
Table of Contents
特徴マッチングとは?
特徴マッチングと聞いても、ピンとくる人は少ないでしょう。特徴マッチングを端的に言うと、2枚の画像間で同じ特徴を持つ場所を探索する手法のことです。下の図を見てください。実際に、SuperGlueを用いて特徴マッチングをしてみた結果です。左右の写真は、それぞれ、異なる視点から取りましたが、電車の特徴を上手く、マッチングすることができています。

しかし、このように特徴マッチングをすることで何が嬉しいのか?と疑問に持つことでしょう。例えば、電車の特徴がわかると、左の画像の電車が右の画像の電車に重なるような変換行列を求めることができ、この変換行列を用いることで下図のような重なった画像を得ることができます。これは、パノラマ画像を作る原理と同じです。この処理を複数回行い、いい感じに処理するとパノラマ画像ができます。

しかし、特徴マッチングの重要性は、パノラマ画像を作ることだけではありません。実は、ロボティクスの世界でも、特徴マッチングは重要な手法になります。SuperGlueの論文においても、ロボティクスのストーリの中で、このSuperGlueを語っています。
ロボティクスにおける特徴マッチング
人間は、初めて訪れた町を散歩するとき、周囲の建物や看板など特徴的なものを記憶し、頭の中で、どこを通ったかという地図を作ると思います。しかし、歩いていると、自分の位置は不確かになってきます。一方で、建物や看板を見て、以前通った道を再訪したと気付いたとします。すると、自分の位置の不確かさは小さくなると思います。
自律ロボットや自動運転でも同じようなことをSLAM(Simultaneous Localization and Mapping) という手法を用いて実現しています。
理解するには、実際に以下のSLAMの動画をみた方が早いでしょう。動画のリンクを下に貼っています。動画中のように特徴点からなる3D空間を作成しながら、自分の位置を推定することが可能です。
ここでの特徴マッチングに関するキーワードは以下の2つです。
-
特徴点からなる3Dの地図を作るということ
3次元の地図を作るためには、人間の目と同じように物体に対する深度を推定する必要があります。そのためには、左右の目の距離を人が経験的に学習するように、複数の画像の位置関係を明確にする必要があります。この画像間の位置関係を計算するために必要な情報を抽出する手法の一つが、特徴マッチングです。電車の例で変換行列を求めたようなものです。
-
同じ場所を認識すること
SLAMを用いた場合、遠くに移動するにつれ、人間の方向感覚がなくなるように、作成中の地図は初期地点に対する位置関係が不確かになっていきます。しかし、初期地点に戻ることができれば、不確かさを初期化することができます。では、初期地点であると、どのようにして認識するのでしょうか?それは、初期地点にある特徴を認識することです。つまり、初期地点として覚えた画像と特徴がマッチングする画像の場所こそ、同じ場所とすることができます。
このように特徴マッチングは、ロボティクスに欠かせない要素技術の一つです。そして、今年、新しく開発された手法こそSuperGlueです。
SuperGlueの凄さ
Computer Vision 分野における最大級の国際学会である、CVPR(Computer Vision and Pattern Recognition)2020が6月中旬に開催されました。そこでは、様々なコンテストも開かれています。その中でも、個人的に一番興味深かったのが、屋内/屋外におけるlocalization challengeです。端的に言えば、単眼カメラで撮った動画からカメラ位置/姿勢の推定精度を競うSLAMの大会です。この大会で優勝したhlocという手法の根幹をなす画像間の特徴マッチング手法が、SuperGlueです。
私としても、OpenCVのk近傍法で特徴量マッチングを行っている中、実環境では精度が出ないと悩むことが多かったので、今回SuperGlueを試してみて、精度の高さに驚きを隠せないです。
やってみた
実際にSuperGlueを試してみました。以下の図を見るとSuperGlueなどの特徴マッチングのイメージがより明瞭になるかと思います。
再掲ですが、電車を近く/遠くで撮った写真に対して、特徴点を抽出し、SuperGlueで、その特徴をマッチングしてみました。画像中の線は、マッチングした特徴点同士をつなげており、赤に近いほどマッチングの信頼度が高いです。ここで驚くべきところは、画像中の物体が大きく変化した場合でも精度良くマッチングしてくれていることです。
次に、照明が異なる場面でも試してみました。左は照明を消した場合、右は照明をつけた場合です。今回のような条件では、一般的に、単純な色情報のみを考慮した特徴マッチングでは上手くいきません。しかし、下図のように、色ではなく画像中の特徴の幾何構造も踏まえて特徴マッチングできています。本当にすごいです。

理論: SuperGlueとは?
2つの局所特徴量の集合の相関関係を踏まえて、マッチングさせるニューラルネットワークのことです。
何が凄いのか?
特徴点を別画像の特徴点に割り当てる際に、自然言語処理で良く用いられるAttention機構を含むグラフニューラルネットワーク(GNN)を導入したことで、特徴量の色特性だけでなく、画像間の幾何学的な変化や3D空間上の規則性に関する情報も踏まえてマッチングしていることが凄いです。 結果として、今まで課題であった、大きな視点変化、照明の変化、オクルージョン、画像のボケ、テクスチャの欠如といった場面で、大きな成果を上げています。 他の手法と比較した場合も、屋内外の厳しい実環境化での姿勢推定(特徴マッチングの結果から計算される)において、SOTAを得ることができています。
また、CVPR 2020のコンペティションでも使用されているように、最新の自己位置推定のシステム(Simultaneous localization and mapping; SLAM など)に容易に統合できることも大きな利点になります。
どこで使われているのか?
古典的な特徴点マッチングは、以下のような流れで行われます。
- 画像中の特徴となる重要な点を検出
- 特徴の抽出
- 最近傍探索により特徴をマッチング
- 不適当なマッチングをフィルタリング(RANSACなど)
- 幾何的な変換を推定, 後処理
このパイプラインは、OpenCVのチュートリアルにのっており、簡単に実装可能です。
1, 2における特徴の抽出は、Scale-Invariant Feature Transform (SIFT) 特徴量や、ニューラルネットワークを用いたSuperPointなどの手法により行われます。 SuperGlueによる特徴マッチングは、3, 4に相当します。 5以降の部分に相当する処理は、特徴マッチングの結果を用い、画像間の変換行列の推定や、カメラの位置姿勢推定、さらには、バンドル調整などの最適化手法によるグローバルな特徴群の最適化が行われます。
SuperGlue アーキテクチャ
論文中Fig.2. の以下の図に沿って、SuperGlueのアーキテクチャを説明します。
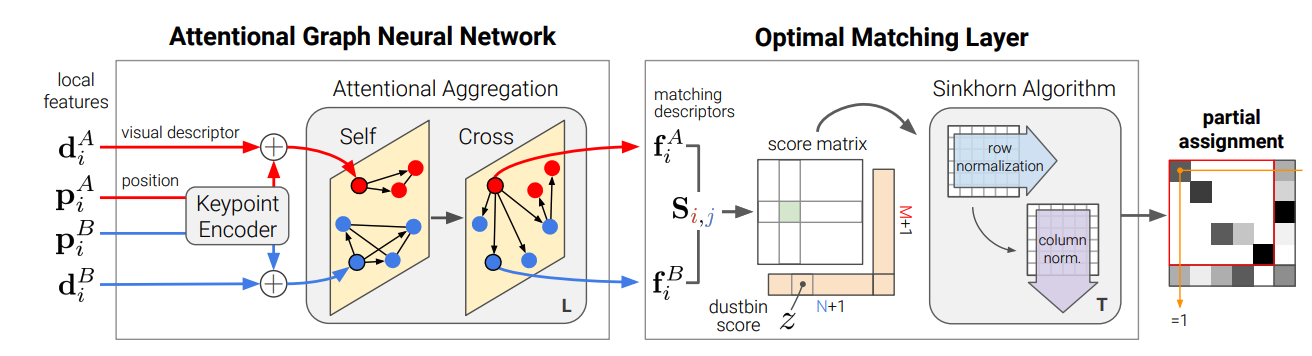
画像, を入力とします。特徴抽出は、SuperPointのようなCNN、または、SIFTのような古典的な特徴抽出手法を用いることができます。結果として、画像はM, 画像はN個の特徴を抽出したとします。 , は、抽出した特徴情報で、, は、特徴の位置を示しています。このアーキテクチャのゴールは、図の右端にある、部分割り当て問題を解くことです。左からフローに沿って説明していきます。
Attention Graph Neural Network
特徴の位置と視覚的な外観以外にも、顕著性がある特徴や、隣接している特徴など画像内の特徴同士の関係性を統合することで、特徴の識別性を高めることができます。また、人間が両方の画像を何度も見返して、曖昧な特徴を一致させていくように、2枚の画像の特徴を比較することで曖昧性も解消できます。
これらを図で表すと、以下の図(論文中Fig.3)のような繋がりを獲得したいことになります。図中のSelf-Attentionにおいては、同じ図中の特徴同士の関連度を表現し、Cross-Attentionにおいては、異なる図における特徴の関連度を表現しています。これを、実現するのが、Attentionを用いたグラフニューラルネットワークになります。

Keypoint Encoder
これらを実現するため、まず、画像, の特徴は、Keypoint Encoderにより、ある次元のベクトルに埋め込むこまれます。これは、自然言語処理のPositional Encoderのようなもので、特徴に対する埋め込みは、 で表現されます。は多層パーセプトロンのことです。
グラフニューラルネットワーク
その後、特徴の埋め込み表現をGNNに入力します。GNNを定式化すると、以下のようになります。
, をそれぞれ、同じ画像内の特徴に対する無指向エッジ(self-edge), 他の画像内の特徴に対する無指向エッジ(cross-edge)とします。エッジは、 シンプルに繋がりと考えてください。無指向は、繋がりが一方通行ではないということです。
で表現される全てのエッジを特徴に集約する接続子をとします。すると、GNNの中間表現は、以下で表すことができます。
は接続子で表現されたに対する接続を表しています。画像Bに関しても同様に表現されます。この接続は、Query , Key , Value を用いて、以下の式で表されます。
はattention重みです。Query, Key, Valueは、それぞれ、GNNにおける高次元な特徴の線形射影として計算され、例えば、画像QにおけるQueryを考えると、となり、Key, Valueに関しても同じような式で与えられます。この時、Self-edgeの場合、Key, Query, Valueは、同じ画像における特徴を用い、Cross-edgeの場合、Key, ValueをQueryとは異なる画像における特徴を用います。
最終層は、それぞれの特徴におけるマッチングの度合いを表現する必要があり、の線形射影となります。
GNNは、から開始し、が奇数の時、で、が偶数の時、となります。つまり、同じ画像内の特徴同士の関連度の集約と、異なる画像間の特徴同士の関連度の集約を交互に行っています。
Optimal Matching Layer
アーキテクチャの右側の処理です。スコア行列は、GNNの結果を用いて、の内積で求められます。 スコア行列を用いて、を最大にする割り当て行列を取得することが最終目標です。
ここでは、明示的に、マッチングしなかった特徴を割り当てるためのゴミ箱用のビン(dustbin)を追加しています。拡張したスコア行列は、のように行、列にそれぞれ一行追加された形で表現されています。
上記の形で、割り当て問題をときますが、、データに順序がないため、NP困難であり、計算コストが高いです。そこで、この問題を近似して効率的にとく手法として、Sinkhorn アルゴリズムを用います。
以下、難しいので、飛ばした方が良いかもしれませんが、一応、説明しますと、、、
Sinkhorn アルゴリズムは、以下のWasserstein距離を近似するアルゴリズムです。 Wasserstein距離は、一般的には確率密度間の距離関数を定めるものです。 この距離を最小化することで、各点群は異なる数の点からなるものとし、K 個の点群を含む点群データベース を考えたときの、ある点群 に対する, 中,最も と類似した点群を見つける問題を解くことができます。
損失
設計上、グラフニューラルネットワークと最適マッチング層の両方が微分可能であるため、マッチから視覚的記述子へのバックプロパゲーションが可能とのことでした。 Ground Truthが で与えらたとします。 また、不適当なマッチングを行うデータを, で与えられるとします。 損失は、以下の式で書くことができます。この式を最小化するようにグラフニューラルネットワークのパラメータを学習させています。
最後に
最初は、GNNに興味があり、この論文を読み初めましたが、GNNだけではなく、SLAMなど多くの知見を得ることができる良い論文でした。最近、画像処理を行うことが多く、使う時がいつかくるかなとも思います。実際にコードを試したみましたが、実時間でなくても良いならば、CPUでも問題なく動きました。
とても良い手法なので、気になる人は、じっくり論文を読んでみてください。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps
Related Posts
Kai Washizaki
2020/08/17