(np.array(data))これを実行すると、以下のような出力が出てきます。
#=> KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10, n_jobs=None, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)これで、学習は終わりました。
かかった時間は2秒ぐらい。
一瞬です終わります。
その後、
print(k_means.labels_)を実行します。
結果は以下のようになりました。
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]今回のデータセットは、41枚の画像を名前順に並べ、前半20枚を上下反転したものでした。この結果を見ると、きれいに分離できていることがわかります。
ここまでできたら、後は簡単。
k_means.labels_ の結果が 1 になっている画像を反転してあげれば完成です。
for filename in pngs[np.array(k_means.labels_).astype(np.bool)]:
cv2.imwrite(np.rot90(cv2.imread(filename), k=2), filename)これで目的の画像が反転され、すべての画像の向きがそろいます。
ちなみに、反転した画像が k_means.labels_ において 1 と表示されるか 0 と表示されるかはわかりません。
一枚確認した画像を入れてみて、 それがどちらの数字ででてくるのかを調べるのが最も手っ取り早いのですが、
最悪、はずれても、
for filename in pngs:
cv2.imwrite(np.rot90(cv2.imread(filename), k=2), filename)をもう一回実行してあげればすべての画像を反転できるので一件落着です。
ということで、今回は身近な(?)事象に機械学習を適応してみました。
お手軽にできるのでぜひ試してみてください!
※ 今回はとても単純なタスクだったので41枚の画像でうまく結果がでましたが、一般的に機械学習をする際データ数が41個というのは少なすぎて学習をするのは困難です。
Yasuaki Hamano
I'm a software engineer in Fukuoka, Japan. Recently, I am developing machine learning models using TensorFlow, and also developing Web services by using PHP.