
Table of Contents
こんにちは。Fusicインターン生の青木です。この度インターンで画像に対するキャプション及びタグを生成してくれる機械学習モデルを作成しました。 下の画像はサンプル画像の一つです。

この記事ではimage captionについて少し解説したいと思います。
モデル全体の構成
今回は画像処理のモデルに既存の学習済みモデル(VGG-16)を使い、文章生成にattention機構を取り入れたLSTMを使用しました。 attentionについてはわかりやすく説明している記事がありますのでそちらを参照してください。
Encoder(特徴抽出)
#Encoder(VGG-16)
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
vgg = models.vgg16(pretrained=True)
self.features = nn.Sequential(*list(vgg.features)[:31]).eval().to(device)
for param in self.features.parameters():
param.requires_grad = False
self.GAP = (vgg.avgpool).to(device)
self.classifier = nn.Sequential(*list(vgg.classifier)[:1]).eval().to(device)
for param in self.classifier.parameters():
param.requires_grad = False
self.mean = torch.nn.Parameter(torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1), requires_grad=False).to(device)
self.std = torch.nn.Parameter(torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1), requires_grad=False).to(device)
def forward(self, image):
image = (image - self.mean) / self.std
x = self.features(image)
x = self.GAP(x)
x = x.reshape(x.shape[0], -1)
x = self.classifier(x) # output shape(batchSize, 4096)
return x
VGGモデルは学習しないように設定して完全に特徴抽出機としてのみ使います。入力された画像は4069次元の特徴ベクトルにエンコードされます、この特徴ベクトルは次に記すDecoderモデルに送られます。
Decoder(文章生成)
class Decoder(nn.Module):
def __init__(self, vocabSize=VOCAB_SIZE, embeddingDim=EMBEDDING_DIM, hiddenDim=512):
super(Decoder, self).__init__()
self.hiddenDim = hiddenDim
self.word_embeddings = nn.Embedding(vocabSize, embeddingDim)
self.lstm = nn.LSTM(input_size=embeddingDim, hidden_size=hiddenDim, batch_first=True, num_layers=1)
self.decoder = nn.Linear(hiddenDim + 4096, vocabSize)
def forward(self, feature, sentence):
embeds = self.word_embeddings(sentence)
embeds = attention(embeds, embeds, embeds)
feature = feature.repeat(1, sentence.shape[1]).view(sentence.shape[0], -1, 4096)
output, self.hidden = self.lstm(embeds)
output = torch.cat((feature, output), dim=2)
output = self.decoder(output)
return output
def caption(self, feature):
sampled_ids = []
inputs = self.word_embeddings(torch.ones(1, dtype=torch.long).view(1, 1))
feature = feature.unsqueeze(1)
for i in range(MAXIMUM_WORDS):
inputs = attention(inputs, inputs, inputs)
out, states = self.lstm(inputs, None)
out = torch.cat((feature, states[0]), dim=2)
outputs = self.decod(out.squeeze(1))
_, predicted = outputs.max(1)
embed = self.word_embeddings(predicted.view(1, -1))
inputs = torch.cat((inputs, embed), 1)
if predicted.item() == 2:
break
sampled_ids.append(predicted)
sampled_ids = torch.stack(sampled_ids, 1)
return sampled_ids
def attention(q, k, v):
scores = torch.matmul(q, k.transpose(-2, -1))
scores = torch.nn.functional.softmax(scores, dim=-1)
output = torch.matmul(scores, v)
return output
Decoderモデルでの推論は先ほど抽出した特徴と文章の始まりを表す特殊文字"start"が入力されます、特殊文字はLSTMに入力された後に抽出した特徴と結合され全結合層で単語と紐付けされたインデックスとして出力されます。そうして出力された単語はまたLSTMに入力され特徴と結合、出力に終わりを表す特殊文字"end"が出力される、もしくは決められた文字数まで繰り返し文章を生成します。今回はデータセットにSTAIR Captionsを使いました。
実際にいくつかの画像をキャプションしてみた
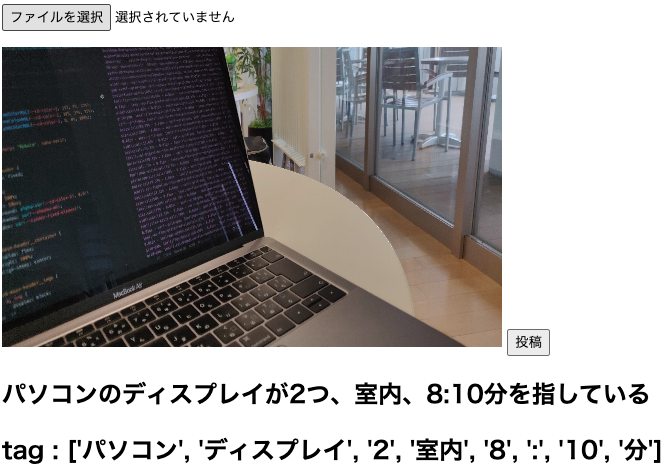

終わりに
今までは画像処理などを主に勉強していましたので、今回初めて自然言語処理を扱うことになりました。自然言語を扱うのは画像とは違うノウハウが必要となり、さらにそれを画像処理と組み合わせるなど、自分自身にとって非常に面白いテーマでした。現状の課題としては画像の特徴抽出で曖昧なところがどうしても出てきてしまい、誤認識があるので、特徴抽出機の改善や変更でキャプションの精度向上の余地があると感じさせる部分もありました。 参考論文 STAIR Captions: 大規模日本語画像キャプションデータセット
aoki masataka
Fusicでインターンをしています。