
[論文読み]Learning to Cartoonize Using White-box Cartoon Representations - 写真をイラスト化するAI
2020/08/17
こんにちは、鷲崎です。Computer Vision 分野における最大級の国際学会である、CVPR(Computer Vision and Pattern Recognition)2020が6月中旬に開催されました。個人的には、教師なし学習分野の論文が増えた気がしています。
本記事では、CVPR2020の論文の中でも、趣味のイラスト作成に使えそうな写真のイラスト表現化に関する論文 Learning to Cartoonize Using White-box Cartoon Representations を読んでみました。
論文の目的
この論文のゴールは、写真を新海誠先生の「君の名は」のような漫画表現に変換することです。
例としては、コードのREADMEに挙げられたいた以下の写真があります。左が、元の写真で、右がイラスト表現に変換したものです。分かりにくいかもしれませんが、右上の画像など、ジブリっぽい画像になっていて、そのままアニメで使えそうなレベルです。

やってみた
実際に、自前の写真に対しても、イラスト化をやってみました。昔タイに行った時の写真ですが、写真右上の背景などは、上手くできている気がします。一方で、蛇の顔や私の顔が首と同化しており、コンテンツを明確に理解して変換しているわけではなさそうです。

理論
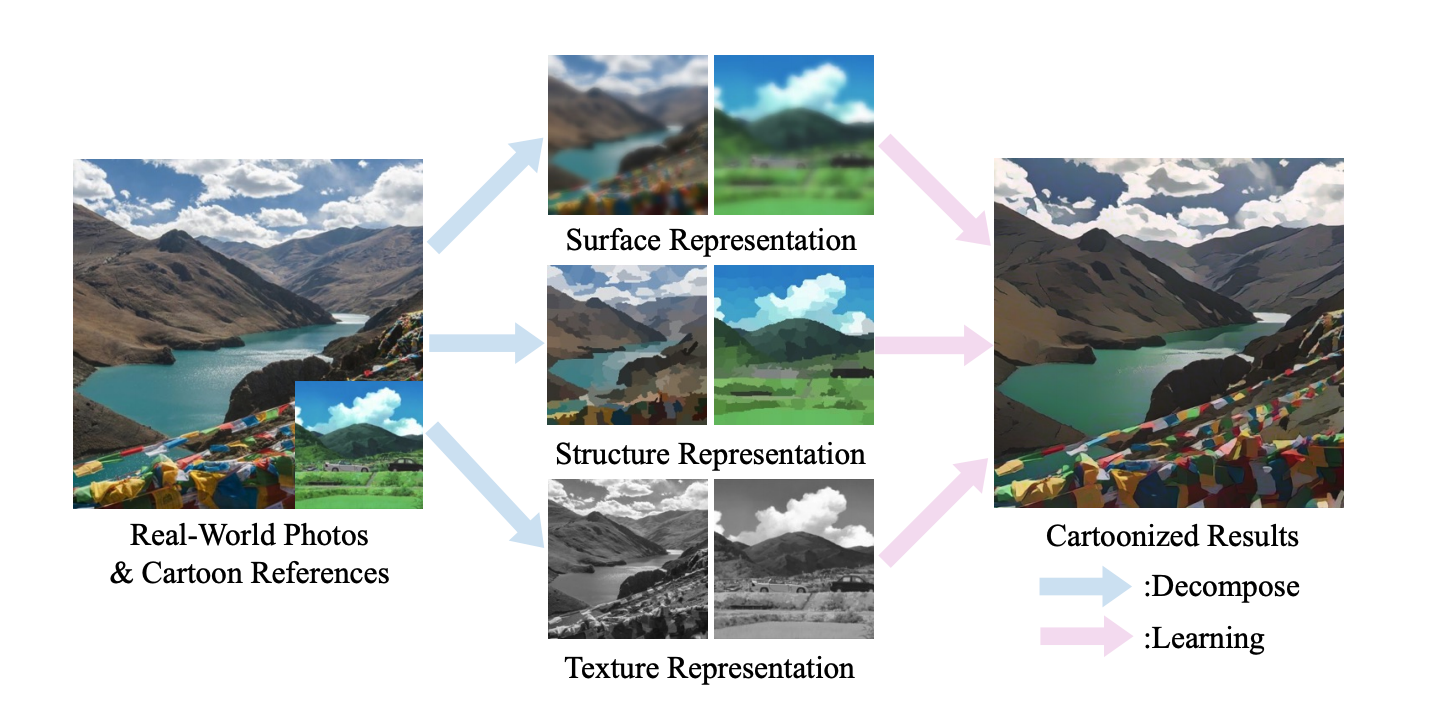
論文の詳細を説明していきます。提案手法では、イラスト表現を分析し、イラストの表現を以下の3つに分割できるとしています。
-
Surface 表現
アニメののっぺりとした平滑面を表現しており、色や物体のエッジ、テクスチャー、ディテールを無視したものになっています。
-
Structure 表現
画像中の物の配置など、大まかな構造情報を捉えた表現であり、色によるセグメンテーションを行なうこと、色同士の境界線と疎な色の塊で表されています。
-
Texture 表現
画像中物体の詳細な形や境界を捉えた表現であり、色や輝度の情報をあえて落としています。
イラスト表現がこれらの3つで構成されていると、明示的(White-Box)に指定して学習できることが手法の特徴です。これらの表現に関しては、論文Fig.2. の中央に例が挙げられています。
これらの個別に抽出された表現の学習と画像のイラスト化には、GAN(Generative Adversarial Network)が用いられています。GANフレームワークの中で、生成した画像から各表現を抽出し、それぞれの表現画像に対する損失を設計したことが、この論文の面白いところです。
詳しく述べると、これらの表現は、GANの生成器により生成された画像に対して、それぞれ適当な手法で変換することで抽出しています。これは、分類器の手前で行われます。その後、分類器の結果より、Surface表現に関する損失、Structure表現に関する損失、Texture表現に関する損失を計算し、その合計を小さくするように学習を行っています。
表現の抽出
ここでは、各表現の抽出方法に関して説明します。
-
Surface表現
この表現の変換手法として、diggerentiable guided filterが提案されています。Guided filterとは、エッジ情報を残しつつ平滑化処理を行うBilateralフィルタに加え、ガイド画像との色の類似性を考慮したものです。 論文内では、学習時に、ガイド画像として、フィルタをかける対象画像と同じ画像を入力しています。
-
Structure 表現
この表現への変換は、superpixelアルゴリズムを適用し、距離・色が近い画素をひとまとめにした画像にしています。しかし、標準的なsuperpixelアルゴリズムは、単純にピクセル同士の類似性にのみ着目しているので、Selective Searchでさらに、領域ごとの類似性に基づきグルーピングしています。この流れは、物体検出アルゴリズムであるR-CNNに使われていることで有名です。
-
Texture 表現
この表現の変換手法として、Random color shift アルゴリズムが提案されています。この手法は、端的に言えば、RGB画像から変換したグレースケール画像に対してランダムな割合でRGB値を加えるというものです。
これらの処理は、GANの分類器にかける前処理のような形で行われます。 学習時には、GANの生成器や分類器の部分だけでなく、上記のGuided filterに使用しているモデルも同時に学習している点に注目したいです。また、生成器により生成された画像に対して、入力写真をガイドとして用いたGuided filterを用いることで、輪郭の強調具合を調整し、スタイル補正を行うことが可能になっています。そのため、実用時には、生成器により推論した画像に対して、Guided filterによる後処理を行っています。
評価
評価指標が、珍しい指標だったので簡単にまとめます。
評価には、Frechet Inception Distance (FID)が用いられていました。FIDは、元画像と対象画像の分布間の距離を測っています。画像処理タスクのベースモデルによく使用されるinceptionモデルの最後のpooling層から得られる特徴ベクトルが多変量正規分布に従うと仮定し、元画像と対象画像の分布間の距離をFrechet距離により求めています。
論文で提案している手法は、FIDが他の手法より優れていました。論文Fig.9.の以下の図の結果を見ても明らかだと思います。一番右の結果が、論文の手法です。個人的には、もっと輪郭が明確になれば最高だと思います。

まとめ
GANの学習は、ハイパーパラメータ調整と損失関数の設計が命なので、ここまで辿り着くのが、とても大変だったんだろうと、想像しながら読みました。コードも公開されており、tensorflowの1系だったので少し躊躇しましたが、モデルの構成がわかりやすく、実装しやすいということも、このGAN系のモデルの利点だなと、あらためて感じました。
Kai Washizaki
Conpany: Fusic Co., Ltd. Program Language: Python, Go, PHP Interest: Machine Learning, MLOps